爬虫学习笔记14-scrapy中间件的使用
1、中间件的作用:预处理request和response对象
① 对header以及cookie进行更换和处理
②使用代理ip等
③对请求进行定制化操作
注:在scrapy默认的情况下
两种中间件都在middlewares.py一个文件;爬虫中间件使用方法和下载中间件相同,且功能重复,通常使用下载中间件
2、中间件的使用方法
(1)在middlewares.py文件中定义中间件类
(2)在中间件中重写处理请求或者响应的方法
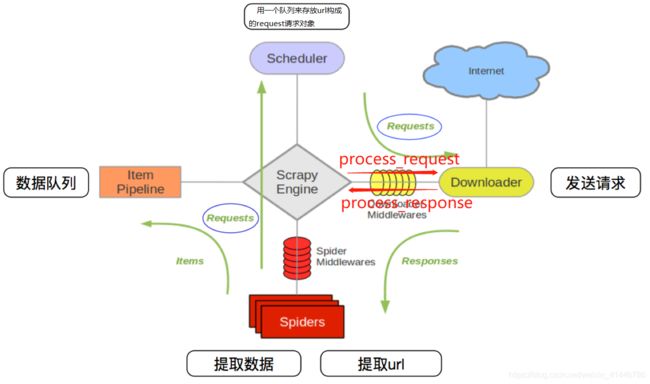
1)process_request(self, request, spider):当每个request通过下载中间件时,该方法被调用;
①返回None:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
②返回Response对象:不再请求,把response返回给引擎
③返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
2)process_response(self, request, response, spider):当下载器完成http请求,传递响应给引擎的时候调用
①返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
②返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
(3)在settings.py中配置开启中间件,权重值越小越优先执行
3、定义实现随机User-Agent的下载中间件
通过爬取豆瓣作为案例分析
- 创建一个项目:
scrapy startproject Douban - 数据建模:items
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 电影名字
info = scrapy.Field() # 主演
score = scrapy.Field() # 评分
desc = scrapy.Field() # 评价
- 设置settings
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
# ROBOTSTXT_OBEY = True
- 创建一个爬虫:
scrapy genspider movie douban.com
import scrapy
from Douban.items import DoubanItem
class MovieSpider(scrapy.Spider):
name = 'movie'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
el_list = response.xpath("//*[@class='info']")
# print(len(el_list))
for el in el_list:
item = DoubanItem()
item['name'] = el.xpath('./div[1]/a/span[1]/text()').extract_first()
yield item
print(item)
url = response.xpath("//span[@class='next']/a/@href").extract_first()
if url != None:
url = response.urljoin(url)
yield scrapy.Request(url=url)
- 使用中间件实现随机User-Agent
请求头获取方法:
- 搜集各种User-Agent构建请求头,写一个随机函数,每次挑选一个User-Agent
- 使用fake_useragent
(1)下载该库:pip install fake-useragent -i https://pypi.douban.com/simple/
(2)导入该库,查看是否安装成功:import fake_useragent
(3)随机生成
(4)生成特定浏览器的请求头




(1)在settings文件中建一个UserAgent列表,利用fake_useragent库生成50个随机请求头
from fake_useragent import UserAgent
USER_AGENT_LIST = []
for i in range(50):
USER_AGENT_LIST.append(UserAgent().random)
(2)在middlewares.py文件中导入UserAgent列表
import random
from Douban.settings import USER_AGENT_LIST
class RandomUserAgent(object):
def process_request(self, request, spider):
ua = random.choice(USER_AGENT_LIST)
request.headers['User-Agent'] = ua
(3)在settings.py中配置开启中间件,权重值越小越优先执行
DOWNLOADER_MIDDLEWARES = {
# 'Douban.middlewares.DoubanDownloaderMiddleware': 543,
'Douban.middlewares.RandomUserAgent': 543,
}
4、代理ip的使用
(1)在settings文件中建一个代理ip列表,通过代理网站添加一些代理
代理分成两种:免费代理没有账户密码认证,经常不能使用,另外的就是需要充钱的代理具备账户密码认证
PROXY_LIST =[
#有密码
{
"ip_port": "123.207.53.84:16816", "user_passwd": "morganna_mode_g:ggc22qxp"},
#无密码
{
"ip_port": "122.234.206.43:9000"},
]
(2)在middlewares.py文件中导入代理ip列表
import base64
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXY_LIST)
print(proxy)
if 'user_passwd' in proxy:
# 对账号密码进行编码,python3中base64编码的数据必须是bytes类型,所以需要encode
b64_up = base64.b64encode(proxy['user_passwd'].encode())
# 设置认证
request.headers['Proxy-Authorization'] = 'Basic ' + b64_up.decode()
# 设置代理
request.meta['proxy'] = proxy['ip_port']
else:
# 设置代理
request.meta['proxy'] = proxy['ip_port']
(3)在settings.py中配置开启中间件
DOWNLOADER_MIDDLEWARES = {
# 'Douban.middlewares.MyCustomDownloaderMiddleware': 543,
# 'Douban.middlewares.RandomUserAgent': 543,
'Douban.middlewares.RandomProxy': 543,
}
5、selenium动态加载
原因:当页面没完全加载出来的时候,数据不能完整获取到
目的:将selenium作为中间件加载出完整的页面以后在进行解析
from selenium import webdriver
import time
from scrapy.http import HtmlResponse
from scrapy import signals
class SeleniumMiddleware(object):
def process_request(self, request, spider):
url = request.url
# 判断加载过慢的页面url
if 'daydata' in url:
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
data = driver.page_source
driver.close()
# 创建响应对象
res = HtmlResponse(url=url, body=data, encoding='utf-8', request=request)
return res