数据分析案例1.0——药品销售分析
药品销售分析
- 前言
- 数据获取
- 数据清洗
-
- 选择子集
- 列名重命名
- 缺失数据处理
- 数据类型转换
- 数据排序
- 异常值处理
- 构建模型
-
- 业务指标1:月均消费次数
- 业务指标2:月均消费金额
- 业务指标3:客单价
- 数据可视化
-
- 消费趋势分析
-
- 分析每天的消费金额
- 分析每月的消费金额
- 分析药品销售情况
- 小结
前言
- 原始数据:朝阳医院2018年销售数据.xlsx
- 业务指标:月均消费次数、月均消费金额、客单价、消费趋势
- 分析过程:获取–清洗–建模–分析–可视化
数据获取
- 导入相关包
#导入库
import numpy as np
from pandas import Series,DataFrame
import pandas as pd
import matplotlib.pyplot as plt #数据可视化会用到
import matplotlib
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 这里你也可以使用其他字体,如SimHei,是黑体的意思。作用:正确显示中文
- 读取数据
读取的时候用object读取,防止有些数据读不了
#导入数据
xls = pd.ExcelFile('朝阳医院2018年销售数据.xlsx')
df = xls.parse('Sheet1',dtype='object')#得到数据框
df.head()#看前5行数据

3. 查看基本信息
#查看数据几行几列
print(df.shape)
#查看索引
print(df.index)
#查看每一列的列表头内容
print(df.columns)
#查看每一列数据统计数目
print(df.count())

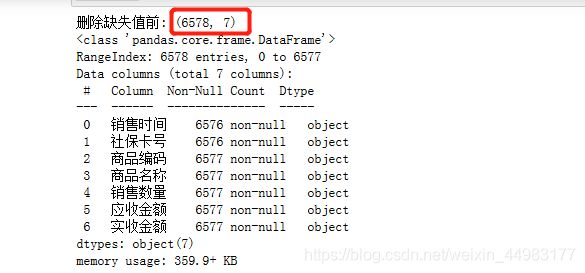
总共有6578行7列数据
“购药时间”和“社保卡号”这两列:6576个数据
“商品编码”一直到“实收金额”:6577个数据
推断出“购药时间”和“社保卡号”存在一行缺失值
数据清洗
过程:选择子集、列名重命名、缺失数据处理、数据类型转换、数据排序、异常值处理
选择子集
获取到的数据数据量非常庞大时使用,本次案例忽略这一步。
列名重命名
- 适用场景:当某些列名和数据容易混淆或产生歧义时,需要把列名换成容易理解的名称
- 函数实现:rename()函数
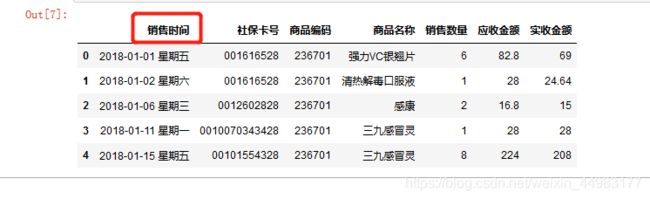
#列重命名
df.rename(columns={
'购药时间':'销售时间'},inplace=True)#把'购药时间'重命名为'销售时间'
df.head()
缺失数据处理
如果不处理缺失值会干扰后面的数据分析结果。
- 常用的处理方式
(1)删除含有缺失数据的记录(本次案例选择该方法)
函数实现:dropna()函数
(2)利用算法去补全缺失数据。(下次的金融数据分析案例使用该方法)
#缺失值处理
print('删除缺失值前:', df.shape)
df.info()
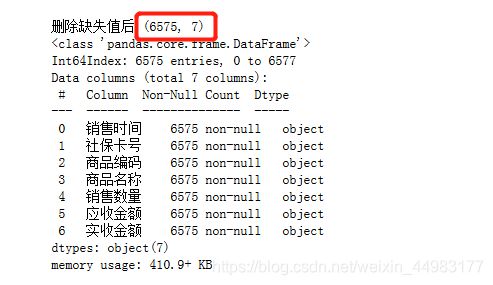
#删除缺失值
df = df.dropna(subset=['销售时间','社保卡号'], how='any')
print('\n删除缺失值后',df.shape)
df.info()
数据类型转换
防止数据导入不进来,会强制所有数据都是object类型。
但实际数据分析过程中“销售数量”,“应收金额”,“实收金额”,这些列需要浮点型(float)数据,“销售时间”需要改成时间格式
- 函数实现:astype()函数转为浮点型数据
#数据类型转换
df['销售数量'] = df['销售数量'].astype('float')
df['应收金额'] = df['应收金额'].astype('float')
df['实收金额'] = df['实收金额'].astype('float')
df.dtypes

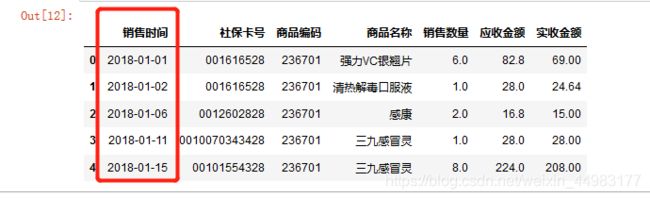
split()函数:把销售时间列中日期和星期进行分割
(注意:分割后的时间,返回的是Series数据类型)
#定义函数将星期除去
def splitSaletime(timeColser):
timelist =[]
for val in timeColser:
data = val.split(' ')[0]
timelist.append(data)
#将列表转为Series类型
timeSer = Series(timelist)
return timeSer
#获取"销售时间"这一列数据
time = df.loc[:,'销售时间']
#调用函数去除星期,获得日期
data = splitSaletime(time)
#修改"销售时间"这一列的值
df.loc[:,'销售时间'] = data
df.head()
方便后面的数据统计把切割后的日期转为时间格式
方法实现:to_datetime()
#字符串转日期
df.loc[:,'销售时间'] = pd.to_datetime(df.loc[:,'销售时间'], format='%Y-%m-%d', errors='coerce')#注意,Y一定要大写
df.dtypes
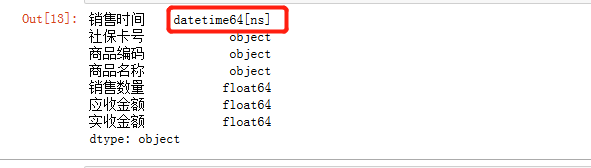
(一开始,在这一步的时候,我不小心写成了小写y,结果把所有的日期都是NaT,导致最后删除不符合格式的时候,得到一个值空的数据框)
#在日期转换过程中不符合日期格式的会转换为空值,这里需要删除
df = df.dropna(subset=['销售时间','社保卡号'], how='any')
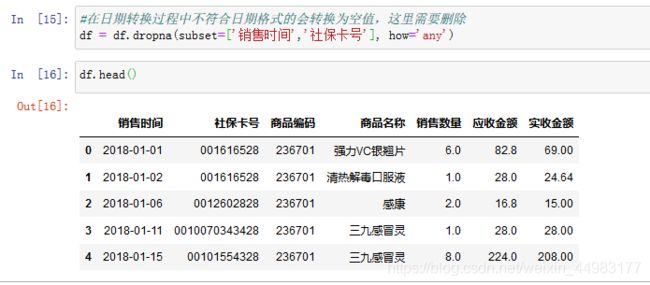
数据排序
上述步骤得到的时间是没有按顺序排列的,需要排序
(注意排序之后索引会被打乱,需要重置一下索引。)
#数据排序
df = df.sort_values(by='销售时间', ascending=True)#其中by:表示按哪一列进行排序,ascending=True表示升序排列,ascending=False表示降序排列。
df = df.reset_index(drop=True)#重置索引
df.head()
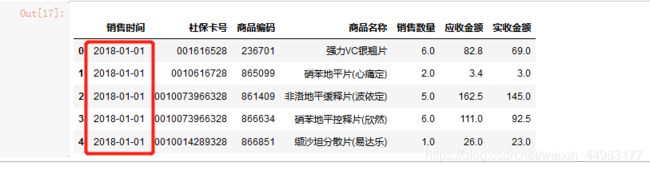
异常值处理
先查看数据的描述统计信息
#查看描述统计信息
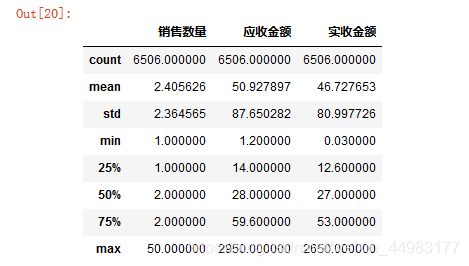
df.describe()
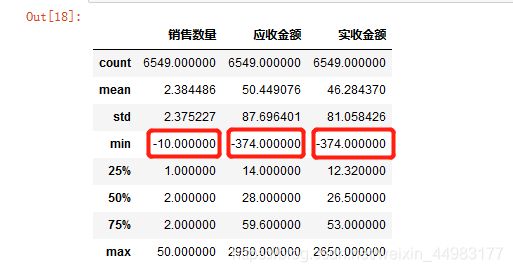
“销售数量”、“应收金额”、“实收金额”的最小值出现了负数,不符合常理。
说明存在异常值的干扰,需要排除异常值的影响。
#将'销售数量'这一列小于0的数据排除掉
pop = df.loc[:,'销售数量'] > 0
df = df.loc[pop,:]
df.describe()
构建模型
数据清洗完成后,需要利用数据构建模型(就是计算相应的业务指标)
业务指标1:月均消费次数
月均消费次数 = 总消费次数 / 月份数(同一天内,同一个人所有消费算作一次消费)
- 计算总消费次数
#计算总消费次数
#删除重复数据
kpil_Df = df.drop_duplicates(subset=['销售时间','社保卡号'])
totalI = kpil_Df.shape[0]
print('总消费次数=',totalI)
总消费次数= 5342
2. 计算月份数
#计算月份数
#按销售时间升序排序
kpil_Df = kpil_Df.sort_values(by='销售时间', ascending=True)
#重命名行名
kpil_Df = kpil_Df.reset_index(drop=True)
#获取时间范围
startTime = kpil_Df.loc[0,'销售时间']
endTime = kpil_Df.loc[totalI-1,'销售时间']
#计算月份
#天数
daysI = (endTime-startTime).days
mounthI = daysI//30 #向下取整
print('月份数=',mounthI)
月份数= 6
3. 计算月平均消费次数
#月平均消费次数
kpil_I = totalI//mounthI
print('业务指标1:月均消费次数=', kpil_I)
业务指标1:月均消费次数= 890
业务指标2:月均消费金额
月均消费金额 = 总消费金额 / 月份数
#消费总金额
totalMoneyF = df.loc[:,'实收金额'].sum()
mounthMoney = totalMoneyF // mounthI
print('业务指标2:月均消费金额=', mounthMoney)
业务指标2:月均消费金额= 50668.0
业务指标3:客单价
客单价 = 总消费金额 / 总消费次数
#客单价
pc = totalMoneyF / df.shape[0]
print('业务指标3:客单价=', pc)
业务指标3:客单价= 46.727652935751614
数据可视化
消费趋势分析
复制一份数据
#在操作之前先复制一份数据,防止影响清洗后的数据
newdf = df
分析每天的消费金额
将’销售时间’设置为index
#将'销售时间'设置为index
newdf.index = newdf['销售时间']
newdf.head()
分组
#分组
nb = newdf.groupby(newdf.index)
nb
![]()
求和
dayDF = nb.sum()
dayDF
画图
#画图
plt.figure(figsize = (10,6))#可根据需要设置画布的大小
plt.plot(dayDF['实收金额'])
plt.title('按天消费金额')
plt.xlabel('时间')
plt.ylabel('实收金额')
plt.show()
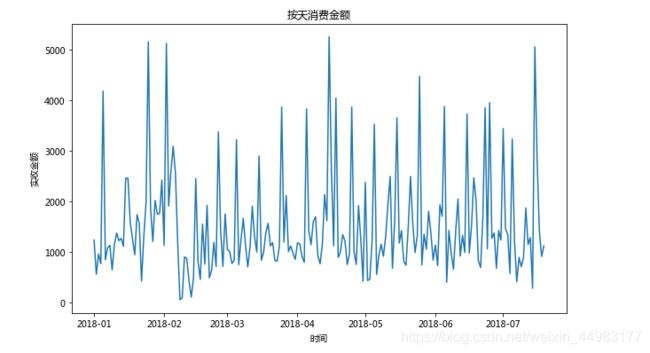
分析:从结果图可以看出,每天消费总额差异较大,除了个别天出现比较大笔的消费,大部分人消费情况维持在1000-2000元以内。
分析每月的消费金额
销售时间先聚合再按月分组进行分析
#将销售时间聚合按月分组
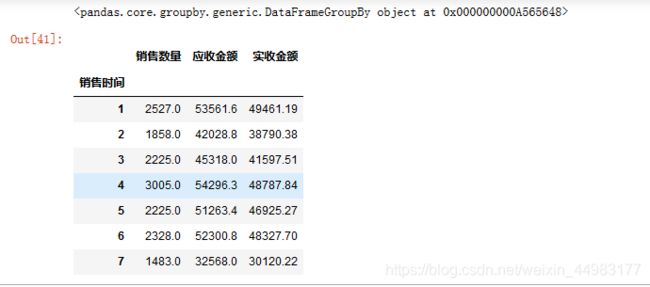
nb = newdf.groupby(newdf.index.month)
print(nb)
monthDF = nb.sum()
monthDF
画图
#画图
plt.figure(figsize = (10,6))#可根据需要设置画布的大小
plt.plot(monthDF['实收金额'])
plt.title('按月消费金额')
plt.xlabel('时间')
plt.ylabel('实收金额')
plt.show()
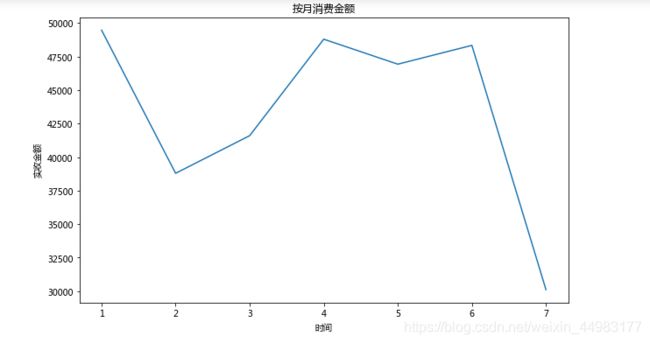
分析:结果图显示,7月消费金额最少,这是因为7月份的数据不完整,所以不具参考价值。
1月、4月、5月和6月的月消费金额差异不大。
2月和3月的消费金额迅速降低,这可能是2月和3月处于春节期间,大部分人都回家过年的原因。
分析药品销售情况
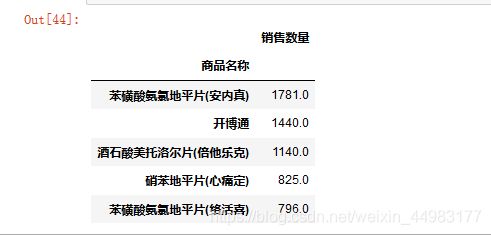
对“商品名称”和“销售数量”这两列数据进行聚合为Series形式,方便后面统计,并按降序排序
#聚合统计各种药品数量
medicine = newdf[['商品名称','销售数量']]
bk = medicine.groupby('商品名称')[['销售数量']]
re_medicine = bk.sum()
#对销售药品数量按降序排序
re_medicine = re_medicine.sort_values(by='销售数量', ascending=False)
re_medicine.head()
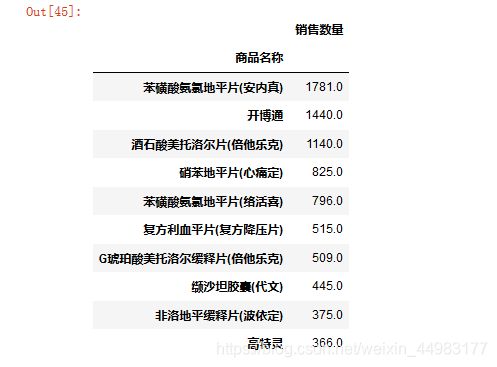
截取销售数量最多的前十种药品
top_medicine = re_medicine.iloc[:10,:]
top_medicine
画图
#条形图
top_medicine.plot(kind='bar')
plt.title('药品销售数量')
plt.xlabel('药品名称')
plt.ylabel('销售数量')
plt.show()
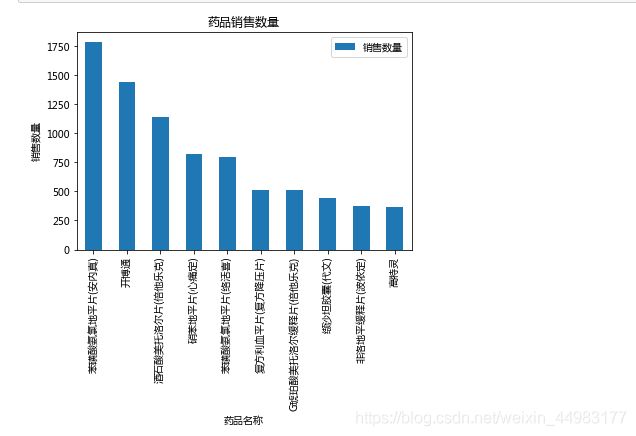
这些药品信息将会有助于加强医院对药房的管理。
小结
数据清洗很重要!
数据集网盘链接:https://pan.baidu.com/s/1F9cbSeKYwUlH7DJ747U1AQ
提取码:5afy