WebSocket长连接因为网络波动而导致客户端的“假离线”---问题发现、分析到解决
文章目录
-
- 简介
- 问题的现象、场景和解决方案
-
- 基本的部署架构
- 问题是什么呢?
- 假离线到底是怎么来的?
- 验证猜想
- 解决问题
- 如何发现问题的呢?
-
- 客户端离线预警
- 奇怪的现象来了
- 该怎么去发现呢
- 到底是谁改的库呢?
- 问题反思
简介
这次分享是在混合云场景下,基于websocket长连接,实现Server-Client(多个)架构模式中,云服务需要维护客户端的状态,但是云端维护的状态可能和实际的客户端的状态不一致,可能就会导致一些奇怪的事情发生,比较有意思的一个问题吧,非常不容易发现的一个问题,必须需要一个合适的契机才可以去发现。前面直接描述问题和解决方案,后面用一定的篇幅详细讲述一下怎么发现的这个问题。
问题的现象、场景和解决方案
基本的部署架构
如下图:
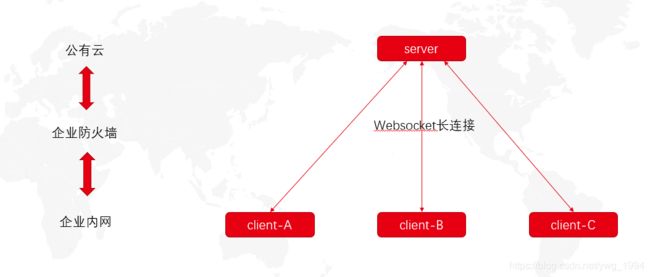
比较简单,但也比较重要,这是看懂本问题以及解决的基本知识,但是仅仅描述和这个问题相关的内容,其它内容不进行扩展:
- 云端部署一个服务,我们称之为server,或者服务端。
- 我们的客户,把我们的客户端部署在自己的企业局域网内部,启动的时候,客户端使用websocket和服务端建立起长连接。
- 连接成功以后,服务端会记录这个客户端为:在线。离线也是如此。后续在云端通过维持的长连接去和客户端进行沟通。
- 为了保持长连接一直畅通,端之间会一直保持心跳(比如5秒),就是发送一个简单的报文,告诉服务端我还活着,同时服务端那边也会维护一个客户端的socket实例,当每个客户端心跳一次的话,服务器会更新这个客户端最后一次心跳时间,而且服务端也会有一个心跳的最大超时时间(以下简称:心跳超时),服务端会有定时任务,每隔心跳超时的时间,去判断上一次心跳时间距离现在是否已经超过了心跳超时,如果超过了,说明客户端已经出异常,强制主动关闭socket,网关记为离线。
- 心跳超时的大小肯定要大于客户端的心跳间隔,但也不能太大,也不能太小;太大会导致可能维护的是一个早都离线的长连接,影响业务;太小会导致比较大数据量的报文传输堵塞通道,短时间内不心跳的话,会被强制关闭。
- 企业內部的网络环境是不太稳定的,客户端与服务端的连接,随时可能断开,所以客户端那边也会有断线自动重连的机制,比如断线后,每隔6秒去尝试重连。
问题是什么呢?
客户端的在线状态特别重要,云端所有的业务操作都将可能依赖于数据库中存储的客户端状态。直接来看,有两种异常:
- 假在线:库里面是在线,实际上客户端是离线的。
- 假离线:库里面是离线,实际上客户端是在线的。
假在线的问题,影响倒不是特别大。
假离线的问题,影响还是蛮严重的,我们现在发现的也是这个问题,同时前人估计也是发现了这个假离线的问题,想了一些办法,在底层的调用逻辑里面,关于这个假离线做了一定程度的容错处理。比如发现是离线的,就实时的通过长连接去判断一次,到底是不是真的离线的话,不是的话,业务照常走,同时自动把数据库状态修复一下。
知道有这么个事情,但是不知道怎么发生的,也更不知道怎么去解决了,提供容错率是最好的解决方案了。这也是解决问题里面非常有效的办法了,从侧面去补偿,要得就是很快解决问题,但不一定是最合理的方案。
假离线到底是怎么来的?
上面说过几个点,再来简述一下:
- 客户端所处环境网络极度不稳定,因为中间的各种网闸代理商会特别多。
- 不稳定,就会断线。
- 只是简单的网络波动的话,6秒就会重连成功。
- 客户端心跳间隔是5秒,服务端心跳超时是30秒。
看着好像没有什么问题?
本来想举个形象的例子,但是网络这块有些事情可能不完全清楚,所以担心举的例子表达偏了,直接结论吧,重点展示3种场景。
- 网络正常情况下。
- 客户端主动关闭应用而断开长连接。
- 客户端因为网络波动而短暂断开长连接;这种的会有问题。
如下图,关于图片就不详细解释了,仔细看一下即可:
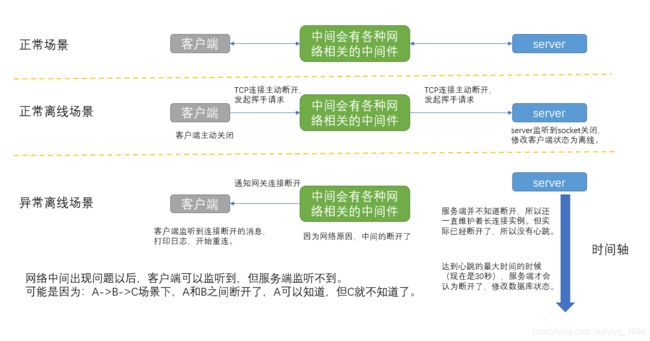
接下来再按照时间的趋势,从客户端、服务端、数据库状态以及客户端状态是否异常4个角度去分析一下:

这下问题就比较清晰了。但是问题来了,这种分析对不对呢?
验证猜想
在分析阶段,其实已经得到了这个结论,更准确地说,其实是猜想。基于这种猜想,也许有解决方案,但是似乎并没有验证方案呀,作为一个程序猿,没法测试的bug,那肯定是不行的。
上面最难搞的肯定就是那个网络波动,本地该去怎么模拟呢?很快就有了答案,模拟步骤如下:
- 客户端启动。
- 电脑直接断网,用来模拟网络波动。
- 盯着客户端日志看,一旦发现长连接中断的日志后,立即恢复网络。
- 此时日志里面会显示连接成功,然后去云端数据库(或者界面)一直刷新,查看客户端的实时状态。大约30多秒后,客户端状态被置为了离线。
不错,问题复现了。
当时也是这样来证明上述猜想的。不过还有一个点,显示离线,万一是真离线呢,最好能够手段证明真的假离线,我们之前做了状态修正的功能,能够把假离线置为在线,所以也可以验证。
解决问题
想要解决一个问题,就要彻底地明确问题,已知的问题以及解决方案如下:
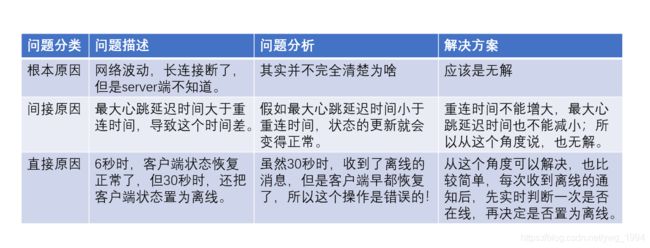
如何发现问题的呢?
从某种程度上来说,发现问题的过程,比上面的更重要,也更复杂,需要从已知的仅有的各种数据上去分析,再加上自己过硬的专业知识,可能发现特别不可思议的事情,甚至可能需要突破固有的思维。
想要发现问题,就必须有一个契机,一个可能和问题本身没有直接关系的现象,本次的就是。
客户端离线预警
客户端所处的网络环境是比较复杂的,所以会经常离线,因此我们做了监听到离线后,就会给相关人发送离线通知邮件,主要逻辑如下:
- 服务端监听到客户端离线的消息了,先把网关的数据库状态修改为离线,同时启动一个5分钟的延时任务。
- 5分钟后,判断当前客户端的数据库状态是否是在线,如果是在线,说明已经重连成功了,则什么都不做,结束。
- 如果不在线,说明5分钟了,还没有连接上,就发送邮件,并且记录下来。不用考虑一些特殊情况。比如连上了又断了等等,意义不大。
上线这个功能以后,我们发现每天都会有400次左右的离线记录。客户端大约1500个。说实话,离线的次数还是非常多的。而且注意一点,基本只有超过离线5分钟的话,才会记录一次。而且专门找了一些离线次数特别多的客户,一天有几十次,甚至打电话咨询了一下,最近有没有什么异常,答案是:没有。
奇怪的现象来了
我们所统计的记录和我们所认知的那样,以及和实际情况发现对不上了。
- 客户端只要离线,业务一定会受到影响。
- 目前发现的离线统计,一定是离线超过了5分钟才会记录。
- 客户反馈说,业务没有受到影响。
1+2可以推断出来的和实际的现象不符合,这个时候基本上已经意识到,哪里出了什么问题。客户的反馈应该没有问题,因为一旦有问题,肯定会联系我们的,但实际上没有找。
该怎么去发现呢
不知道是哪里的问题,但肯定是离线相关的,所以一定要从这个地方出发,关于离线,有这么几个事实:
- 客户端一旦离线,会打印一条错误日志。
- 客户端一旦连上,也会打印一条日志。
- 服务端发现客户端离线了,会打印一条日志。
- 服务端发现客户端连上了,会打印一条日志。
基于上述,我联系了一家离线次数比较多的客户,收集了某一天的日志,同时把我们服务端的日志,从中找出这个客户的客户端的在线和离线日志。
从日志里面,我发现这么几个现象:
- 客户端每次离线,下一次的重试就直接连上了,不会持续很长时间,确实只是网络波动。
- 客户端的每一次离线,每一次在线,和服务端的日志都是完全对上的。说明日志没有啥问题。
- 专门找了一个记录发送了邮件的离线记录,发现当它先离线后恢复以后的一个小时内,再也没有任何的离线记录了。但是邮件发出来了。
第三个现象,其实已经和已有的知识,相悖了。前面提过,发送邮件的机制是:离线了,并且过了5分钟,还是离线的,才会发送。这个发送邮件了,意味当时库里面的状态一定是离线的!但是事实就是,在也没有离线了。
那么问题来了:数据库状态改成了离线,而且是改错了。
到底是谁改的库呢?
当时的想法就是,当他重新连上的时候,一定会改成在线的,但是5分钟后,为什么又会变成了离线呢?所以一定有什么地方改了,思前想后,找到产品所有可能修改地方,但是那些都是由触发机制的,感觉从目前的现象来看,只有一网络波动,就会导致这个事情的发生,所以,当时这个问题就卡在这里了,想不明白了。
一般想不明白的时候,说明已经进入歪道了,得换个脑子,或者找其他人一起过来讨论。我选择了后者,先说了一下我的所有发现以及问题。这个时候,同事注意到了一个关键的现象:
每次离线和重新连上,服务端的日志,都是先在线,后离线。
怎么会是这样呢?肯定是先离线,后在线呀。先在线,后离线,时间差了一丢丢而已。这个非常重要的发现!
我刚开始再分析的时候,我也发现了,因为时间相差不大,不到1分钟,所以我很草率地认为是服务器时间不一致导致的,因为服务端是集群,日志都是随机打在节点上面的。这一点误导了自己!
接下来找了好几个先在线,后离线的情况。把它们全放在一起,做了对比:
2020-08-17 10:35:54,518 INFO com.test.Handler - client: xxx is OFFLINE now
2020-08-17 10:36:28,772 INFO com.test.Handler - client: xxx is ONLINE now
2020-08-17 11:12:04,747 INFO com.test.Handler - client: xxx is ONLINE now
2020-08-17 11:12:34,569 INFO com.test.Handler - client: xxx is OFFLINE now
2020-08-17 11:44:04,227 INFO com.test.Handler - client: xxx is ONLINE now
2020-08-17 11:44:32,707 INFO com.test.Handler - client: xxx is OFFLINE now
时间差的范围刚好是30秒左右!当发现这个的时候,30秒,我非常熟悉呀,是服务端定义的客户端心跳的最大间隔。这一下子就立马把所有的事情串了起来,得出了前文提到的所有的猜想,然后进行了模拟和验证。
问题反思
解决问题的思路很重要,多做总结和反思,会提高自己解决问题的能力,不断地去优化自己的思考方式。
这个问题困扰了大半年了,这次才因为邮件的问题,和这件事情本身没有啥问题,为契机,才发现了这个问题。
这次的问题是,客户端离线了,客户端发现了,服务端没有发现。
那么有没有另外一种情况,服务端发现了,但是客户端没有发现呢。
还真的有,这种情况非常极端吧,从网络层面上,我这边还没有特别好的解释,线上一千多家客户,目前我们只发现了一家出现了,这个现象比假离线的问题更加严重,客户端没有发现,意味着,不会重连,不重连的话,那一直就是断开,这个就需要另外一种心跳机制去做了。也可以解决。
有空的话,也可以分享一下这个过程,也算是比较复杂,和今天的现象是另外一回事。