RHEL运维的常用脚本、命令及性能分析
更新WAR包到测试环境
一般来说,测试会有一台专门的、干净的机器,用于打包,及将打好的包拷贝到测试环境、生产环境。
步骤大致如下:
1、登录 打包机器
2、cd 代码位置
3、更新代码:svn up
4、打包:mvn clean package -Dmaven.test.skip=true -U 或 ./package.sh
5、传包:scp war包 root@目标机器:目标文件位置
6、登录测试环境、开发环境
7、启动:./start.sh
8、查看日志:./seelog.sh
常用批处理文件内容
#package.sh 用于maven打包
mvn clean package -Dmaven.test.skip=true -U
#start.sh 用于重启JBOSS
killall -9 tail
killall -9 java
source /etc/profile
rm -rf /usr/java/jboss-eap-5.1/jboss-as/server/default/data/*
rm -rf /usr/java/jboss-eap-5.1/jboss-as/server/default/tmp/*
rm -rf /usr/java/jboss-eap-5.1/jboss-as/server/default/work/*
cd $JBOSS_HOME/bin/
nohup $JBOSS_HOME/bin/run.sh -c default -b 0.0.0.0 &
sleep 1
tailf /data/applogs/jbosslogs/server.log
#seelog.sh 用于查看日志
tailf /data/applogs/jbosslogs/server.log
#index.sh 用于执行一个java程序,并包含lib下面的jar
#!/usr/bin/env bash
CLASSPATH=.
for f in lib/*.jar; do
CLASSPATH=${CLASSPATH}:$f;
done
nohup java -classpath $CLASSPATH:xx.jar -Xms128m -Xmx1024m xx.xx.xx >> index_logs.txt 2>&1 &
写的完善一点,如下的方式可供参考(注意:在if [ -f "$tmp_file" ]; then中,[]里面前后都有一个空格的,否则不生效):
2>&1是除了标准输出之外,比如e.printStackTrace()也进行输出重定向
&是后台执行,标志几个进程会同时执行
work_path=/usr/local/workdir
tmp_file=/usr/local/workdir/tmp.txt
work_log=/data/applogs/xx.log
export JAVA_HOME=/usr/java/jdk1.6.0_26
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export LC_ALL=zh_CN.UTF-8
date >> "$work_log"
if [ -f "$tmp_file" ]; then
echo '系统正在运行,尚未完成' >> "$work_log"
echo '' >> "$work_log"
else
echo '系统开始运行 ' >> "$work_log"
echo '' >> "$work_log"
touch "$tmp_file"
cd "$work_path"
CLASSPATH=.
for f in ./*.jar; do
CLASSPATH=${CLASSPATH}:$f;
done
for f in lib/*.jar; do
CLASSPATH=${CLASSPATH}:$f;
done
echo '计算任务开始运行......' >> "$work_log"
echo '' >> "$work_log"
java -Xms1024m -Xmx12288m -classpath $CLASSPATH com.xx.xx.xx >> "$work_log"
sleep 10
rm "$tmp_file"
echo '计算任务运行完毕' >> "$work_log"
echo '' >> "$work_log"
fi比如,可以把以上存储位一个sh文件,然后用crontab定时运行:5 * * * * /usr/local/workdir/xx.sh &,这是每小时的第5分钟开始执行。
#定时备份清理Tomcat日志
修改catalina.sh,设置catalina.out输出目录
if [ -z "$CATALINA_OUT" ] ; then
#CATALINA_OUT="$CATALINA_BASE"/logs/catalina.out
CATALINA_OUT=/data/applogs/tomcatlogs/catalina.out
fi
00 1 */1 * * /data/sh/find_catalina.sh
log_path1="/usr/local/apache-tomcat-6.0.35/logs"
log_path2="/usr/local/apache-tomcat-7.0.41/logs/"
log_name="catalina.201*"
find $log_path1 -mmin +60 -name $log_name -exec mv {} /data/applogs/tomcatlogs/tomcat6/ \;
find $log_path2 -mmin +60 -name $log_name -exec mv {} /data/applogs/tomcatlogs/tomcat7/ \;
gzip /data/applogs/tomcatlogs/tomcat6/*.log
gzip /data/applogs/tomcatlogs/tomcat7/*.log10 * * * * /data/applogs/clear_tomcat_catalina.sh &
#!/bin/bash
cd /data/applogs/tomcatlogs
>catalina.out一条示例crontab
5 1 * * * nohup /home/hadoop/jobs/ip/job.sh >> /home/hadoop/jobs/ip/nohup.out 2>&1 &
定时压缩及清理日志
压缩2天之前的,清理20天之前的:
58 05 * * * /bin/bash /service/xx/clean.sh > /dev/null 2>&1
#!/bin/bash
rootpath='/xx/xx';
find $rootpath -mtime +1 -exec /bin/gzip {} \;
find $rootpath -mtime +5 -exec rm -fr {} \;开机自动启动设置
#vim /etc/rc.d/rc.local
#!/bin/sh
# This script will be executed *after* all the other init scripts.
# You can put your own initialization stuff in here if you don't
# want to do the full Sys V style init stuff.
touch /var/lock/subsys/local
/data/sh/route10.50.sh
/usr/local/nagios/bin/nrpe -c /usr/local/nagios/etc/nrpe.cfg -d
/usr/local/zabbix/sbin/zabbix_agentd
/usr/local/nginx/sbin/nginx
/data/sh/restartserverlist
把要启动的命令加在这个文件里面,或者自己做一个启动列表/data/sh/restartserverlist ,加到这个启动列表里面就行。
#vim /data/sh/restartserverlist
/data/ruby/ruby_start
#vim /data/sh/rsync_162.sh
rsync -avzP --password-file=/etc/sery.pass --delete /data/wcc/ [email protected]::wcc
#vim /data/sh/synctime.sh
/usr/sbin/ntpdate 66.187.233.4
/sbin/clock -w
Linux系统硬件配置查看方法
查看OS
查看当前linux的版本:
more /etc/redhat-release
cat /etc/redhat-release
查看内核版本:
uname -r
uname -a
查看默认语言:
echo $LANG $LANGUAGE
cat /etc/sysconfig/i18n
查看selinux情况:
sestatus
sestatus | cut -f2 -d:
cat /etc/sysconfig/selinux
查看键盘布局:
cat /etc/sysconfig/keyboard
cat /etc/sysconfig/keyboard | grep KEYTABLE | cut -f2 -d=
查看时间:
date 当前时间
uptime 运行时间
cat /etc/sysconfig/clock 所属时区和是否使用UTC时间
查看cron:
crontab -l 查看当前用户的
crontab -u username -l 显示某个用户的
crontab -e 修改crontab,改后直接生效
awk 'BEGIN{FS=":"}{print $1}' /etc/passwd | xargs -i crontab -u {} -l 2>/dev/null 查看所有用户的
切换root:
sudo su - 切换到root用户,会把当前用户的环境变量带过去
sudo su 切换到root
有时我们执行sudo java -version,报错“bash: java: command not found”,是因为root账户并没有把java加入环境变量,然后呢。。。
查看主机:
hostname
cat /etc/sysconfig/network
cat /etc/hosts
lspci 查看pci信息 lspci
curl --head www.163.com 查看163.com的服务器环境
查看当前用户的历史命令:
history
export HISTTIMEFORMAT="`whoami` : | %F | %T: | " 加上这个环境变量,可以显示操作人和日期时间。
watch,关于tcp listen queue的一点事,:http://www.douban.com/note/178129553/
curl -X POST --header "Content-Type:application/json;charset=utf-8" -d '{"id":116,"createProcess":"display"}' --cookie 'hssoid=b8ba9d9bd4a24da3b4df6333277eb350;' http://127.0.0.1:8411/active/getByStep.do
查看CPU
grep 'model name' /proc/cpuinfo | wc -l
more /proc/cpuinfo | grep "model name"
grep "model name" /proc/cpuinfo
grep "model name" /proc/cpuinfo | cut -f2 -d:
查看CPU是32位还是64位:getconf LONG_BIT
查看内存
grep MemTotal /proc/meminfo
grep MemTotal /proc/meminfo | cut -f2 -d:
free -m |grep "Mem" | awk '{print $2}'
查看进程
ps -ef | grep 'xx' 查看xx进程的id
cd /proc/进程id
ll -s
cwd,即是你要查找的进程所在路径
jps 查看java进程
查看线程
linux查看占用CPU最多的线程
Linux下如何查看高CPU占用率线程 LINUX CPU利用率计算
查看硬盘和分区
df -h
fdisk -l
du -sh 可以看到当前目录的大小
du -sh /etc 可以看到给到目录的大小
查看安装的软件包
cat -n /root/install.log
more /root/install.log | wc -l
rpm -qa
rpm -qa | wc -l
yum list installed | wc -l
查看网络信息
查看ip,mac地址
在ifcfg-eth0 文件里你可以看到mac,网关等信息。
ifconfig
cat /etc/sysconfig/network-scripts/ifcfg-eth0 | grep IPADDR
cat /etc/sysconfig/network-scripts/ifcfg-eth0 | grep IPADDR | cut -f2 -d=
ifconfig eth0 |grep "inet addr:" |awk '{print $2}'|cut -c 6-
ifconfig | grep 'inet addr:'| grep -v '127.0.0.1' | cut -d: -f2 | awk '{ print $1}'
查看网关
cat /etc/sysconfig/network
查看dns
cat /etc/resolv.conf
ifconfig eth0 up 启用网卡eth0
/etc/initd/network restart 重启网络服务
常用文件操作命令
文件内容替换命令sed
sed -i 's/aa/bb/g' *.txt 把当前目录下的所有txt文件中的aa替换成bb
sed -i 's/http:\/\/www.sina.com.cn//g' * 把当前目录下所有文件的http://www.sina.com.cn替换成空字符
sed wiki地址:http://en.wikipedia.org/wiki/Sed
注意:如果是mac系统,则sed -i要变成sed -i ''
sed -n '5,10p' filename 这样你就可以只查看文件的第5行到第10行
文件查找命令find
find . -type f -exec grep -l "10.10.20.90" {} \;查找当前目录下包含10.10.20.90的所有文件,包含子文件夹
find /user/test -type f -name "*.conf" | xargs grep "10.10.20.90" 在/user/test目录(包含子目录)下的.conf类型文件中查找含有"10.10.20.90"字符串的文件
find / -name access.log 2>/dev/null 在根目录下查找所有的access.log,包括子文件夹,遇到没有权限访问等错误,不会显示
grep统计
grep -rnc "字符串" 目录或文件 在给定目录或文件中查找字符串出现次数 r是递归,n是显示行号,c是显示次数
cat filename | tail -n +3000 | head -n 1000 从第3000行开始,显示1000行。即显示3000~3999行
cat filename| head -n 3000 | tail -n +1000 显示1000行到3000行
注意两种方法的顺序:
tail -n 1000:显示最后1000行
tail -n +1000:从1000行开始显示,显示1000行以后的
head -n 1000:显示前面1000行
man command | col -b >/home/command.txt 输出命令到文件
grep更多:
grep -C 5 foo file 显示file文件中匹配foo字串那行以及上下5行
grep -B 5 foo file 显示foo及前5行
grep -A 5 foo file 显示foo及后5行
查看grep版本的方法是:grep -V
性能分析工具
free -m详解

第一行(Mem)的意义,是从操作系统角度来统计的,如下:
total:物理内存,32092;
used:已用内存(包含buffers和cached),可能部分缓存并未被实际使用,23095
shared:共享内存,一般系统不会用到,0
buffers:系统分配但未被使用的buffers 数量,495
cached:系统分配但未被使用的cache 数量,973
第二行(-/+ buffers/cache)的意义,是从应用程序角度来统计的,如下:
used:实际使用的内存总理,等于第一行中的:used - buffers - cached,21627
free:未被使用的buffers 与cache 和未被分配的内存之和,这就是系统当前实际可用内存,等于第一行中的:free + buffers + cached,10465
对应用程序来讲,buffers/cached 是等同可用的,因为buffer/cached是为了提高程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。
所以,以应用来看看,以(-/+ buffers/cache)的free和used为主,所以我们主要看这个就好了。
第三行(Swap)的意义:表示硬盘上交换分区的使用情况,这里我们不去关心。
buffer 与cache 的区别:
A buffer is something that has yet to be "written" to disk.
A cache is something that has been "read" from the disk and stored for later use.
案例:
一个Hadoop Master机器,机器内存64G,cached占用40G,应该是大量读取文件造成的。
看了另一个生产中的Hadoop Master,机器内存18G,cached也是占用了12G。
网上也说:因为LINUX的内核机制,一般情况下不需要特意去释放已经使用的cache。这些cache起来的内容可以增加文件以及的读写速度。
据说可以手动释放,但是没有去尝试:echo 3 > /proc/sys/vm/drop_caches
参考文章:
http://www.2cto.com/os/201204/126594.html
http://blog.csdn.net/blade2001/article/details/8990571
http://blog.chinaunix.net/uid-25505925-id-180921.html
top详解
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器,截图如下:
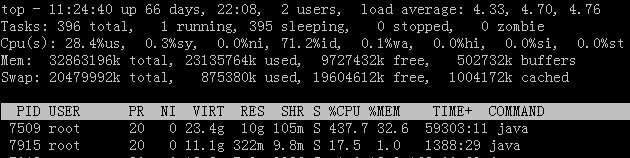
前五行是系统整体的统计信息。
第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下:
11:24:40: 当前时间
up 66 days, 22:08: 系统运行时间
2 user: 当前登录用户数
load average: 0.06, 0.60, 0.48:系统负载,即任务队列的平均长度。三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。
load average进一步了解:http://heipark.iteye.com/blog/1340384
第二、三行为进程和CPU的信息。其内容如下:
Tasks: 396 total:进程总数,1 running :正在运行的进程数,395 sleeping :睡眠的进程数,0 stopped:停止的进程数,0 zombie:僵尸进程数
Cpu(s): 28.4% us:用户空间占用CPU百分比,0.3% sy:内核空间占用CPU百分比,0.0% ni:用户进程空间内改变过优先级的进程占用CPU百分比,71.2% id:空闲CPU百分比,0.0% wa:等待输入输出的CPU时间百分比
第4行是内存,第5行是交换区。
第六行之下是进程信息区。
PID:进程ID
USER:进程所有者的用户名
PR:优先级
NI:nice值。负值表示高优先级,正值表示低优先级
VIRT:进程申请的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES:进程使用的内存大小,单位kb。RES=CODE+DATA
SHR:共享内存大小,单位kb
S:进程状态。D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程
%CPU:上次更新到现在的CPU时间占用百分比
%MEM:进程使用的物理内存百分比
TIME+:进程使用的CPU时间总计,单位1/100秒
COMMAND:进程执行的命令
关于VIRT、RES、SHR,参见这里:http://www.cnblogs.com/qq78292959/archive/2013/01/23/2873367.html
另外在top模式下,还可以输入1看所有的cpu,输入shift+h看线程,按f可以看每个缩写代表的意义,按c切换显示命令行和完整命令行信息等等,详解请参考网址:
http://www.cnblogs.com/wangkangluo1/archive/2012/04/18/2454993.html
netstat
有时候发现使用F5做负载的机器,每个机器的CPU负载非常不均衡,可以使用netstat查看一下端口的连接数,看看是不是f5的问题。
netstat -an | grep 1405
netstat -nat|grep -i "80"|wc -l 统计80端口连接数
对于怀疑程序本身引起的负载问题,可以使用jstack等工具看看。
查看占用CPU及内存最高的进程
linux下获取占用CPU资源最多的10个进程,可以使用如下命令组合:
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head
linux下获取占用内存资源最多的10个进程,可以使用如下命令组合:
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +4|head
查看占用CPU最多的线程
#!/bin/bash
# @Function
# Find the High cpu consume thread of java, and print the stack of these threads.
#
# @Usage
# $ ./show-busy-java-threads.sh
#
# @author Jerry Lee
redEcho()
{
echo -e "\033[1;31m$@\033[0m"
}
uuid=`date +%s`_${RANDOM}_$$
ps -Leo pid,lwp,user,comm,pcpu --no-headers `jps -lvm | grep hotel | awk -F " " '{print $1}'` |
sort -k5 -r -n | head -5 | while read threadLine ; do
pid=`echo ${threadLine} | awk '{print $1}'`
threadId=`echo ${threadLine} | awk '{print $2}'`
threadId0x=`printf %x ${threadId}`
user=`echo ${threadLine} | awk '{print $3}'`
pcpu=`echo ${threadLine} | awk '{print $5}'`
jstackFile=/tmp/${uuid}_${pid}
[ ! -f "${jstackFile}" ] &&
{
jstack ${pid} > ${jstackFile} ||
{ redEcho "Fail to jstack java process ${pid}"; rm ${jstackFile} ; continue; }
}
redEcho "The stack of busy(${pcpu}%) thread(${threadId}/0x${threadId0x}) of java process(${pid}) of user(${user}):"
sed "/nid=0x${threadId0x}/,/^$/p" -n ${jstackFile}
done
rm /tmp/${uuid}_*更多性能分析办法
查看这里:http://blog.csdn.net/puma_dong/article/details/19751597#t3