Kubernetes的三种可视化UI界面
一、dashboard
1)获取yaml文件修改并执行

[root@master ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc5/aio/deploy/recommended.yaml
[root@master ~]# vim recommended.yaml +39
#定位到39行,修改其提供的service资源
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 31001
selector:
k8s-app: kubernetes-dashboard
#因为默认情况下,service的类型是cluster IP,需更改为NodePort的方式,便于访问,也可映射到指定的端口
[root@master ~]# kubectl apply -f recommended.yaml
[root@master ~]# kubectl describe pod -n kubernetes-dashboard dashboard-metrics-scraper-7f5767668b-vx5j7 #查看详细信息
[root@master ~]# kubectl get pod -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-7f5767668b-vx5j7 1/1 Running 0 83s
kubernetes-dashboard-57b4bcc994-5khlb 1/1 Running 0 83s
#确保该yaml文件提供的pod均正常运行
[root@master ~]# kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.100.86.226 8000/TCP 92s
kubernetes-dashboard NodePort 10.96.213.125 443:31100/TCP 92s
#查看service资源,也属正常状态,并且已经映射了我们指定的端口
2)客户端访问测试
该版本之前的dashboard,必须使用火狐浏览器才可访问,本次使用的版本并没有硬性的要求。



3)使用Token的方式登录
#创建一个dashboard的管理用户
[root@master ~]# kubectl create serviceaccount dashboard-admin -n kube-system
serviceaccount/dashboard-admin created
#将创建的dashboard用户绑定为管理用户
[root@master ~]# kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
clusterrolebinding.rbac.authorization.k8s.io/dashboard-cluster-admin created
#获取刚刚创建的用户对应的token名称
[root@master ~]# kubectl get secrets -n kube-system | grep dashboard
dashboard-admin-token-22n2v kubernetes.io/service-account-token 3 13s
#查看token的详细信息
[root@master ~]# kubectl describe secrets -n kube-system dashboard-admin-token-22n2v
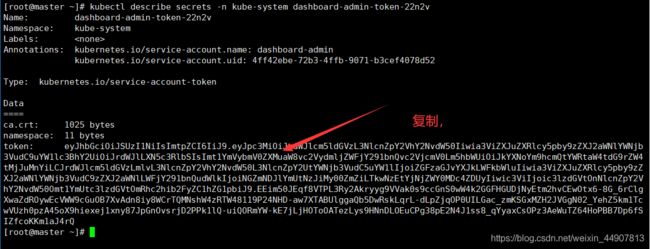
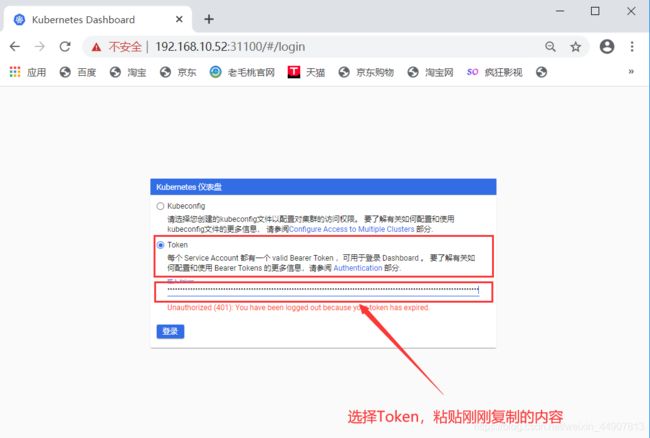

在上述页面可以进行对资源的一系列控制,包括删除、创建、

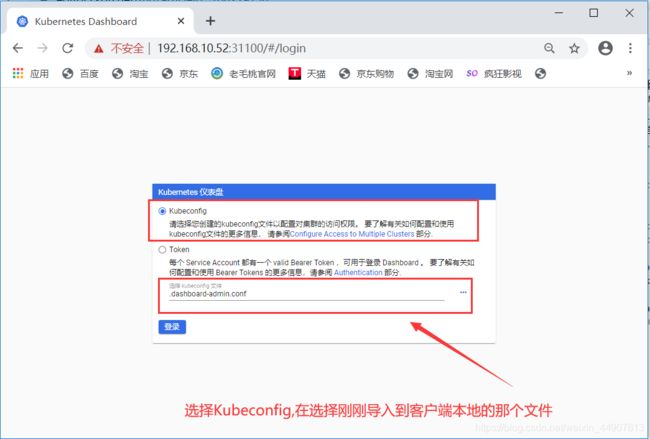
4)使用kubeconfig的方式登录
基于token的基础之上,进行以下操作:
#查看刚才创建的token
[root@master ~]# kubectl get secrets -n kube-system | grep dashboard
dashboard-admin-token-22n2v kubernetes.io/service-account-token 3 11m
#查看token的详细信息,会获取token
[root@master ~]# kubectl describe secrets -n kube-system dashboard-admin-token-22n2v
#将token的信息生成一个变量
[root@master ~]# DASH_TOKEN=$(kubectl get secrets -n kube-system dashboard-admin-token-22n2v -o jsonpath={.data.token} | base64 -d)
#将k8s集群的配置信息写入到一个文件中,文件可自定义
[root@master ~]# kubectl config set-cluster kubernets --server=192.168.10.52:6443 --kubeconfig=/root/.dashboard-admin.conf
Cluster "kubernets" set.
#将token的信息也写入到文件中(同一个文件)
[root@master ~]# kubectl config set-credentials dashboard-admin --token=${DASH_TOKEN} --kubeconfig=/root/.dashboard-admin.conf
User "dashboard-admin" set.
#将用户信息也写入文件中(同一个文件)
[root@master ~]# kubectl config set-context dashboard-admin@kubernetes --cluster=kubernetes --user=dashboard-admin --kubeconfig=/root/.dashboard-admin.conf
Context "dashboard-admin@kubernetes" created.
#将上下文的配置信息也写入文件中(同一个文件)
[root@master ~]# kubectl config use-context dashboard-admin@kubernetes --kubeconfig=/root/.dashboard-admin.conf
Switched to context "dashboard-admin@kubernetes".
#最后将配置信息导入到客户端本地
[root@master ~]# sz /root/.dashboard-admin.conf
二、Weave Scope

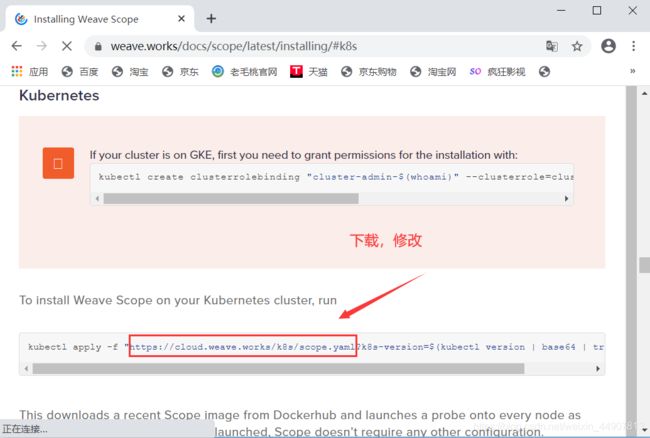
[root@master ~]# wget https://cloud.weave.works/k8s/scope.yaml
[root@master ~]# vim scope.yaml +212
#定位到212行,更改service类型为NodePort,并指定端口
spec:
type: NodePort
ports:
- name: app
port: 80
protocol: TCP
targetPort: 4040
nodePort: 31002
[root@master ~]# kubectl apply -f scope.yaml
[root@master ~]# kubectl get pod -n weave
#确保运行的pod均为Running状态
weave-scope-agent-4flkr 1/1 Running 0 65s
weave-scope-agent-5lgv7 1/1 Running 0 65s
weave-scope-agent-v65tc 1/1 Running 0 65s
weave-scope-app-b965dccb7-xfpqb 1/1 Running 0 65s
weave-scope-cluster-agent-6598584d8-g45qb 1/1 Running 0 65s
#DaemonSet资源对象:weave-scope-agent(代理):负责收集节点的信息;
#deployment资源对象:weave-scope-app(应用):从agent获取数据,通过web UI展示并与用户交互;
#DaemonSet资源对象的特性和deployment相比,就是DaemonSet资源对象会在每个节点上都运行且只能运行一个pod。
#由于每个节点都需要监控,所以用到了DaemonSet这种资源对象
[root@master ~]# kubectl get svc -n weave
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
weave-scope-app NodePort 10.105.184.15 80:30693/TCP 73s
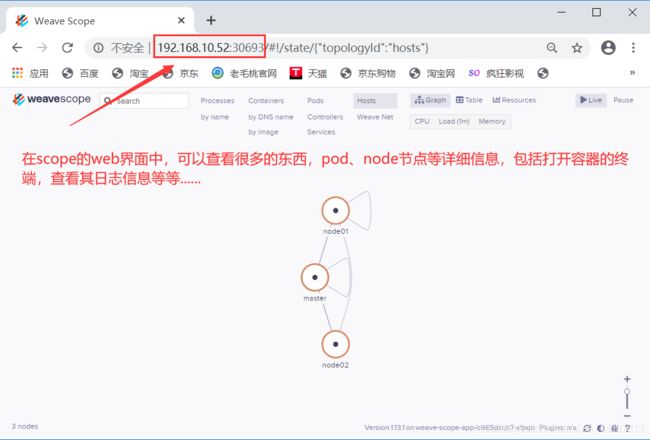
三、Prometheus
在真正部署Prometheus之前,应了解一下Prometheus的各个组件之间的关系及作用:
1)MertricServer:是k8s集群资源使用情况的聚合器,收集数据给K8s集群内使用,如:kubectl,hpa,scheduler;
2)PrometheusOperator:是一个系统检测和警报工具箱,用来存储监控数据;
3)NodeExporter:用于各node的关键度量指标状态数据;
4)kubeStateMetrics:收集k8s集群内资源对象数据,指定告警规则;
5)Prometheus:采用pull方式收集apiserver,scheduler,controller-manager,kubelet组件数据,通过http协议传输;
6)Grafana:是可视化数据统计和监控平台;
1)获取yaml文件修改并执行

[root@master ~]# yum -y install git
[root@master ~]# git clone https://github.com/coreos/kube-prometheus.git
#将项目克隆到本地
[root@master ~]# cd kube-prometheus/manifests/
[root@master manifests]# vim grafana-service.yaml
#更改grafana资源对应的service资源的类型及映射的端口
apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
type: NodePort #添加类型为NodePort
ports:
- name: http
port: 3000
targetPort: http
nodePort: 31010 #自定义映射的端口
selector:
app: grafana
[root@master manifests]# vim alertmanager-service.yaml
#更改alertmanager资源对应的service资源的类型及映射的端口
apiVersion: v1
kind: Service
metadata:
labels:
alertmanager: main
name: alertmanager-main
namespace: monitoring
spec:
type: NodePort #添加类型为NodePort
ports:
- name: web
port: 9093
targetPort: web
nodePort: 31020 #自定义映射的端口
selector:
alertmanager: main
app: alertmanager
sessionAffinity: ClientIP
[root@master manifests]# vim prometheus-service.yaml
#更改prometheus资源对应的service资源的类型及映射的端口
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort #添加类型为NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 31030 #自定义映射的端口
selector:
app: prometheus
prometheus: k8s
sessionAffinity: ClientIP
[root@master manifests]# pwd #确认当前所在目录
/root/kube-prometheus/manifests
[root@master manifests]# kubectl apply -f setup/
#必须先执行setup目录下的所有yaml文件
[root@master manifests]# cd .. #返回上层目录
[root@master kube-prometheus]# pwd #确认目录位置
/root/kube-prometheus
[root@master kube-prometheus]# kubectl apply -f manifests/
#将该目录下的yaml文件全部执行
[root@master kube-prometheus]# kubectl get pod -n monitoring
[root@master kube-prometheus]# kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 4m3s
alertmanager-main-1 2/2 Running 0 4m32s
alertmanager-main-2 2/2 Running 0 7m14s
grafana-86c68fc557-f8vrj 1/1 Running 0 7m36s
kube-state-metrics-75b5d66686-mddgd 3/3 Running 0 7m34s
node-exporter-7kbtq 2/2 Running 0 7m35s
node-exporter-qc76s 2/2 Running 0 7m35s
node-exporter-wmnmm 2/2 Running 0 7m35s
prometheus-adapter-68698bc948-68fpm 1/1 Running 0 7m35s
prometheus-k8s-0 3/3 Running 1 7m6s
prometheus-k8s-1 3/3 Running 1 7m6s
prometheus-operator-65c77bdd6c-z9dkv 2/2 Running 0 7m56s
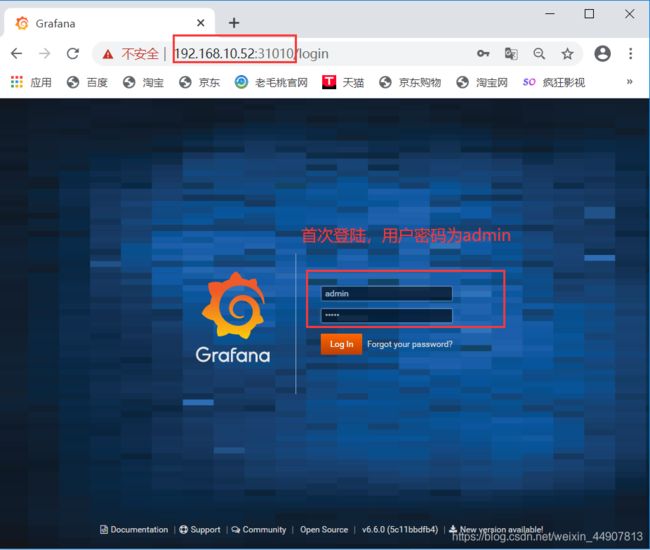
[root@master kube-prometheus]# kubectl get svc -n monitoring | grep grafana
grafana NodePort 10.102.118.23 3000:31010/TCP 7m45s
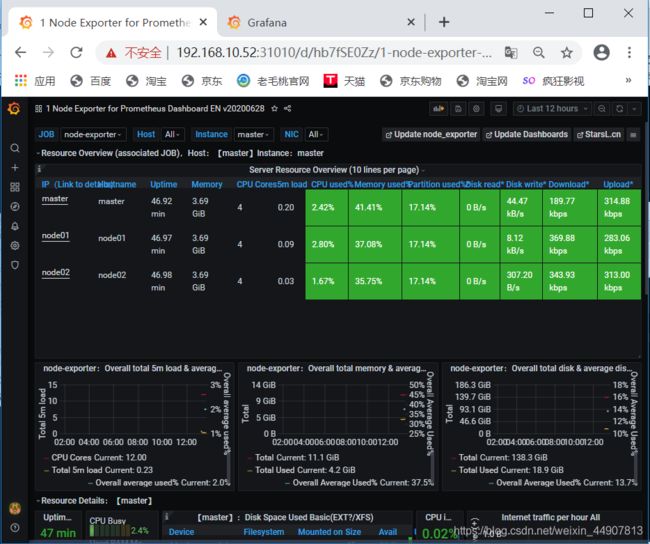
[root@master kube-prometheus]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 130m 3% 1534Mi 41%
node01 73m 1% 1320Mi 35%
node02 54m 1% 1304Mi 35%

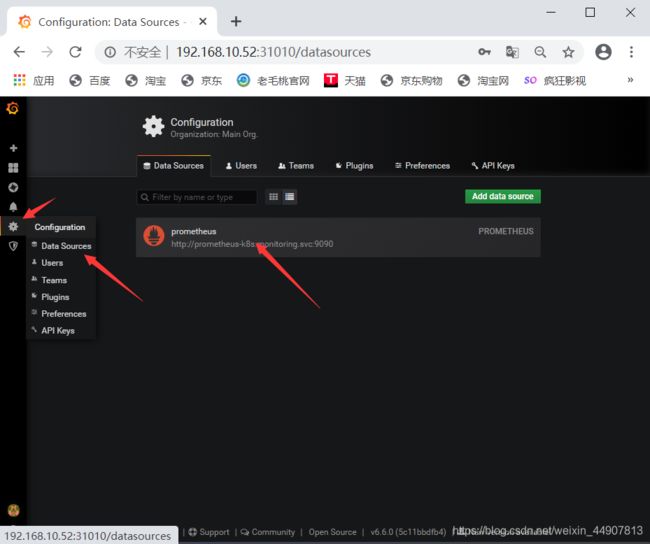
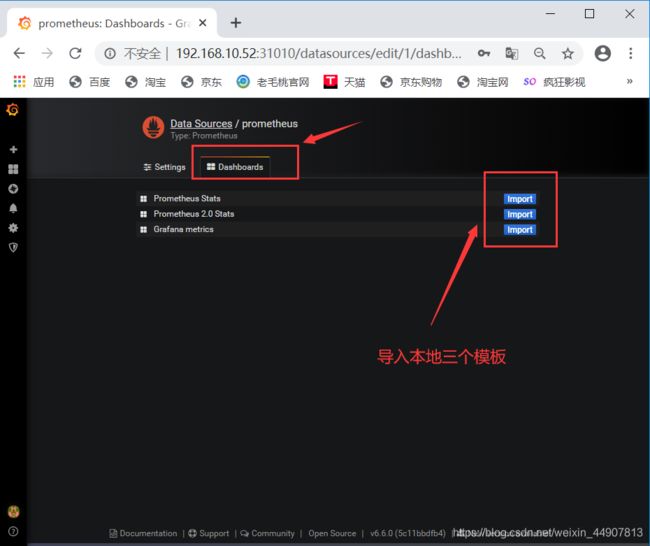

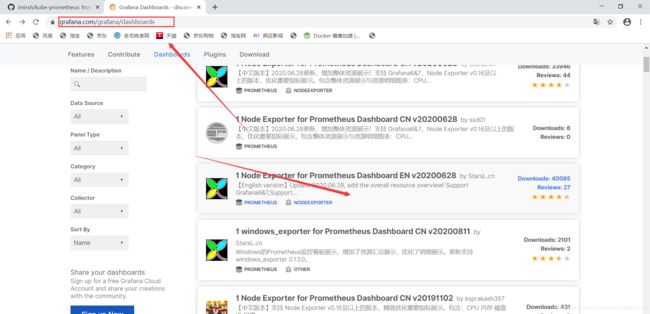
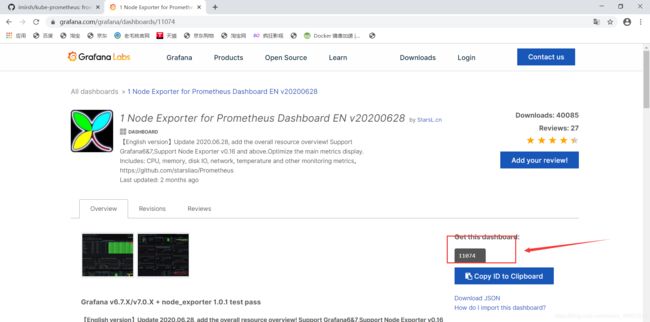
本地自带的模板有点low
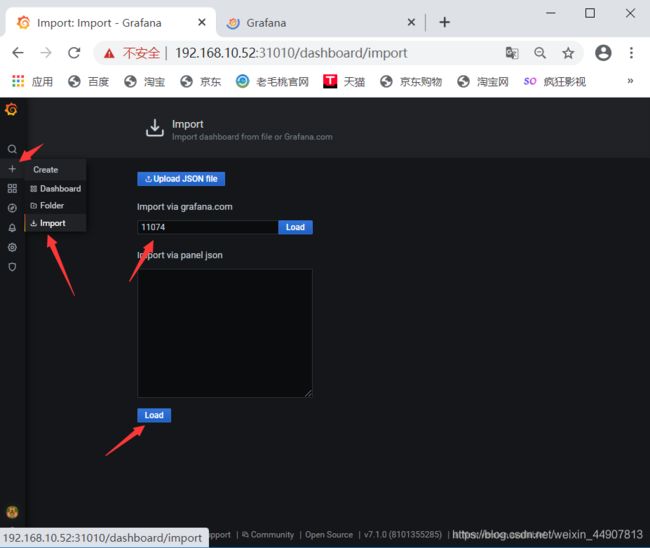
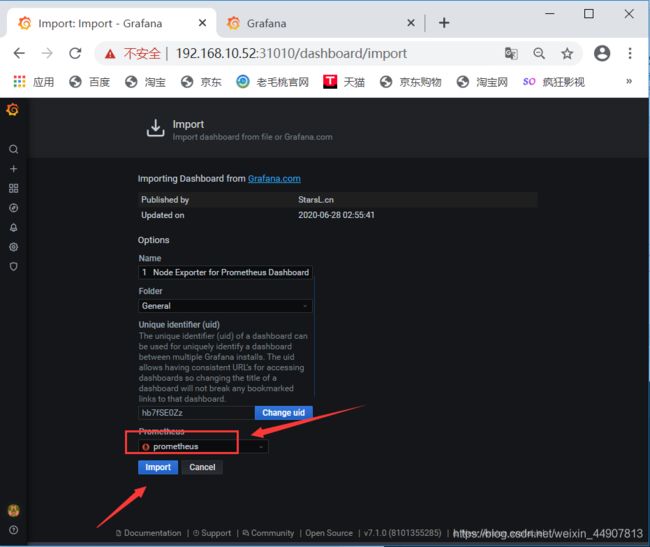
模板下载地址:https://grafana.com/dashboards