Redis全教程
1、redis持久化
使得redis重启后能够恢复数据(应对缓存穿透、缓存雪崩)
RDB方式(快照 ):根据指定的规则定时将内存中的数据存储到硬盘上
AOF方式:每次执行命令后将命令本身记录下来
两种方式可结合使用(更多时候),也可单独使用
1.1、RDB方式(快照)
redis会在以下几种情况下对数据进行快照:
- 根据配置规则进行自动快照
- 用户执行save或者bgsave命令
- 执行flushall命令
- 执行复制(replication)时
1.1.1、自动快照
用户在配置文件中自定义,有两个参数:时间窗口M(秒)和改动的键的个数N,每当时间M内被更改的键的个数大于N时,即符合自动快照条件
举例(redis.windows.conf文件中的):
save 900 1 #15分钟内有一个或一个以上的键被更改则进行快照
save 300 10
save 600 10000
可以同时存在多个条件,之间是或的关系
执行自动快照时,redis采用的策略是异步快照
1.1.2、用户执行save或bgsave命令
save:同步备份,会阻塞所有来自客户端的请求
bgsave:异步备份,会立即返回OK,如果想知道是否备份成功,可以使用lastsave命令获取最近一次成功执行快照的时间
1.1.3、用户执行flushall命令
首先,flushall会清空所有的键
当定义自动快照条件时,无论是否触发,执行flushall都会备份
当没有定义自动快照条件时,执行flushall不会备份
1.1.4、复制
当设置了主从模式时,既没有定义自动快照条件,也没有手动执行save命令,也会生成RDB快照文件
1.1.5、快照原理
dir ./ #快照文件路径
dbfilename dump.rdb #快照文件名
快照过程:
- redis使用fork函数复制一份当前进程(父进程)的副本(子进程)所以备份的是执行fork这一时刻的内存数据
- 父进程继续接收处理客户端请求,子进程开始讲内存中的数据写入磁盘临时文件
- 当子进程写完所有数据后会将临时文件替换旧的rdb文件
当只使用RDB方式实现持久化时,一旦redis异常退出,会丢失一些键,所以要结合AOF方式
1.2、AOF方式
AOF可以将redis执行的每一条写命令追加到磁盘文件上,显然会降低性能,AOF默认没有开启
appendonly yes #开启AOF
appendfilename "appendonly.aof" #AOF文件名
dir ./ #AOF文件路径
AOF的实现:
纯文本形式,保留的是redis通信协议的原始内容(REdis Serialization Protocol,RESP协议)
AOF文件中可能有很多冗余命令,比如:
set name zhangsan
set name lisi
此时第一条命令是冗余的,当冗余命令太多会导致aof文件太多,即使内存中的数据并没有多少
消除冗余命令(重写):
auto-aof-rewrite-percentage 100 #目前aof文件大小超过上一次重写时的aof文件大小的100%时会再次重写,如果上一次没有重写过,则依据启动时的aof文件大小为准
auto-aof-rewrite-min-size 64mb #重写aof文件的最小大小
手动重写:BGREWRITEAOF命令
重写的过程只和内存中的数据有关,和之前的aof文件无关,这和RDB相似,但两个文件格式完全不同
启动redis时会逐个将aof文件中的命令从磁盘加载到内存,速度比RDB文件慢
AOF会将命令记录到磁盘文件中,但由于操作系统有硬盘缓存,默认情况下每30秒将缓存真正写入到磁盘中,如果这30秒系统异常退出会导致数据丢失
# appendfsync always #总是进行同步,最慢但最安全
appendfsync everysec #折中方案,每秒进行一次同步
# appendfsync no #完全交由操作系统,即每30秒,最快但最不安全
当RDB和AOF同时开启时,redis重启后会使用aof文件加载数据,因为aof方式丢失的数据更少
redis是否需要持久化?
为了最大提升性能,不需要任何持久化,如果需要备份,采用集群模式
2、redis单线程为什么这么快
- 纯内存操作
- 单线程操作,避免频繁上下文切换
- 采用IO多路复用模型
- 纯ANSI C语言编写
2.1、linux5种IO模型
- 同步阻塞BIO
- 同步非阻塞NIO
- IO多路复用
- 事件驱动
- 异步非阻塞AIO
2.2、NIO和IO多路复用的对比
- NIO实际就是多路复用IO
- 在IO多路复用模型中,会有一个线程不断去轮询多个socket的状态,只有当socket真正有读写事件时,才真正调用实际的IO读写操作
- 在Java NIO中,是通过selector.select()去查询每个通道是否有到达事件,如果没有事件,则一直阻塞在那里,因此这种方式会导致用户线程的阻塞
- 多路复用IO比NIO的效率高的原因:在非阻塞IO中,不断地询问socket状态时通过用户线程去进行的,每调用一次就得在用户态和核心态切换一次,而在多路复用IO中,轮询每个socket状态是内核在进行的,这个效率要比用户线程要高的多
2.3、cpu状态切换
- 用户态:运行应用程序
- 核心态:运行操作系统程序,操作硬件
2.4、redis线程模型
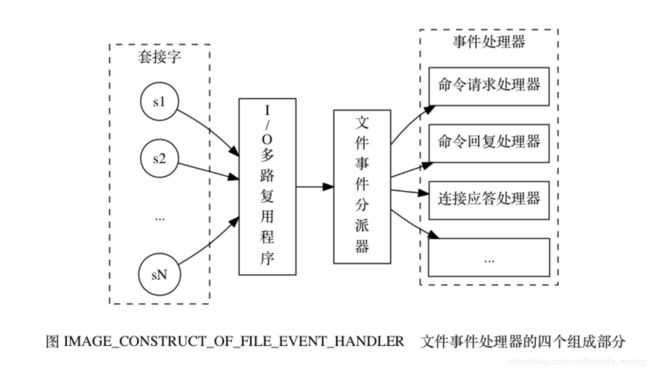
Redis内部实现采用epoll+自己实现的简单的事件框架。 epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性, 绝不在io上浪费一点时间
简单来说,就是。我们的redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端,有一段I/0多路复用程序,将其置入队列之中。然后,IO事件分派器,依次去队列中取,转发到不同的事件处理器中
2.4.1、IO多路复用的封装
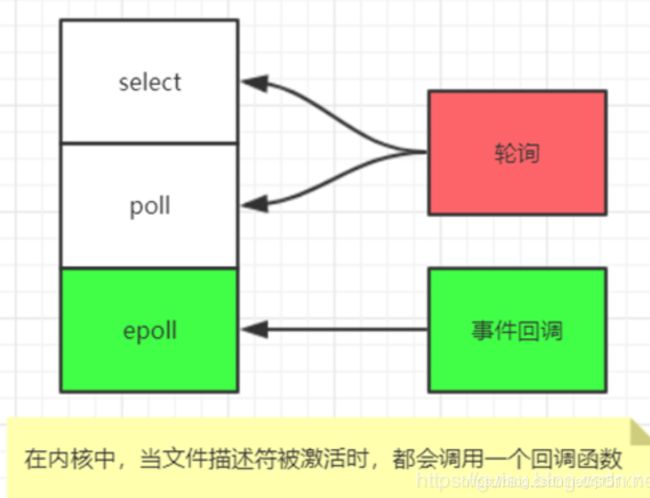
- select是POSIX提供的, 一般的操作系统都有支撑
- epoll 是LINUX系统内核提供支持的
- evport是Solaris系统内核提供支持的
- kqueue是Mac 系统提供支持的
2.4.2、文件事件分派器(Reactor)
Reactor 设计模式:事件驱动循环流程
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)
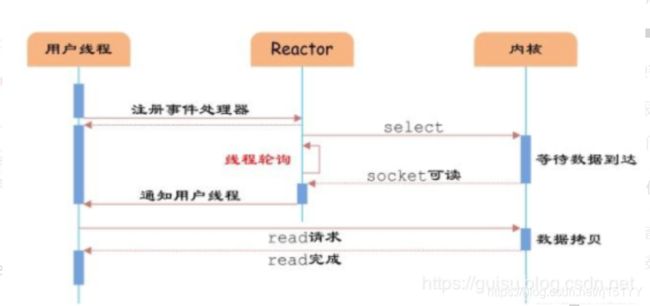
用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select/epoll函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。由于select/epoll函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket
2、redis和Memecache的区别
2.1、存储方式
Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis有部份存在硬盘上,redis可以持久化其数据
2.2、数据支持类型
memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型 ,提供list,set,zset,hash等数据结构的存储
2.3、使用底层模型不同
它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。 Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求
2.4、value 值大小不同
Redis 最大可以达到 512M;memcache 只有 1mb
2.5、其它
redis的速度比memcached快很多
Redis支持数据的备份,即master-slave模式的数据备份。
3、热点数据和冷数据
热点数据缓存才有价值
冷数据:如果缓存还没起作用就失效了,就没有意义了
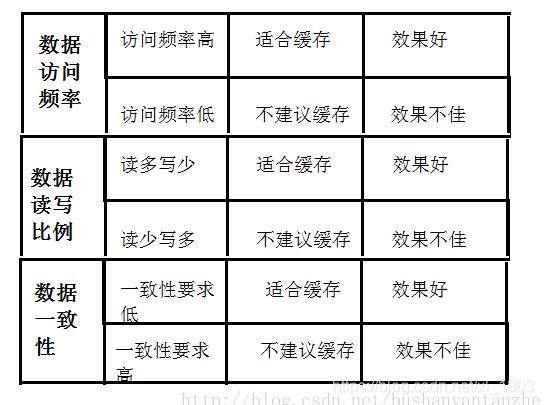
热点数据分两种,频繁修改的和不频繁修改的。一般来说频繁修改的数据不适合缓存,但如果读取这个数据对数据库压力大,那也应该用缓存
3.1、什么样的数据适合缓存
4、redis-cli命令大全
4.1、模糊查询key
keys pattern
支持glob风格通配符
redis不区分命令大小写

4.2、判断键是否存在
exists key
存在则返回1,不存在返回0
4.3、删除键
del key1 key2 ...
返回值是删除的键的个数
del不支持模糊删除,但可以这样redis-cli del 'redis-cli keys "name*"' 删除所有以name开头的key(windows下貌似不好使)
4.4、获取键的类型
type key
4.5、连接
#连接redis服务
redis-cli -h 127.0.0.1 -p 6379
4.6、切换数据库
select 0
4.7、查询当前数据库有多少key
dbsize
4.8、string
字符串类型是其它四种类型的基础,因为其它四种类型的值也是字符串,只不过字符串的形式不同而已
set key value
get key
mset key1 value1 key2 value2 ...
mget key1 key2 ...
incr key #如果字符串是数字类型,就递增
incrby key value #增加指定的数值
decr key
decrby key value
incrbyfloat key value #增加浮点数
append key value #追加
strlen key #获取长度
4.9、键命名策略
user:1:friends 存储ID为1的用户好友列表
对于多个单词则用点号(.)分隔
4.10、hash
redis不支持类型嵌套,比如hash类型的字段只能是string,不能是list或其他类型
hset key field value #不存在则set,存在则更新
hsetnx key field value #不存在时,才set,原子操作
hget key field
hmset key field1 value1 field2 value2 ...
hmget key field1 field2 ...
hgetall key
hexists key field
hdel key field1 field2 ...
hkeys key #获取所有属性
hvals key #获取所有值
hlen key #获取属性数量
4.11、list
lpush key value1 value2 ...
rpush key value1 value2 ...
lpop key #会删除元素
lpop key
lpush结合lpop(或rpush结合rpop)可以做栈
lllen key #list长度,时间复杂度为O(1) ,因为读取的是现成的值,不像mysql select count(*)会全表扫描
lrange key start end #不会删除元素,包含两端元素,支持负索引
ltrim key start end #和lrange类型,但会删除元素
lrem key count value #删除前count个值为value的元素,count>0从左删除,count<0从右删除,count=0删除所有
lindex key index #获取指定索引的元素
lset key index value #在指定索引处插入元素
linsert key before|after pivot value #将value插入到pivot的前面或后面
rpoplpush src dst #移除src队列最右边的元素,插入到dst队列的最左边,src和dst可以相同
4.12、set
sadd key value1 value2 ... #添加元素
srem key value1 value2 ... #删除元素
SMEMBERS key #获取所有元素
SISMEMBER key value #判断元素是否存在
集合间运算
scard key #获取元素个数
spop key #随机删除一个元素
SRANDMEMBER key count #随机获取count个元素,如果不传count则随机获取一个元素
4.13、zset
- list是用链表实现的,数据访问越靠两端的元素越快,适合实现新鲜事、日志这类很少访问中间元素的应用
- 而zet是通过skiplist实现的,即使读取中间部分的元素也很快
zadd key score1 value1 score2 value2 ... #添加元素,如果元素已存在则覆盖之前的分数
zscore key value1 #获取元素的分数
zrange key start end withscores #先从小到大排序,再返回start到end之间的元素,传入withscores会返回分数
zrevrange key start end withscores #从大到小排序
ZINCRBY key score value #给元素加分
zrangebyscore key min max withscores limit offset count #获取指定分数范围内的元素,min和max默认包含,(80表示不包含,-inf、+inf分别表示负无穷、正无穷
zrevrangebyscore #从大到小排序,注意min和max也是反的
zcard key #获取元素数量
zcount key min max #获取指定分数范围内的元素个数
zrank key value #获取元素排名
zrevrank key value #从大到小排序,获取元素排名
5、redis键的过期策略
5.1、过期时间命令
expire key seconds #单位是秒,pexpire命令可设置成毫秒
ttl key #查看键还有多久过期,pttl显示毫秒时间
persist key #清除过期时间设置,set|getset也可以清除过期时间
5.2、过期删除策略
5.2.1、定时删除策略(不采用)
用一个定时器来负责监视key,过期则自动删除,虽然内存及时释放,但是十分消耗CPU资源
在大并发请求下,CPU要将时间应用在处理请求,而不是删除key
5.2.2、定期删除+惰性删除策略(采用)
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除
如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制
5.2.3、内存淘汰机制
maxmemory 100mb #为0时代表没有内存限制
maxmemory-policy noenviction
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
noenviction(驱逐):禁止驱逐数据,新写入操作会报错
如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致
回收进程如何工作:
- 一个客户端运行了新的命令,添加了新的数据。
- Redi检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收
redis使用的是近似LRU算法(并非真实的,因为真实LRU算法太耗内存)
maxmemory-samples 5 #LRU算法的采样数量,可以提升到10来让LRU算法更真实,但会消耗更多的CPU时间
6、缓存雪崩、缓存穿透、缓存击穿
6.1、缓存雪崩
可以简单理解为:原有缓存失效,新缓存未到期
例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃
解决办法:
1、大多数系统设计者考虑用加锁( 最多的解决方案)或者队列的方式来保证不会有大量的线程对数据库一次性进行读写,从而避免缓存失效时大量的并发请求落到底层存储系统上
2、还有一个简单方案就是将缓存失效时间分散开
6.2、缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)
这时的用户很可能是攻击者,攻击会导致数据库压力过大
解决方法:
1、如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴
2、布隆过滤器
参考博文
6.3、缓存击穿
缓存击穿实际上是缓存雪崩的一个特例
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
击穿与雪崩的区别在于击穿是对于某一特定的热点数据来说,而雪崩是全部数据
解决办法:
1、加锁
static Lock reenLock = new ReentrantLock();
public List getData04() throws InterruptedException {
List result = new ArrayList();
// 从缓存读取数据
result = getDataFromCache();
if (result.isEmpty()) {
if (reenLock.tryLock()) {
try {
System.out.println("我拿到锁了,从DB获取数据库后写入缓存");
// 从数据库查询数据
result = getDataFromDB();
// 将查询到的数据写入缓存
setDataToCache(result);
} finally {
reenLock.unlock();// 释放锁
}
} else {
result = getDataFromCache();// 先查一下缓存
if (result.isEmpty()) {
System.out.println("我没拿到锁,缓存也没数据,先小憩一下");
Thread.sleep(100);// 小憩一会儿
return getData04();// 重试
}
}
}
return result;
} 2、定时任务主动刷新缓存
6.4、缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决方法:
1、直接写个缓存刷新页面,上线时手工操作下
2、数据量不大,可以在项目启动的时候自动进行加载
3、定时刷新缓存
6.5、缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级
7、Redis 常见性能问题和解决方案?
(1) Master 最好不要做任何持久化工作,如 RDB 内存快照和 AOF 日志文件
(2) 如果数据比较重要,某个 Slave 开启 AOF 备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性, Master 和 Slave 最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即: Master <- Slave1 <- Slave2 <-Slave3…
8、为什么Redis的操作是原子性的,怎么保证原子性的?
对于Redis而言,命令的原子性指的是:一个操作的不可以再分,操作要么执行,要么不执行。
Redis的操作之所以是原子性的,是因为Redis是单线程的。
Redis本身提供的所有API(单个命令)都是原子操作,Redis中的事务其实是要保证批量操作的原子性。
多个命令在并发中也是原子性的吗?
不一定, 举例:1、将get和set改成单命令操作;2、incr
如何解决:使用Redis的事务,或者使用Redis+Lua的方式实现
9、redis分布式锁
9.1、分布式锁需要解锁的问题:
- 互斥性:任意时刻只能有一个客户端拥有锁,不能同时多个客户端获取
- 安全性:锁只能被持有该锁的用户删除,而不能被其他用户删除 (推荐学习:Redis视频教程)
- 死锁:获取锁的客户端因为某些原因而宕机,而未能释放锁,其他客户端无法获取此锁,需要有机制来避免该类问题的发生
- 容错:当部分节点宕机,客户端仍能获取锁或者释放锁
9.2、springboot整合redis并实现分布式锁实战
9.2.1、pom文件
org.springframework.boot
spring-boot-starter-data-redis
9.2.2、application.yml
spring:
redis:
host: localhost
port: 6379
timeout: 10000
database: 0
9.2.3、RedisConfig
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig {
@Bean(name = "template")
public RedisTemplate template(RedisConnectionFactory factory) {
// 创建RedisTemplate对象
RedisTemplate template = new RedisTemplate<>();
// 配置连接工厂
template.setConnectionFactory(factory);
// 定义Jackson2JsonRedisSerializer序列化对象
Jackson2JsonRedisSerializer
9.2.4、redis分布式锁同步类
import org.springframework.dao.DataAccessException;
import org.springframework.data.redis.connection.RedisConnection;
import org.springframework.data.redis.connection.RedisStringCommands;
import org.springframework.data.redis.core.RedisCallback;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.types.Expiration;
public class ForRedisLock {
private RedisTemplate redisTemplate;
private int a;
private static final String KEY = "redis_lock";
public void add(){
while(true){
Boolean isGet = redisTemplate.execute(new RedisCallback() {
@Override
public Boolean doInRedis(RedisConnection conn) throws DataAccessException {
//解决死锁(某个线程获取到锁之后未能释放锁)的两种办法:
//1、设置过期时间,主动释放锁----conn的具有四个形参的set方法,同样具有setNX的作用
//2、使用setnx key "当前系统时间+锁持有的时间"和getset key "当前系统时间+锁持有的时间"组合的命令实现----conn的setNX方法
Boolean isGet = conn.set(KEY.getBytes(), "iamlock".getBytes(), Expiration.seconds(60), RedisStringCommands.SetOption.ifAbsent());
return isGet;
}
});
if(isGet){
a++;
//解锁
redisTemplate.delete(KEY);
break;
}
}
}
public void addNoLock(){
a++;
}
public int getA() {
return a;
}
public void setA(int a) {
this.a = a;
}
public RedisTemplate getRedisTemplate() {
return redisTemplate;
}
public void setRedisTemplate(RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
}
9.2.5、controller
import com.asiainfo.com.springboottest.util.ForRedisLock;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.dao.DataAccessException;
import org.springframework.data.redis.connection.RedisConnection;
import org.springframework.data.redis.connection.RedisStringCommands;
import org.springframework.data.redis.core.RedisCallback;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.types.Expiration;
import org.springframework.scheduling.annotation.Async;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class RedisLockController {
@Autowired
private RedisTemplate redisTemplate;
private static final String KEY = "redis_lock";
@RequestMapping("/lock")
@Async
public void lock(){
ForRedisLock lock = new ForRedisLock();
lock.setRedisTemplate(redisTemplate);
//单机演示redis分布式锁时,将数值从0加到3000简直太慢了,线程不要超过3000,太大了直接运行不起来
for (int i = 0; i < 3000; i++) {
new Thread(()->{
lock.add();
//lock.addNoLock();
}).start();
}
while(true){
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(lock.getA());
}
}
}
10、redis实现消息队列
10.1、普通消息队列
利用list数据类型的LPUSH和RPOP命令,循环生产和消费
10.2、阻塞消息队列
利用BLPOP和BRPOP命令
BRPOP key timeout #timeout为0表示永远阻塞
10.3、优先级队列
场景:小白新写了一篇博客,1000个用户订阅了小白,小白发表博客后,会将1000个用户加入队列中,发提醒邮件,此时有一个新用户订阅小白的博客,新用户会收到确认订阅的邮件,如果不排优先级的话,新用户收到订阅邮件会在发送1000个提醒邮件之后,这个时间太长了。从这个业务场景来看,提醒邮件没有确认邮件优先级高
BRPOP key1 key2 ... timeout #支持多个键,最左边的键优先级最高
10.4、发布与订阅
消息不会持久化
SUBSCRIBE channel1 channel2 ...
UNSUBSCRIBE channel1 channel2 ...
PSUBSCRIBE pattern #支持glob风格通配符
PUNSUBSCRIBE pattern
publish channel message
订阅之后会收到三条消息,第一条消息的含义是消息类型:
- subscribe
- message
- unsubscribe
11、管道技术pipeline
redis的使用瓶颈在于网络延迟,其次是cpu和内存
管道技术最显著的优势是提高了redis服务的性能
通过pipeline方式当有大批量的操作时候。我们可以节省很多原来浪费在网络延迟的时间。需要注意到是用pipeline方式打包命令发送,redis必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并是不是打包的命令越多越好。具体多少合适需要根据具体情况测试
11.1、redisTemplate实现管道
List
12、redis集群
集群的好处:
- 避免单点故障
- 单个redis的内存容易成为瓶颈,所以要进行数据分片
12.1、复制
12.1.1、主从复制
主库可以读写,从库只读(接收主库同步过来的数据)
如何配置:
- 主库无需任何配置
- 从库加上配置:slaveof 主库地址 主库端口号
- 设置slave-read-only为no可以让从库也可以进行写操作,但是从库数据不会同步给其它库,会产品数据不一致问题
主从复制缺点:主库或从库如果崩溃了进行重启以及重启后的数据恢复,都是手工操作,比较麻烦,也容易出错,哨兵模式可以解决这个问题
INFO replication #查看状态
12.1.2、原理
- 从库启动时,会向主库发送SYNC命令
- 主库接收到SYNC后,会在后台进行快照,并将保存快照期间的命令缓存起来
- 快照保存后,主库会将快照文件和缓存起来的命令发给从库
- 从库进行复制初始化
- 复制同步阶段:初始化后,主库每接收到一个命令,就会同步给从库
补充:
- 增量复制:如果从库端口重连了,主库只需将断开期间的命令发给从库,不需要再进行一次复制初始化
- 从库同步过程中,不是阻塞的,客户端能正常与从库通信,但通信的数据是同步完成前的,可以配置slave-serve-stale-data为no让从库同步完成前向客户端返回错误
- 乐观复制策略:主库向从库同步命令是异步的,这样会产生数据不一致的时间窗口,但保证了主库的性能
- 主从同步可以实现读写分离
- 无硬盘复制:因为复制的时候主库会生成快照文件,而硬盘的速度是很慢的,所以可以直接发送给从库而不存储在硬盘上,设置repl-disable-tcp-nodelay为yes开启无硬盘复制
12.1.3、图结构
简单来说,从库也可以作为主库,同时拥有多个从库
12.1.4、从库持久化
首先,主库关闭持久化,从库开启持久化
如果从库崩溃,则重启后自动从主库同步数据,不会发生数据丢失
如果主库(一主多从)崩溃,情况比较复杂:
- 主库不可以重启,因为主库没有开启持久化,重启之后数据丢失,再同步给从库,导致从库也丢失数据,这样从库持久化就没有意义
- 在从库执行slaveof no one命令将从库提升为主库
- 配置slaveof,将主库降级为从库,并同步新的主库的数据
12.2、哨兵
哨兵是一个独立的进程(redis-sentinel),用于监控主从库
多个哨兵之间也会互相监控
哨兵的作用:
- 监控主从库是否正常运行
- 主库出现故障时自动将从库转为主库
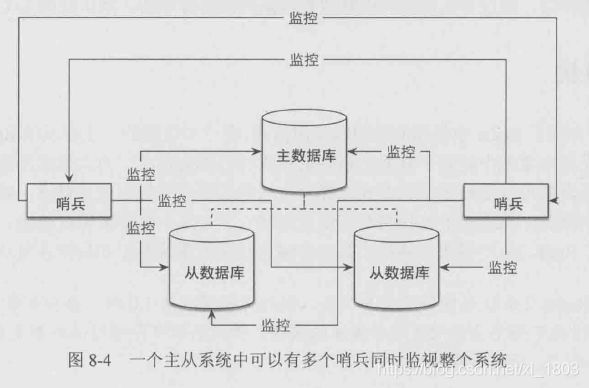
12.3、集群
redis集群没有使用一致性hash,而是引入了哈希槽的概念,默认有16384个哈希槽,通过CRC16(key) mod 16384的值,决定将一个key放到哪个槽中,redis集群的每个节点均匀分配一部分hash槽
使用哈希槽的好处就在于可以方便的添加或移除节点:
- 当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了
- 当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了
- 新增或移除节点的时候不用先停掉所有的 redis 服务
12.4、redis分区分片原理
13、redis内部数据结构
redis底层有6种数据结构,分别是:
简单动态字符串(SDS)
- 双向链表quicklist
- 字典dict
- 跳跃表skiplist
- 整数集合intset
- 压缩列表ziplist
用途:
- sds是Redis 底层所使用的字符串表示,它被用在几乎所有的Redis 模块中
- redis的一个database中所有key到value的映射,就是使用一个dict来维护的
- list使用双向链表或压缩链表(同时满足两个条件:1、所有元素长度不能超过64字节;2、元素个数小于512个)
- 一个Redis hash结构,采用压缩链表(同时满足两个条件:1、所有元素长度不能超过64字节;2、元素个数小于512个)或dict来存储
- set采用intset(同时满足两个条件:1、所有元素都是整数;2、元素个数小于512个)或dict(就好比hashset是基于hashmap实现一样)实现
- zset采用skiplist+dict或ziplist+ziplist(一个保存元素值,一个保存分数。同时满足两个条件:1、所有元素长度不能超过64字节;2、元素个数不能超过128个)
参考链接
14、redis经典实例
14.1、使用有序集合实现排行榜
- 世界杯竞猜积分排行榜
- 游戏等级排行榜
- 标签引用次数排行榜
如果使用mysql数据库,则采用order by+limit获取前100名,如果数据量大,全表扫描肯定很慢