haproxy+pacemaker+corosync实现高可用
pacemaker+corosync
Pacemaker是一个集群资源管理器。它利用集群基础构件(OpenAIS 、heartbeat或corosync)提供的消息和成员管理能力来探测并从节点或资源级别的故障中恢复,以实现群集服务(亦称资源)的最大可用性。
Corosync是集群管理套件的一部分,通常会与其他资源管理器一起组合使用它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。它是一个新兴的软件,2008年推出,但其实它并不是一个真正意义上的新软件,在2002年的时候有一个项目Openais , 它由于过大,分裂为两个子项目,其中可以实现HA心跳信息传输的功能就是Corosync ,它的代码60%左右来源于Openais. Corosync可以提供一个完整的HA功能,但是要实现更多,更复杂的功能,那就需要使用Openais了。Corosync是未来的发展方向。在以后的新项目里,一般采用Corosync,而hb_gui可以提供很好的HA管理功能,可以实现图形化的管理。
简而言之:
一个用于心跳检测,一个用于资源转移。两个结合起来使用,可以实现对高可用架构的自动管理。
心跳检测是用来检测服务器是否还在提供服务,只要出现异常不能提供服务了,就认为它挂掉了。
当检测出服务器挂掉之后,就要对服务资源进行转移。
CoroSync是运行于心跳测试的开源软件。PaceMaker是运行于资源转移层的开源软件。
pacemaker+corosync+haproxy实现高可用
图解:

本篇博客中涉及的所有软件包下载可参考此博客:https://blog.csdn.net/qq657886445/article/details/83662696
pacemake+corosync配置
给两个节点(server1与server4)安装haproxy,pacemaker,corosync,crmsh,pssh(安装包自行下载)
安装完成后,进行 corosync 的配置:
yum install -y pacemaker corosync
rpm -ivh pssh-2.3.1-2.1.x86_64.rpm
yum install crmsh-1.2.6-0.rc2.2.1.x86_64.rpm -y

cd /etc/corosync/
cp corosync.conf.example corosync.conf

vim /etc/corosync/corosync.conf
compatibility: whitetank #是否兼容0.8以前的版本
totem {
version: 2 #通信协议
secauth: off #安全认证功能 off别人知道多波地址 就可以加入 最好开启
threads: 0 #0表示默认 认证时候并行线程
interface {
ringnumber: 0 #定义环号,防止心跳信息循环发送 就有一块网卡就用0
bindnetaddr: 172.25.254.0 #绑定网络地址
mcastaddr: 226.94.1.1
mcastport: 5405 #多波端口
ttl:1 #只发一次 避免环路
}
}
logging {
fileline: off
to_stderr: no #标准错误输出
to_logfile: yes
to_syslog: yes
logfile: /var/log/cluster/corosync.log
debug: off
timestamp: no #是否记录时间戳
logger_subsys {
subsys: AMF
debug: off
}
}
amf {
mode:disabled #编程相关
}
service {
ver: 0
name: pacemaker
}
scp corosync.conf server4:/etc/corosync/
/etc/init.d/corosync start #server4也开启服务
crm_verify -LV #检查语法错误,第一次检查会报错,需要修改配置 ,默认开启fence而我们没有添加fence

crm configure show #显示集群配置
crm #进入crm管理集群
crm(live)# configure
crm(live)configure# show
node server1
node server4
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2"
crm(live)configure# property stonith-enabled=false #禁掉fence
crm(live)configure# commit #每次添加都需要提交
crm(live)configure# bye
crm_verify -LV #没有报错

primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.254.100 cidr_netmask=24 op monitor interval=1min #添加vip


crm_mon #监控集群信息

property no-quorum-policy=ignore #关闭集群对节点数量的检查
如果节点server1故障,节点server4收不到心跳请求,直接接管服务,保证正常运行,不至于一个节点崩掉而使整个集群崩掉

实现haproxy服务高可用
Server4安装haproxy

yum install -y haproxy-1.4.24-1.x86_64.rpm
scp /etc/haproxy/haproxy.conf server4:/etc/haproxy/
在crm集群中添加haproxy服务
primitive haproxy lsb:haproxy op monitor interval=1min
group hagroup vip haproxy #避免资源飘移,将他们绑定在一个组

crm_mon #监控得

测试:
停掉server4,server1接管服务,当server4开启时,服务不回切

httpd仍然访问轮询

添加fence
确保物理机fence_virtd服务开启,并且fence配置正确,查看/etc/fence_virt.conf
确保两个节点有fence_xvm,/etc/cluster/fence_xvm.key
Server1
primitive vmfence stonith:fence_xvm params pcmk_host_map="server1:vm1;server4:vm4" op monitor interval=1min # 添加fence,server1:vm1(虚拟机主机名:虚拟机名)
property stonith-enabled=true #打开fence
commit
show
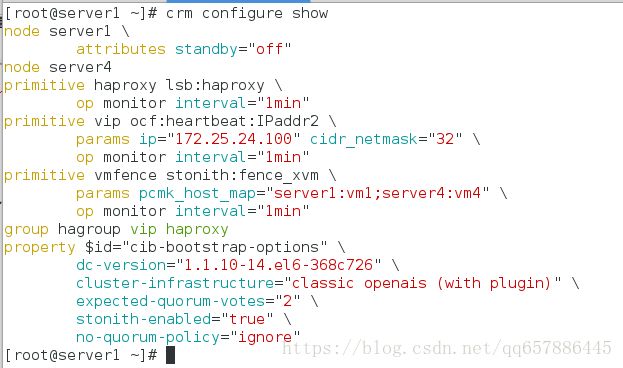
[root@server1 ~]# crm configure show
node server1 \
attributes standby="off"
node server4
primitive haproxy lsb:haproxy \
op monitor interval="1min"
primitive vip ocf:heartbeat:IPaddr2 \
params ip="172.25.24.100" cidr_netmask="32" \
op monitor interval="1min"
primitive vmfence stonith:fence_xvm \
params pcmk_host_map="server1:vm1;server4:vm4" \
op monitor interval="1min"
group hagroup vip haproxy
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="true" \
no-quorum-policy="ignore"
打开监控查看:

若想删除资源配置
先进入resoure关闭,然后进入configure删除。具体操作如下图
