Flume+Kafka+SparkStreaming整合
目录
1.Flume介绍.2
1.1 Flume数据源以及输出方式.2
1.2 Flume的核心概念.2
1.3 Flume结构.2
1.4 Flume安装测试.3
1.5 启动flume4
2.Kafka介绍.4
2.1 Kafka产生背景.4
2.2 Kafka部署结构.4
2.3 Kafka集群架构.4
2.4 Kafka基本概念.5
2.5 Kafka安装测试.5
3.Flume和Kafka整合.6
3.1两者整合优势.6
3.2 Flume和Kafka整合安装.6
3.3 启动kafka flume相关服务.7
3.4 Kafka和SparkStreaming整合.8
1. Flume介绍
Flume是Cloudera提供的一个分布式、可靠、和高可用的海量日志采集、聚合和传输的日志收集系统,支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
1.1 Flume数据源以及输出方式
Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力,在我们的系统中目前使用exec方式进行日志采集。
Flume的数据接受方,可以是console(控制台)、text(文件)、dfs(HDFS文件)、RPC(Thrift-RPC)和syslogTCP(TCP syslog日志系统)等。本测试研究中由kafka来接收数据。
1.2 Flume的核心概念
1. Agent:使用JVM运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。
2. Client:生产数据,运行在一个独立的线程。
3. Source:从Client收集数据,传递给Channel。
4. Sink:从Channel收集数据,运行在一个独立线程。
5. Channel:连接 sources和 sinks ,这个有点像一个队列。
6. Events :可以是日志记录、 avro对象等。
1.3 结构
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成,如下图:

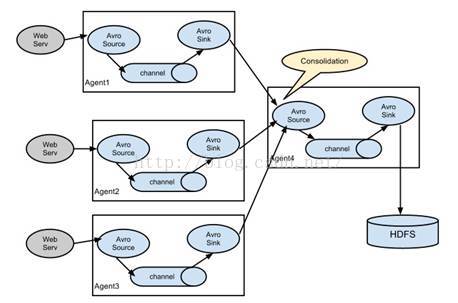
Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、ContextualRouting、Backup Routes。如下图所示:
1.4 安装测试
解压apache-flume-1.6.0-bin.tar.gz:tar –zxvf apache-flume-1.6.0-bin.tar.gz
cp conf/flume-conf.properties.template conf/exec.conf
cp conf/flume-env.sh.template conf/flume-env.sh 配置JAVA_HOME
exec.conf配置如下:
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.channels = c2
a2.sources.r2.command=tail -n +0 -F /usr/local/hadoop/flume/test.log
# Describe the sink
a2.sinks.k2.type = logger
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
验证安装:flume-ng version

1.5 启动flume
flume-ng agent --conf ./flume/conf/ -f ./flume/conf/exec.conf-Dflume.root.logger=DEBUG,console -n a2
发送数据和flume接收数据:
![]()
![]()
2.Kafka介绍
2.1 产生背景
Kafka 是分布式发布-订阅消息系统。它最初由 LinkedIn 公司开发,使用 Scala语言编写,之后成为 Apache 项目的一部分。Kafka是一个分布式的,可划分的,多订阅者,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。
在大数据系统中,常常会碰到一个问题,整个大数据是由各个子系统组成,数据需要在各个子系统中高性能,低延迟的不停流转。传统的企业消息系统并不是非常适合大规模的数据处理。为了已在同时搞定在线应用(消息)和离线应用(数据文件,日志)Kafka 就出现了。Kafka 可以起到两个作用:
降低系统组网复杂度
降低编程复杂度,各个子系统不在是相互协商接口,各个子系统类似插口插在插座上,Kafka 承担高速数据总线的作用。
2.2 部署结构

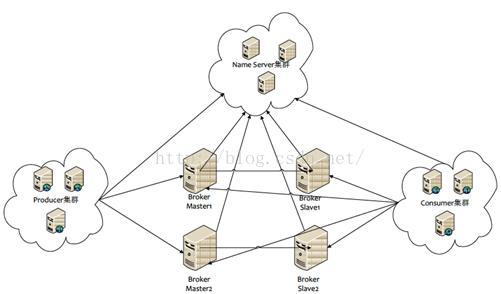
2.3 集群架构
2.4 基本概念
Topic:特指 Kafka 处理的消息源(feeds of messages)的不同分类。
Partition:Topic 物理上的分组,一个topic 可以分为多个 partition,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的id(offset)。
Message:消息,是通信的基本单位,每个 producer 可以向一个 topic(主题)发布一些消息。
Producers:消息和数据生产者,向 Kafka的一个 topic 发布消息的过程叫做 producers。
Consumers:消息和数据消费者,订阅 topics 并处理其发布的消息的过程叫做 consumers。
Broker:缓存代理,Kafa 集群中的一台或多台服务器统称为broker。
2.5 安装测试
解压Kafka: tar -xzf kafka_2.10-0.8.1.1.tgz
启动ZK bin/zookeeper-server-start.shconfig/zookeeper.properties
启动服务bin/kafka-server-start.sh config/server.properties>/dev/null 2>&1&
创建主题 bin/kafka-topics.sh --create --zookeeperlocalhost:2181 --replication-factor 1 --partitions 1 --topic test
查看主题 bin/kafka-topics.sh --list --zookeeperlocalhost:2181
查看主题详情 bin/kafka-topics.sh--describe --zookeeper localhost:2181 --topic test
删除主题 bin/kafka-run-class.shkafka.admin.DeleteTopicCommand --topic test --zookeeper localhost:2181
创建生产者bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
创建消费者bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test--from-beginning
3.Flume和Kafka整合
3.1 两者整合优势
Flume更倾向于数据传输本身,Kakfa是典型的消息中间件用于解耦生产者消费者。
具体架构上,Agent并没把数据直接发送到Kafka,在Kafka前面有层由Flume构成的forward。这样做有两个原因:
Kafka的API对非JVM系的语言支持很不友好,forward对外提供更加通用的HTTP接口。
forward层可以做路由、Kafka topic和Kafkapartition key等逻辑,进一步减少Agent端的逻辑。
数据有数据源到flume再到Kafka时,数据一方面可以同步到HDFS做离线计算,另一方面可以做实时计算。本文实时计算采用SparkStreaming做测试。
3.2 Flume和Kafka整合安装
Flume和Kafka插件包下载:https://github.com/beyondj2ee/flumeng-kafka-plugin
提取插件中的flume-conf.properties文件:修改如下:flume源采用exec
producer.sources.s.type = exec
producer.sources.s.command=tail -f -n+1/usr/local/Hadoop/flume/test.log
producer.sources.s.channels = c
修改producer代理的topic为test
将配置放到flume/cong/producer.conf中
复制插件包中的jar包到flume/lib中:删除掉版本不同的相同jar包,这里需要删除scala-compiler-z.9.2.jar包,否则flume启动会出现问题。
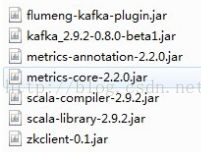
复制kafka/libs中的jar包到flume/lib中。
完整producer.conf:
producer.conf:
#agentsection
producer.sources= s
producer.channels= c
producer.sinks= r
#sourcesection
producer.sources.s.type= exec
#producer.sources.s.spoolDir= /usr/local/hadoop/flume/logs
#producer.sources.s.fileHeader= true
producer.sources.s.command= tail -f -n+1 /usr/local/hadoop/flume/aaa.log
producer.sources.s.channels= c
# Eachsink's type must be defined
producer.sinks.r.type= org.apache.flume.plugins.KafkaSink
producer.sinks.r.metadata.broker.list=localhost:9092
producer.sinks.r.partition.key=0
producer.sinks.r.partitioner.class=org.apache.flume.plugins.SinglePartition
producer.sinks.r.serializer.class=kafka.serializer.StringEncoder
producer.sinks.r.request.required.acks=0
producer.sinks.r.max.message.size=1000000
producer.sinks.r.producer.type=sync
producer.sinks.r.custom.encoding=UTF-8
producer.sinks.r.custom.topic.name=test
#Specifythe channel the sink should use
producer.sinks.r.channel= c
# Eachchannel's type is defined.
producer.channels.c.type= memory
producer.channels.c.capacity= 1000
producer.channels.c.transactionCapacity= 100
3.3 启动kafka flume相关服务
启动ZKbin/zookeeper-server-start.sh config/zookeeper.properties
启动Kafka服务 bin/kafka-server-start.sh config/server.properties
创建消费者bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test--from-beginning
启动flume
flume-ng agent --conf./flume/conf/ -f ./flume/conf/producer.conf -Dflume.root.logger=DEBUG,console-n producer
向flume发送数据:
![]()
Kafka消费者数据:
![]()
3.4 Kafka和SparkStreaming整合
核心代码:
完整代码路径:
spark-1.4.0\examples\src\main\java\org\apache\spark\examples\streaming


执行参数:
![]()
发送数据:
由于flume采用exec数据源的方式,因此flume会监听配置的相应的文件: tail -f -n+1 /usr/local/Hadoop/flume/aaa.log
当向该文件追加文件时,flume就会获取追加的数据:
writetoflume.py

flume将获取的增量数据由sink发送给kafka,以下是kafka comsumer消费的数据
![]()
执行结果:
SparkStreaming订阅kafka的test主题的数据,将订阅的数据进行单词计数处理。
