神经网络权重更新的原理和方法——softmax前世今生系列(7)
导读:
softmax的前世今生系列是作者在学习NLP神经网络时,以softmax层为何能对文本进行分类、预测等问题为入手点,顺藤摸瓜进行的一系列研究学习。其中包含:
1.softmax函数的正推原理,softmax的代数和几何意义,softmax为什么能用作分类预测,softmax链式求导的过程。
2.从数学的角度上研究了神经网络为什么能通过反向传播来训练网络的原理。
3.结合信息熵理论,对二元交叉熵为何适合作为损失函数进行了探讨。
通过对本系列的学习,你可以全面的了解softmax的来龙去脉。如果你尚不了解神经网络,通过本系列的学习,你也可以学到神经网络反向传播的基本原理。学完本系列,基本神经网络原理就算式入门了,毕竟神经网络基本的网络类型就那几种,很多变种,有一通百通的特点。
网上对softmax或是神经网络反向传播知识的整理,基本都通过一个长篇大论堆积出来,一套下来面面俱到但又都不精细。本文将每个环节拆开,分别进行详细介绍,即清晰易懂,又减轻了阅读负担,增加可读性。本文也借鉴了其他作者的内容,并列举引用,希望大家在学习过程中能有所收获
本章内容提要:
从本系列第一篇文章开始学到这里时,你马上就要到达第二阶段的尾声,此时你完成了神经网络正向传播和反向传播原理的学习,了解了神经网络是如何工作的。知道了神经网络参数的自我修正原理:通过将损失函数计算得到的误差回到传网络内部,从而对网络参数进行修正。
本文介绍当网络中的权重接收到回传的误差后,如何修正权重值,以及为什么要这样修正。
一、权重更新表达式
之前的文章已经讲过,网络通过求导得到的反向传播的误差为:
![]()
先给出几个结论
在神经网络反向传播过程中,有一个概念叫学习率,表示为:
![]()
权重更新公式的表达式为:
![]()
网络层中有一个偏置项b,之前为了简化计算省略掉了,其偏导数可以直接求得,更新公式如下:
![]()
二、原理介绍
作者在学习过程中,本文的笔记做的较为详尽,读者可以直接阅读文末笔记,此处我只讲解几个关键点。
1.权重为什么要减去反向传播的误差
在写表达式的时候,权重更新是用原有权重减去反向传播的误差。但是反向传播的误差值可正可负,因此可以理解为当反向传播的误差为正时,减小权重的数值,当反向传播的误差为负时,增加权重的数值。

2.权重更新的数学意义
前面已经分析过,在神经网络中,未知数是权重W,最终输出结果是损失函数Loss,此时如果将整个神经网络看成一个函数方程式,那么很显然方程中自变量x对应的是W,因变量y对应的是Loss。这是一个关于权重和损失函数的方程。
那么Loss对W求导的数学意义就是,这个神经网络当前参数状态下,所在位置对应图像中的斜率。而这个神经网络的图像往往是不可描述的多维图像。
那我们求斜率是为了做什么?为何更新权重时要减去Loss对W的偏导数,表达式如下:
![]()
更新权重时要减去Loss对W的偏导数这个想法其实是一个误区,Loss对W的导数的用处是告诉了我们更新权重的方向,即计算的时候到底是进行加法运算还是减法运算,而真正控制权重更新数值的是学习率η,也叫步长,就是每次更新数值的大小。
虽然我们选择的学习率η始终是一个定值,但是越接近最值的时候,这个坡度就会越缓,从而导数的值就越小,也就是乘积变小了,这就是看到步长变小的缘故。
3.权重更新的几何意义
了解完代数意义,再来看看几何意义,先来看一张图,帮助回想一下高中知识——导数:
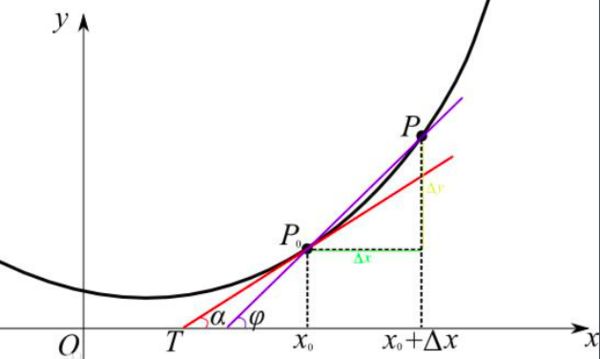
如上图所示,如果图中的点P想走到最低点,点P就要向x轴的左测移动,即要加上一个负数,此时斜率为正数,因此更新时要减去(学习率 * 偏导数)。
同理,当点P在最低点左侧时,想到到达最低点,点P需要向x轴右移动,即要加上一个正数,此时斜率为负数,因此更新时要减去(学习率 * 偏导数)。
通过求导,找到点P运动的方向(导数),在设置一个每次移动的距离(学习率η ),确定了这两个因素,我们就能一步一步的走向最低点。以上就是为了使得点P到达图中最低点,权重更新的几何意义。
下面笔记也做了描述。

三、总结
好了,现在一个完整的神经个网络流程已经呈现在我们面前:
输入→输出→softmax分类→损失函数→误差反向传播→修正权重数值→重头再来
本系列文章学到这里,基本完成了神经网络的进阶阶段,你几乎已经成为神经网络的专业人士了,解决分类预测问题更是不在话下。当然这不足以让我们满足,我们还有更高的目标,让我们从进阶阶段走向高端玩家阶段。
后面我们将学习如何对神经网络进行优化,我们会学习什么是梯度消失,什么是梯度爆炸,如何避免这些问题,学习率衰减是什么,怎么设置学习率更好,权重正则化是什么,怎么进行L1,L2正则化,什么是dropout,如何根据应用场景设计自己的损失函数,对于复杂的多层神经网络如何进行误差反向传播,如何求导,等等。是不是想想都有点小激动呢。
来吧让我们继续高端玩家进阶之路。
四、附学习笔记如下:
