Spark Streaming之window(窗口操作)
Spark Streaming 还提供了窗口的计算,它允许通过滑动窗口对数据进行转换,窗口转换操作如下图 所示:
在 Spark Streaming 中,数据处理是按批进行的,而数据采集是逐条进行的,因此在 Spark Streaming 中会先设置好批处理间隔,当超过批处理间隔的时候就会把采集到的数据汇总起来成为一批数据交给系统去处理。
对于窗口操作而言,在其窗口内部会有 N 个批处理数据,批处理数据的大小由窗口间隔决定,而窗口间隔指的就是窗口的持续时间。
在窗口操作中,只有窗口的长度满足了才会触发批数据的处理。除了窗口的长度,窗口操作还有另一个重要的参数,即滑动间隔,它指的是经过多长时间窗口滑动一次形成新的窗口。
滑动间隔默认情况下和批次间隔相同,而窗口间隔一般设置得要比它们两个大。在这里必须注意的一点是,滑动间隔和窗口间隔的大小一定得设置为批处理间隔的整数倍。
如下图所示,批处理间隔是 1 个时间单位,窗口间隔是 3 个时间单位,滑动间隔是 2 个时间单位。对于初始的窗口(time 1~time 3),只有窗口间隔满足了才会触发数据的处理。
注意:
有可能初始的窗口没有被流入的数据撑满,但是随着时间的推进/窗口最终会被撑满。每过 2 个时间单位,窗口滑动一次,这时会有新的数据流入窗口,窗口则移去最早的 2 个时间单位的数据,而与最新的 2 个时间单位的数据进行汇总形成新的窗口(time 3~ time 5)。

上图所表达的就是对每三秒钟的数据执行一次滑动窗口计算,这3秒内的3个RDD会被聚合起来进行处理,然后过了两秒钟,又会对最近三秒内的数据执行滑动窗口计算。所以每个滑动窗口操作,都必须指定两个参数,窗口长度以及滑动间隔,而且这两个参数值都必须是batch间隔的整数倍。
1. window(windowLength, slideInterval)
该操作由一个DStream对象调用,传入一个窗口长度参数,一个窗口移动速率参数,然后将当前时刻当前长度窗口中的元素取出形成一个新的DStream。
示例:
以长度为3,移动速率为1截取源DStream中的元素形成新的DStream。
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val windowCounts = words.window(Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination() 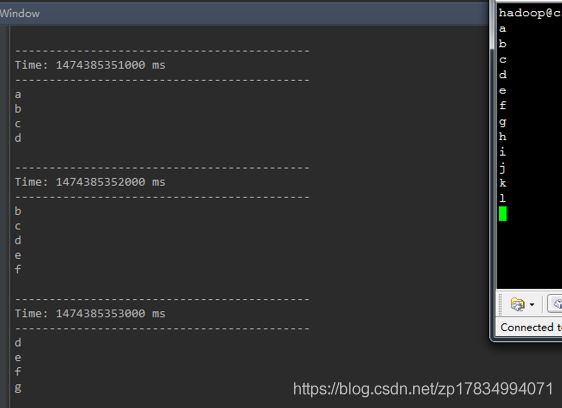
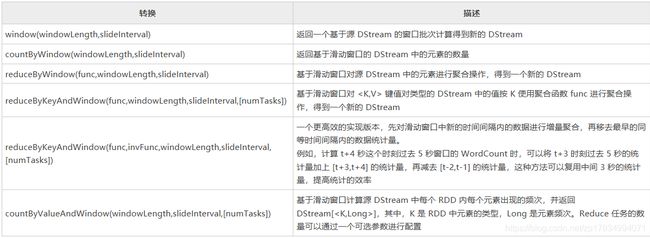
基本上每秒输入一个字母,然后取出当前时刻3秒这个长度中的所有元素,打印出来。从上面的截图中可以看到,下一秒时已经看不到a了,再下一秒,已经看不到b和c了。表示a, b, c已经不在当前的窗口中。
2. countByWindow(windowLength,slideInterval)
返回指定长度窗口中的元素个数
示例:
统计当前3秒长度的时间窗口的DStream中元素的个数:
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val windowCounts = words.countByWindow(Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination() 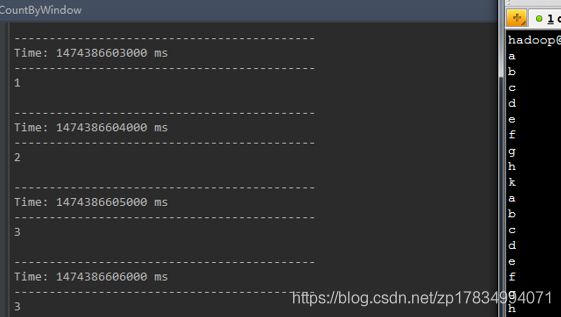
3. reduceByWindow(func, windowLength,slideInterval)
类似于上面的reduce操作,只不过这里不再是对整个调用DStream进行reduce操作,而是在调用DStream上首先取窗口函数的元素形成新的DStream,然后在窗口元素形成的DStream上进行reduce。
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val windowCounts = words.reduceByWindow(_+"-"+_,Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination() 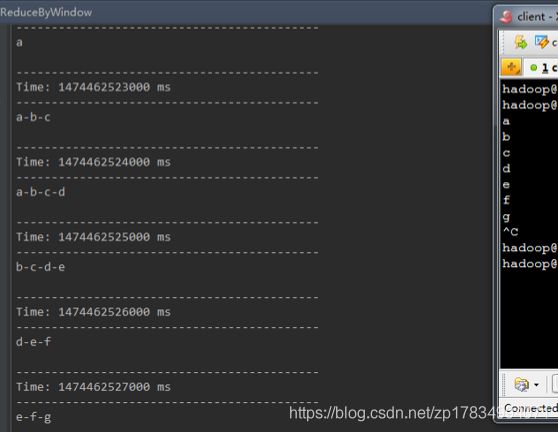
4. reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks])
调用该操作的DStream中的元素格式为(k, v),整个操作类似于前面的reduceByKey,只不过对应的数据源不同,reduceByKeyAndWindow的数据源是基于该DStream的窗口长度中的所有数据。该操作也有一个可选的并发数参数。
示例:
将当前长度为3的时间窗口中的所有数据元素根据key进行合并,统计当前3秒中内不同单词出现的次数。
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val pairs = words.map(x => (x, 1))
val windowCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int)=>(a+b),Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination()

5.reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks])
这个窗口操作和上一个的区别是多传入一个函数invFunc。前面的func作用和上一个reduceByKeyAndWindow相同,后面的invFunc是用于处理流出rdd的。
如果把3秒的时间窗口当成一个公交车,每一秒都会有上或者下,那么第一个函数表示每上来一个人,就在该公交车上人数的基础上的数量累加一个人。而第二个函数表示每下去一个人,就在该公交车上人数的总数量上减去一个人。
示例:
最终的结果是该3秒长度的窗口中历史上出现过的所有不同单词个数都为0。
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val pairs = words.map(x => (x, 1))
val windowCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int)=>(a+b),(a:Int,b:Int)=>(a-b),Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination() 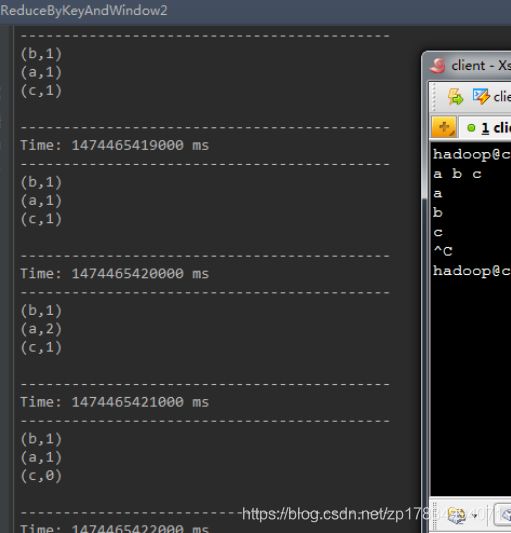
一段时间不输入任何信息,最终结果如下:
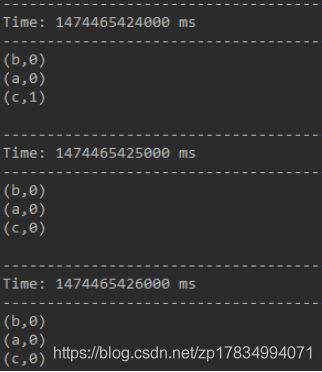
6.countByValueAndWindow(windowLength,slideInterval, [numTasks])
类似于前面的countByValue操作,调用该操作的DStream数据格式为(K, v),返回的DStream格式为(K, Long)。统计当前时间窗口中元素值相同的元素的个数。
示例:
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val windowCounts = words.countByValueAndWindow(Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination() 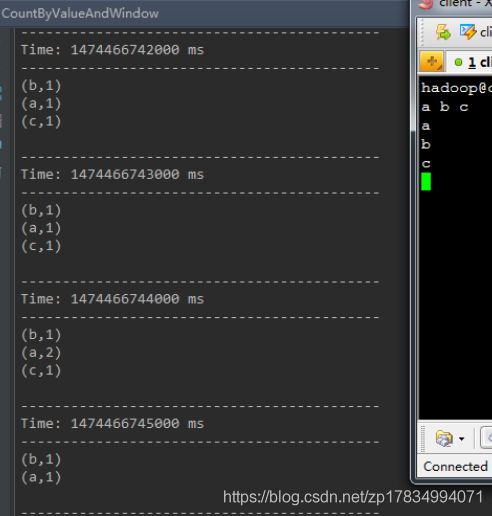
示例:
热点搜索词滑动统计,每隔10秒钟,统计最近60秒钟的搜索词的搜索频次,并打印出排名最靠前的3个搜索词以及出现次数
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val pairs = words.map(x => (x, 1))
val windowCounts = pairs.reduceByKeyAndWindow((v1: Int, v2: Int) => (v1 + v2), Seconds(60), Seconds(10))
// reduceByKeyAndWindow
// 第二个参数,是窗口长度,这是是60秒
// 第三个参数,是滑动间隔,这里是10秒
// 也就是说,每隔10秒钟,将最近60秒的数据,作为一个窗口,进行内部的RDD的聚合,然后统一对一个RDD进行后续计算
// 而是只是放在那里
// 然后,等待我们的滑动间隔到了以后,10秒到了,会将之前60秒的RDD,因为一个batch间隔是5秒,所以之前60秒,就有12个RDD,给聚合起来,然后统一执行reduceByKey操作
// 所以这里的reduceByKeyAndWindow,是针对每个窗口执行计算的,而不是针对 某个DStream中的RDD // 每隔10秒钟,出来 之前60秒的收集到的单词的统计次数
val finalDStream = windowCounts.transform(searchWordCountsRDD => {
val countSearchWordsRDD = searchWordCountsRDD.map(tuple => (tuple._2, tuple._1))
val sortedCountSearchWordsRDD = countSearchWordsRDD.sortByKey(false)
val sortedSearchWordCountsRDD = sortedCountSearchWordsRDD.map(tuple => (tuple._1, tuple._2))
val top3SearchWordCounts = sortedSearchWordCountsRDD.take(3) for (tuple <- top3SearchWordCounts) {
println("result : " + tuple) //打印前三名的词
}
searchWordCountsRDD
})
finalDStream.print() //打印出窗口期全部单词
ssc.start()
ssc.awaitTermination()
}
}