SparkStreaming(六)操作函数之Window Operations
目录:
5.2、Window Operations
5.2.1、window(windowLength, slideInterval)
5.2.2、countByWindow(windowLength,slideInterval)
5.2.3、reduceByWindow(func, windowLength, slideInterval)
5.2.4、reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
5.2.5、reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
5.2.6、countByValueAndWindow(windowLength, slideInterval, [numTasks])
5.2、Window Operations
窗口函数,就是在DStream流上,以一个可配置的长度为窗口,以一个可配置的速率向前移动窗口,根据窗口函数的具体内容,分别对当前窗口中的这一波数据采取某个对应的操作算子。需要注意的是窗口长度,和窗口移动速率需要是batch time的整数倍。接下来演示Spark Streaming中提供的主要窗口函数。
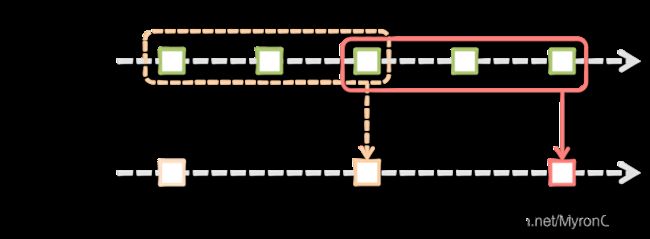
图:滑动窗口的工作方式
如图所示,每当窗口滑过originalDStream时,落在窗口内的源RDD被组合并被执行操作以产生windowed DStream的RDD。在上面的例子中,操作应用于最近3个时间单位的数据,并以2个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
窗口长度(windowLength):窗口的时间长度(上图的示例为3)。
滑动间隔(slidingInterval):两次相邻的窗口操作的间隔,即每次滑动的时间长度(上图的示例中为2)。
这两个参数必须是源DStream的批间隔的倍数(上图示例中为1)
一些常用的窗口操作如下表所示:所有这些操作都用到了上述两个参数 - windowLength和slideInterval。
| Transformation |
Meaning |
| window(windowLength, slideInterval) |
返回基于源DStream的窗口批次计算而得到的新DStream。 |
| countByWindow(wind owLength, slideInterval) |
返回基于滑动窗口的数据流中的元素个数。 |
| reduceByWindow(fun c, windowLength, slide Interval) |
使用func在滑动间隔中聚合数据流中的元素,生成一个新的“单元素”数据流并返回。该函数应该是associative and commutative,从而可以并行的执行计算。 |
| reduceByKeyAndWin dow(func, invFunc, win dowLength, slideInterv al, [numTasks]) |
当包含(K,V)对的DStream进行调用时,返回包含(K,V)对的新DStream,其中每个键对应的所有值在滑动窗口的所有batch中使用给定的reduce函数func进行聚合。注意:默认情况下,它使用Spark的默认并行任务数(本地模式下为2,群集模式中的并行度由spark.default.parallelism属性确指定)进行分组。 您可以传递一个可选的numTasks参数来设置不同并行度。 |
| reduceByKeyAndWin dow(func, invFunc, win dowLength, slideInterv al, [numTasks]) |
上述reduceByKeyAndWindow() 的更高效的版本,其中使用前一窗口的reduce计算结果递增地计算每个窗口的reduce值。这是通过对进入滑动窗口的新数据进行reduce操作,以及“逆减(inverse reducing)”离开窗口的旧数据来完成的。一个例子是当窗口滑动时对键对应的值进行“一加一减”操作。但是,它仅适用于“可逆减函数(invertible reduce functions)”,即具有相应“反减”功能的减函数(作为参数invFunc)。 像reduceByKeyAndWindow一样,通过可选参数可以配置reduce任务的数量。 请注意,使用此操作必须启用检查点。 |
| countByValueAndWin dow(windowLength,sli deInterval, [numTasks]) |
当对包含(K,V)对的DStream调用时,返回(K,Long)对的新DStream,其中每个键的值是其滑动窗口内的出现频数。像reduceByKeyAndWindow一样,通过可选参数可以配置reduce任务的数量。 |
5.2.1、window(windowLength, slideInterval)
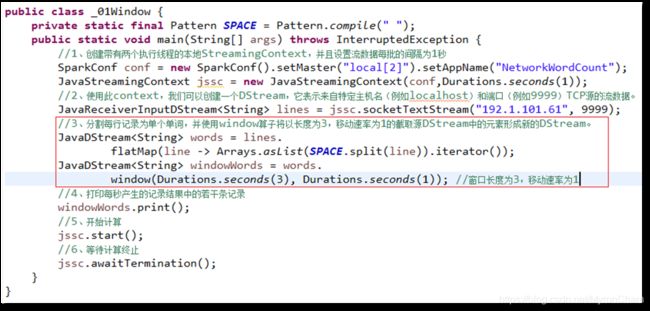
该操作由一个DStream对象调用,传入一个窗口长度参数,一个窗口移动速率参数,然后将当前时刻当前长度窗口中的元素取出形成一个新的DStream。
下面的示例以长度为3,移动速率为1截取源DStream中的元素形成新的DStream。
JavaDStream
服务端:
客户端:
结果:

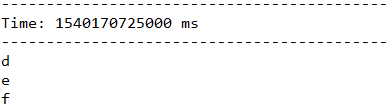
…….
大致上每秒输入一个字母,然后取出当前时刻3秒这个长度中的所有元素,打印出来。从上面的截图中可以看到,下一秒时已经看不到a,b了,再下一秒,已经看不到b和c了。表示a, b, c已经不在当前的窗口中。
5.2.2、countByWindow(windowLength,slideInterval)
返回指定长度窗口中的元素个数。
代码如下,统计当前3秒长度的时间窗口的DStream中元素的个数:
JavaDStream
客户端:

服务端:
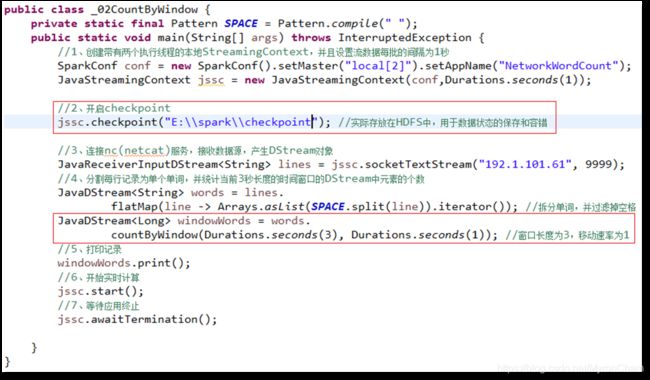
结果:





。。。。
5.2.3、reduceByWindow(func, windowLength, slideInterval)
类似于上面的reduce操作,只不过这里不再是对整个调用DStream进行reduce操作,而是在调用DStream上首先取窗口函数的元素形成新的DStream,然后在窗口元素形成的DStream上进行reduce。
代码如下:
JavaDStream
服务端:
客户端:
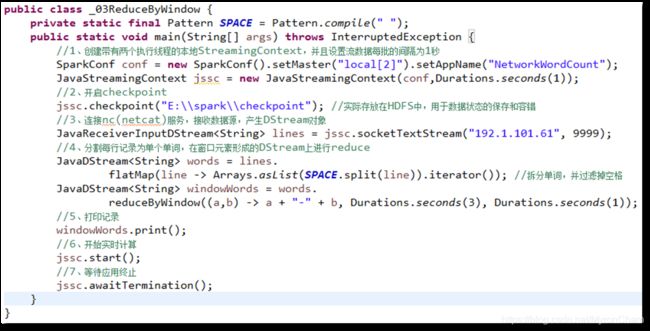
结果:





5.2.4、reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
调用该操作的DStream中的元素格式为(k, v),整个操作类似于前面的reduceByKey,只不过对应的数据源不同,reduceByKeyAndWindow的数据源是基于该DStream的窗口长度中的所有数据。该操作也有一个可选的并发数参数。
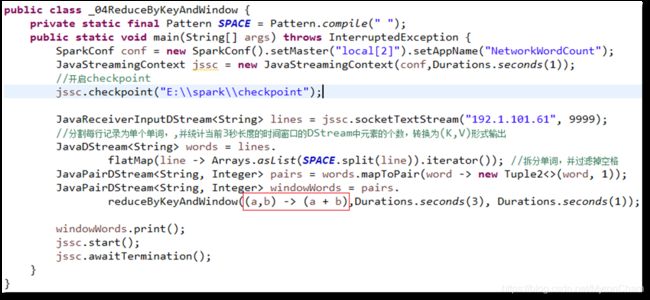
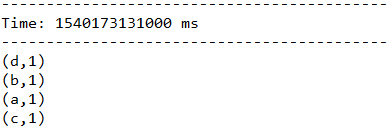
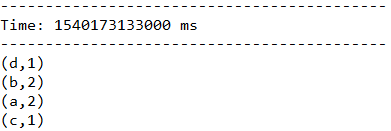
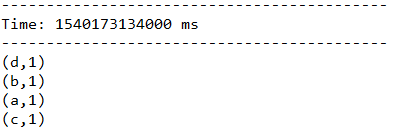
下面代码中,将当前长度为3的时间窗口中的所有数据元素根据key进行合并,统计当前3秒中内不同单词出现的次数。
JavaPairDStream
(a + b),Durations.seconds(3), Durations.seconds(1));
服务端:
客户端:
结果:
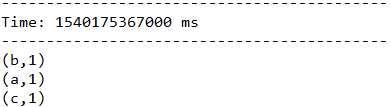
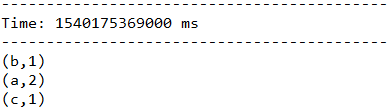
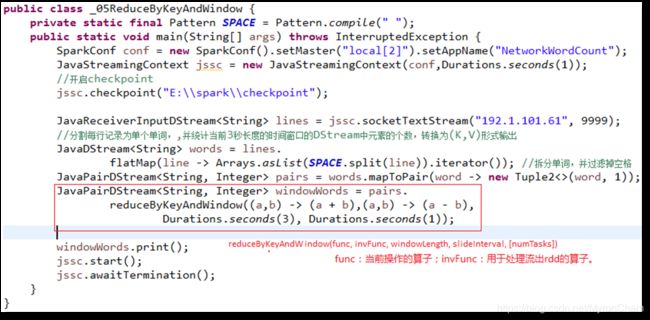
5.2.5、reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
这个窗口操作和上一个的区别是多传入一个函数invFunc。前面的func作用和上一个reduceByKeyAndWindow相同,后面的invFunc是用于处理流出rdd的。
在下面这个例子中,如果把3秒的时间窗口当成一个池塘,池塘每一秒都会有鱼游进或者游出,那么第一个函数表示每游进来一条鱼,就在该类鱼的数量上累加。而第二个函数是,每游出去一条鱼,就将该鱼的总数减去一。
服务端:
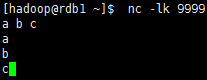
客户端:
结果:

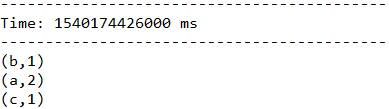
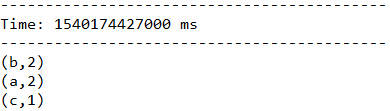
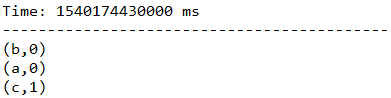
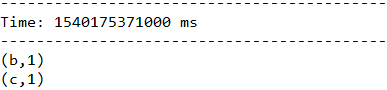
一段时间不输入任何信息,看一下最终结果:
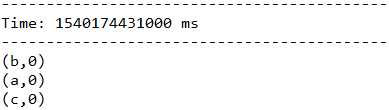
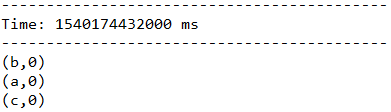
5.2.6、countByValueAndWindow(windowLength, slideInterval, [numTasks])
类似于前面的countByValue操作,调用该操作的DStream数据格式为(K, v),返回的DStream格式为(K, Long)。统计当前时间窗口中元素值相同的元素的个数。
服务端:
客户端:

结果: