什么是 TF-IDF 算法?

这里写目录标题
-
- 什么是 TF-IDF 算法?
-
-
- 概念例子2
-
- TF-IDF 的4个变种
-
- 变种1:通过对数函数避免 TF 线性增长
- 用 Log,也就是对数函数,对 TF 进行变换,就是一个不让 TF 线性增长的技巧。
- 变种2:标准化解决长文档、短文档问题**
- 变种3:对数函数处理 IDF
-
- 实例1笔算
- 实例2 笔算+机算
- 优点
- 缺点
- 代码
-
- python简易实现
- 待更新 Sklearn的tfidf....
- TF-IDF 的历史
什么是 TF-IDF 算法?
简单来说,向量空间模型就是希望把查询关键字和文档都表达成向量,然后利用向量之间的运算来进一步表达向量间的关系。比如,一个比较常用的运算就是计算查询关键字所对应的向量和文档所对应的向量之间的 “相关度”。
 简单解释TF-IDF
简单解释TF-IDF
TF(t)= 该词语在当前文档出现的次数 / 当前文档中词语的总数
IDF(t)= log_e(文档总数 / 出现该词语的文档总数)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1omRRgZo-1595688285492)(C:\Users\86182\AppData\Roaming\Typora\typora-user-images\image-20200725223236625.png)]
TF (Term Frequency)—— “单词频率”
意思就是说,我们计算一个查询关键字中某一个单词在目标文档中出现的次数。举例说来,如果我们要查询 “Car Insurance”,那么对于每一个文档,我们都计算“Car” 这个单词在其中出现了多少次,“Insurance”这个单词在其中出现了多少次。这个就是 TF 的计算方法。
TF 背后的隐含的假设是,查询关键字中的单词应该相对于其他单词更加重要,而文档的重要程度,也就是相关度,与单词在文档中出现的次数成正比。比如,“Car” 这个单词在文档 A 里出现了 5 次,而在文档 B 里出现了 20 次,那么 TF 计算就认为文档 B 可能更相关。
然而,信息检索工作者很快就发现,仅有 TF 不能比较完整地描述文档的相关度。因为语言的因素,有一些单词可能会比较自然地在很多文档中反复出现,比如英语中的 “The”、“An”、“But” 等等。这些词大多起到了链接语句的作用,是保持语言连贯不可或缺的部分。然而,如果我们要搜索 “How to Build A Car” 这个关键词,其中的 “How”、“To” 以及 “A” 都极可能在绝大多数的文档中出现,这个时候 TF 就无法帮助我们区分文档的相关度了。
IDF(Inverse Document Frequency)—— “逆文档频率”
就在这样的情况下应运而生。这里面的思路其实很简单,那就是我们需要去 “惩罚”(Penalize)那些出现在太多文档中的单词。
也就是说,真正携带 “相关” 信息的单词仅仅出现在相对比较少,有时候可能是极少数的文档里。这个信息,很容易用 “文档频率” 来计算,也就是,有多少文档涵盖了这个单词。很明显,如果有太多文档都涵盖了某个单词,这个单词也就越不重要,或者说是这个单词就越没有信息量。因此,我们需要对 TF 的值进行修正,而 IDF 的想法是用 DF 的倒数来进行修正。倒数的应用正好表达了这样的思想,DF 值越大越不重要。
TF-IDF 算法主要适用于英文,中文首先要分词,分词后要解决多词一义,以及一词多义问题,这两个问题通过简单的tf-idf方法不能很好的解决。于是就有了后来的词嵌入方法,用向量来表征一个词。
概念例子2
假设有一篇长文叫做《量化系统架构设计》词频高在文章中往往是停用词,“的”,“是”,“了”等,这些在文档中最常见但对结果毫无帮助、需要过滤掉的词,用TF可以统计到这些停用词并把它们过滤。当高频词过滤后就只需考虑剩下的有实际意义的词。
但这样又会遇到了另一个问题,我们可能发现"量化"、“系统”、"架构"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?事实上系统应该在其他文章比较常见,所以在关键词排序上,“量化”和“架构”应该排在“系统”前面,这个时候就需要IDF,IDF会给常见的词较小的权重,它的大小与一个词的常见程度成反比。
TF-IDF 的4个变种
 TF-IDF常见的4个变种
TF-IDF常见的4个变种
变种1:通过对数函数避免 TF 线性增长
很多人注意到 TF 的值在原始的定义中没有任何上限。虽然我们一般认为一个文档包含查询关键词多次相对来说表达了某种相关度,但这样的关系很难说是线性的。拿我们刚才举过的关于 “Car Insurance” 的例子来说,文档 A 可能包含 “Car” 这个词 100 次,而文档 B 可能包含 200 次,是不是说文档 B 的相关度就是文档 A 的 2 倍呢?其实,很多人意识到,超过了某个阈值之后,这个 TF 也就没那么有区分度了。
用 Log,也就是对数函数,对 TF 进行变换,就是一个不让 TF 线性增长的技巧。
具体来说,人们常常用 1+Log(TF) 这个值来代替原来的 TF 取值。在这样新的计算下,假设 “Car” 出现一次,新的值是 1,出现 100 次,新的值是 5.6,而出现 200 次,新的值是 6.3。很明显,这样的计算保持了一个平衡,既有区分度,但也不至于完全线性增长。
变种2:标准化解决长文档、短文档问题**
经典的计算并没有考虑 “长文档” 和“短文档”的区别。一个文档 A 有 3,000 个单词,一个文档 B 有 250 个单词,很明显,即便 “Car” 在这两个文档中都同样出现过 20 次,也不能说这两个文档都同等相关。对 TF 进行 “标准化”(Normalization),特别是根据文档的最大 TF 值进行的标准化,成了另外一个比较常用的技巧。
变种3:对数函数处理 IDF
第三个常用的技巧,也是利用了对数函数进行变换的,是对 IDF 进行处理。相对于直接使用 IDF 来作为 “惩罚因素”,我们可以使用 N+1 然后除以 DF 作为一个新的 DF 的倒数,并且再在这个基础上通过一个对数变化。这里的 N 是所有文档的总数。这样做的好处就是,第一,使用了文档总数来做标准化,很类似上面提到的标准化的思路;第二,利用对数来达到非线性增长的目的。
变种4:查询词及文档向量标准化
还有一个重要的 TF-IDF 变种,则是对查询关键字向量,以及文档向量进行标准化,使得这些向量能够不受向量里有效元素多少的影响,也就是不同的文档可能有不同的长度。在线性代数里,可以把向量都标准化为一个单位向量的长度。这个时候再进行点积运算,就相当于在原来的向量上进行余弦相似度的运算。所以,另外一个角度利用这个规则就是直接在多数时候进行余弦相似度运算,以代替点积运算。
实例1笔算
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4DS7Yfvw-1595688285494)(C:\Users\86182\AppData\Local\Temp\ScreenClip.png)]
实例2 笔算+机算
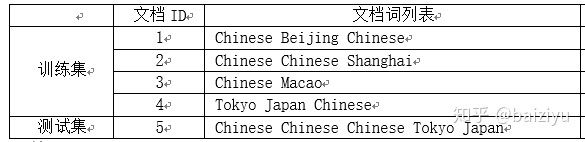
**训练,**构建词汇表以及idf值,这里同时生成训练集的VSM矩阵
# 导入TfidfVectorizer
In [2]: from sklearn.feature_extraction.text import TfidfVectorizer
# 实例化tf实例
In [3]: tv = TfidfVectorizer(use_idf=True, smooth_idf=True, norm=None)
# 输入训练集矩阵,每行表示一个文本
In [4]: train = ["Chinese Beijing Chinese",
...: "Chinese Chinese Shanghai",
...: "Chinese Macao",
...: "Tokyo Japan Chinese"]
...:
# 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式
In [6]: tv_fit = tv.fit_transform(train)
# 查看一下构建的词汇表
In [10]: tv.get_feature_names()
Out[10]: ['beijing', 'chinese', 'japan', 'macao', 'shanghai', 'tokyo']
# 查看输入文本列表的VSM矩阵
In [8]: tv_fit.toarray()
Out[8]:
array([[1.91629073, 2. , 0. , 0. , 0. , 0. ],
[0. , 2. , 0. , 0. , 1.91629073, 0. ],
[0. , 1. , 0. , 1.91629073, 0. , 0. ],
[0. , 1. , 1.91629073, 0. , 0. , 1.91629073]])
手动计算一下第一篇文本的Beijing和Chinese两个词语的tf-idf值
# 词语beijing的在第1篇文本中的频次为.0,tf(beijing,d1)=1.0
# 词语beijing只在第1篇文本中出现过df(d,beijing)=1,nd=4,
# 代入平滑版的tf-idf计算式得到1.9
In [13]: 1.0*(1+log((4+1)/(1+1)))
Out[13]: 1.916290731874155
# 词语chinese的在第1篇文本中的频次为2.0,tf(chinese,d1)=2.0
# 词语chinese只在4篇文本中都出现过df(d,beijing)=4,nd=4,
# 代入平滑版的tf-idf计算式得到2.0
In [14]: 2.0*(1+log(4/4))
Out[14]: 2.0
上边得到的矩阵就可以喂到后续的线性分类模型中进行训练了,注意要带每篇文本的类别标记呦。
下边看一下测试文本的表示
In [15]: test = ["Chinese Chinese Chinese Tokyo Japan"]
In [16]: test_fit = tv.transform(test)
In [19]: tv.get_feature_names()
Out[19]: ['beijing', 'chinese', 'japan', 'macao', 'shanghai', 'tokyo']
In [18]: test_fit.toarray()
Out[18]:
array([[0. , 3. , 1.91629073, 0. , 0. , 1.91629073]])
手动计算一下Chinese和Japan这两个词项的tf-idf值
# chinese词项在测试文本中出现了3次,因此tf(chinese,t)=3
# 从训练集知道chinese在4篇文本中都出现,因此df(d,beijing)=4,nd=4
# 计算得到tf-idf值
In [22]: 3.0*(1+log((1+4)/(1+4)))
Out[22]: 3.0
# japan词项在测试文本中出现了1次,因此tf(japan,t)=1
# 从训练集知道japan仅在第4篇文本中出现,因此df(d,japan)=1,nd=4
# 计算得到文本的tf-idf值
In [21]: 1.0*(1+log((1+4)/(1+1)))
Out[21]: 1.916290731874155
优点
是简单快速,而且容易理解。
提供了基于频次的特征选择。
缺点
有时候用词频来衡量文章中的一个词的重要性不够全面?有时候重要的词出现的可能不够多,
这种计算无法体现位置信息,无法体现词在上下文的重要性。
逆文档频率并没有考虑类词项在类别间的分布。idf值只是考虑了词项在所有文本间的分布特性,这里并不涉及类别,因此TfidfVectorizer的输入也不需要提供类别信息。
为什么SVM下效果不如朴素贝叶斯,因为朴素贝叶斯根本会使用到文本的VSM表示,朴素贝叶斯计算的是P(word|Ci)即在某个类别下词语word出现的概率,当然这就比one-hot表示文本给予更多的信息,SVM利用向量空间的最优超平面来分类,如果不同类别文本之间本身就相距不远的化,这种超平面也就找不到,当然效果就不好,矛盾的地方就在于没有人能知道多于3维特征的实例在x维空间中是个什么样子,当然也就不知道效果到底好不好了。其实如果仅保留了各类目的核心关键词,对于一句短文本同时含有两种类目关键词时,SVM恐怕也会失效,最致命的缺陷其实不是模型,而是VSM的TF频次在短文本上失效,机器不能再通过频次来确定短文本的主题,这么说来,那么词嵌入技术也是无法表示文本主题的。
代码
python简易实现
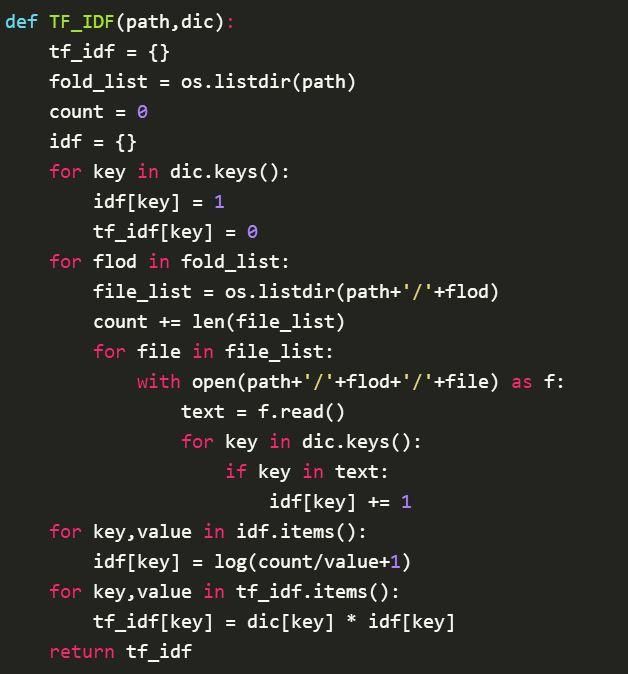
待更新 Sklearn的tfidf…
TF-IDF 的历史
把查询关键字(Query)和文档(Document)都转换成 “向量”,并且尝试用线性代数等数学工具来解决信息检索问题,这样的努力至少可以追溯到 20 世纪 70 年代。
1971 年,美国康奈尔大学教授杰拉德 · 索尔顿(Gerard Salton)发表了《SMART 检索系统:自动文档处理实验》(The SMART Retrieval System—Experiments in Automatic Document Processing)一文,文中首次提到了把查询关键字和文档都转换成 “向量”,并且给这些向量中的元素赋予不同的值。这篇论文中描述的 SMART 检索系统,特别是其中对 TF-IDF 及其变种的描述成了后续很多工业级系统的重要参考。
1972 年,英国的计算机科学家卡伦 · 琼斯(Karen Spärck Jones)在《从统计的观点看词的特殊性及其在文档检索中的应用》(A Statistical Interpretation of Term Specificity and Its Application in Retrieval) 一文中第一次详细地阐述了 IDF 的应用。其后卡伦又在《检索目录中的词赋值权重》(Index Term Weighting)一文中对 TF 和 IDF 的结合进行了论述。可以说,卡伦是第一位从理论上对 TF-IDF 进行完整论证的计算机科学家,因此后世也有很多人把 TF-IDF 的发明归结于卡伦。
杰拉德本人被认为是 “信息检索之父”。他 1927 年出生于德国的纽伦堡,并与 1950 年和 1952 年先后从纽约的布鲁克林学院获得数学学士和硕士学位,1958 年从哈佛大学获得应用数学博士学位,之后来到康奈尔大学参与组建计算机系。为了致敬杰拉德本人对现代信息检索技术的卓越贡献,现在,美国计算机协会 ACM(Association of Computing Machinery)每三年颁发一次“杰拉德 · 索尔顿奖”(Gerard Salton Award),用于表彰对信息检索技术有突出贡献的研究人员。卡伦 · 琼斯在 1988 年获得了第二届“杰拉德 · 索尔顿奖” 的殊荣。
本文参考:
- 《AI 技术内参》
- https://zhuanlan.zhihu.com/p/67883024
- https://zhuanlan.zhihu.com/p/31197209
- https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
- https://blog.csdn.net/blmoistawinde/article/details/80816179
ihu.com/p/31197209 - https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
- https://blog.csdn.net/blmoistawinde/article/details/80816179
- https://scikit-learn.org/stable/auto_examples/text/plot_document_classification_20newsgroups.html#sphx-glr-auto-examples-text-plot-document-classification-20newsgroups-py