NLP工具——NLTK 安装及使用
文章目录
- 1、介绍
- 2、安装
- 2.1 安装NLTK
- 2.2 安装NLTK Data
- 交互式安装
- 通过命令行安装
- 手动安装
- 3、Demo
- 4、使用
- 4.1 搜索文本(Searching Text)
- 4.2 统计词频
- 4.3 WordNet
1、介绍
【官网】Natural Language Toolkit — NLTK 3.4.4 documentation
【github】NLTK Source
NLTK最初成立于2001年,是宾夕法尼亚大学计算机与信息科学系计算语言学课程的一部分。从那时起,它已经在数十个贡献者的帮助下得到了发展和扩展。它现已在数十所大学的课程中采用,并作为许多研究项目的基础。
NLTK(Natural Language Toolkit)是构建Python程序以使用人类语言数据的领先平台。它为50多种语料库和词汇资源(如WordNet)提供了易于使用的界面,还提供了一套用于分类,标记化,词干化,标记,解析和语义推理的文本处理库,用于工业级NLP库的包装器。
NLTK适用于语言学家,工程师,学生,教育工作者,研究人员和行业用户等。NLTK适用于Windows,Mac OS X和Linux。最重要的是,NLTK是一个免费的,开源的,社区驱动的项目。
NLTK被称为“使用Python进行教学和计算语言学工作的绝佳工具”,以及“用自然语言进行游戏的神奇图书馆”。
语言处理任务和相应的NLTK模块以及功能示例:
| 语言处理任务 | NLTK 模块 | 功能 |
|---|---|---|
| Accessing corpora | corpus | standardized interfaces to corpora and lexicons |
| String processing | tokenize, stem | tokenizers, sentence tokenizers, stemmers |
| Collocation discovery | collocations | t-test, chi-squared, point-wise mutual information |
| Part-of-speech tagging | tag | n-gram, backoff, Brill, HMM, TnT |
| Machine learning | classify, cluster, tbl | decision tree, maximum entropy, naive Bayes, EM, k-means |
| Chunking chunk | regular | expression, n-gram, named-entity |
| Parsing | parse, ccg | chart, feature-based, unification, probabilistic, dependency |
| Semantic interpretation | sem, inference | lambda calculus, first-order logic, model checking |
| Evaluation metrics | metrics | precision, recall, agreement coefficients |
| Probability and estimation | probability | frequency distributions, smoothed probability distributions |
| Applications | app, chat | graphical concordancer, parsers, WordNet browser, chatbots |
| Linguistic fieldwork | toolbox | manipulate data in SIL Toolbox format |
NLTK设计目标:
- 简单性
- 一致性
- 可扩展性
- 模块化
2、安装
NLTK支持Python 2.7, 3.5, 3.6, 3.7,对于windows用户强烈推荐Python3版本。
对于Unix系统
2.1 安装NLTK
pip install --user -U nltk
测试是否安装:
import nltk
2.2 安装NLTK Data
安装NLTK软件包后,请安装必要的数据集/模型以使特定功能正常工作。
如果您不确定需要哪些数据集/模型,可以在命令行类型python -m nltk.downloader上安装“popular”的NLTK数据子集,或者在Python解释器里通过如下命令安装
import nltk
nltk.download(“popular”)
NLTK附带了许多语料库,玩具语法,训练模型等。完整列表发布在:nltk_data
除了单独的数据包,您可以下载整个集合(使用“all”),或者只下载书中示例和练习所需的数据(使用“book”),或者只下载语料库,无需语法或训练模型(使用“all-corpora”)。
交互式安装
使用如下代码:
>>> import nltk
>>> nltk.download()
会打开一个新窗口,显示NLTK Downloader。单击“文件”菜单,然后选择“更改下载目录”。对于集中安装,请将其设置为C:\ nltk_data(Windows),/ usr / local / share / nltk_data(Mac)或/ usr / share / nltk_data(Unix)。接下来,选择要下载的包或集合。
如果未将数据安装到上述中心位置之一,则需要设置NLTK_DATA环境变量以指定数据的位置。(在Windows计算机上,右键单击“我的电脑”,然后选择“属性”>“高级”>“环境变量”>“用户变量”>“新建…”)

通过代理Web服务器安装
如果您的Web连接使用代理服务器,则应指定代理地址,如下所示。如果是身份验证代理,请指定用户名和密码。如果代理设置为None,则此函数将尝试检测系统代理。
>>> nltk.set_proxy('http://proxy.example.com:3128', ('USERNAME', 'PASSWORD'))
>>> nltk.download()
通过命令行安装
下载程序将搜索现有的nltk_data目录以安装NLTK数据。如果不存在,它将尝试在中心位置(使用管理员帐户时)或在用户的文件空间中创建一个。如有必要,请从管理员帐户或使用sudo运行下载命令。推荐的系统位置是C:\nltk_data(Windows);/usr/local/share/nltk_data(Mac);和/usr/share/nltk_data(Unix)。您可以使用-d标志指定其他位置(但如果执行此操作,请确保相应地设置NLTK_DATA环境变量)。
安装命令行:
python -m nltk.downloader all
central installation
sudo python -m nltk.downloader -d /usr/local/share/nltk_data all.
手动安装
创建一个文件夹nltk_data,比如 C:\nltk_data, 或者/usr/local/share/nltk_data, 以及子文件夹chunkers, grammars, misc, sentiment, taggers, corpora, help, models, stemmers, tokenizers.
从nltk_data下载对应的包,解压至对应文件夹。
将NLTK_DATA环境变量设置为指向顶级nltk_data文件夹。
3、Demo
分词、词性标注
>>> import nltk
>>> sentence = """At eight o'clock on Thursday morning
... Arthur didn't feel very good."""
>>> tokens = nltk.word_tokenize(sentence)
>>> tokens
['At', 'eight', "o'clock", 'on', 'Thursday', 'morning',
'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
>>> tagged = nltk.pos_tag(tokens)
>>> tagged[0:6]
[('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'),
('Thursday', 'NNP'), ('morning', 'NN')]
命名识别识别
>>> entities = nltk.chunk.ne_chunk(tagged)
>>> entities
Tree('S', [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'),
('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'),
Tree('PERSON', [('Arthur', 'NNP')]),
('did', 'VBD'), ("n't", 'RB'), ('feel', 'VB'),
('very', 'RB'), ('good', 'JJ'), ('.', '.')])
显示分析树
>>> from nltk.corpus import treebank
>>> t = treebank.parsed_sents('wsj_0001.mrg')[0]
>>> t.draw()

4、使用
具体使用可参考: NLTK Book
4.1 搜索文本(Searching Text)
使用nltk.book中的文本
from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
# 搜索'moustrous'
text1.concordance('moustrous')
第一次对特定文本使用concordance时,构建索引需要几秒钟,以便后续搜索速度很快。
相似文本
使用similar查找相似词语
>>> text1.similar("monstrous")
mean part maddens doleful gamesome subtly uncommon careful untoward
exasperate loving passing mouldy christian few true mystifying
imperial modifies contemptible
>>> text2.similar("monstrous")
very heartily so exceedingly remarkably as vast a great amazingly
extremely good sweet
common_contexts只查找两个或多于两个单词共享的上下文,使用方括号括起来
>>> text2.common_contexts(["monstrous", "very"])
a_pretty is_pretty am_glad be_glad a_lucky
通过色散图显示特定单词在文本中出现的位置信息
我们还可以确定文本中单词的位置:从一开始就显示多少个单词。可以使用色散图显示该位置信息。每个条带代表一个单词的实例,每行代表整个文本。
>>> text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])

4.2 统计词频
获取文本长度
>>>len(text3)
>44764
上述结果指的是文本中所有tokens的总数,包含重复字符。
获取文本单词量
>>> sorted(set(text3))
['!', "'", '(', ')', ',', ',)', '.', '.)', ':', ';', ';)', '?', '?)',
'A', 'Abel', 'Abelmizraim', 'Abidah', 'Abide', 'Abimael', 'Abimelech',
'Abr', 'Abrah', 'Abraham', 'Abram', 'Accad', 'Achbor', 'Adah', ...]
>>> len(set(text3))
2789
特定单词的频率
>>> text3.count("smote")
5
>>> 100 * text4.count('a') / len(text4)
1.4643016433938312
>>>
将本文视为一系列单词和标点符号。
频率分布
统计文本中每个词汇的频率,使用FreqDist函数。most_common(num) 是表示频率最高的50个单词
>>> fdist1 = FreqDist(text1)
>>> print(fdist1)
<FreqDist with 19317 samples and 260819 outcomes>
>>> fdist1.most_common(50)
[(',', 18713), ('the', 13721), ('.', 6862), ('of', 6536), ('and', 6024),
('a', 4569), ('to', 4542), (';', 4072), ('in', 3916), ('that', 2982),
("'", 2684), ('-', 2552), ('his', 2459), ('it', 2209), ('I', 2124),
('s', 1739), ('is', 1695), ('he', 1661), ('with', 1659), ('was', 1632),
('as', 1620), ('"', 1478), ('all', 1462), ('for', 1414), ('this', 1280),
('!', 1269), ('at', 1231), ('by', 1137), ('but', 1113), ('not', 1103),
('--', 1070), ('him', 1058), ('from', 1052), ('be', 1030), ('on', 1005),
('so', 918), ('whale', 906), ('one', 889), ('you', 841), ('had', 767),
('have', 760), ('there', 715), ('But', 705), ('or', 697), ('were', 680),
('now', 646), ('which', 640), ('?', 637), ('me', 627), ('like', 624)]
>>> fdist1['whale']
906
我们可以使用fdist1.plot(50,cumulative = True)生成这些单词的累积频率图
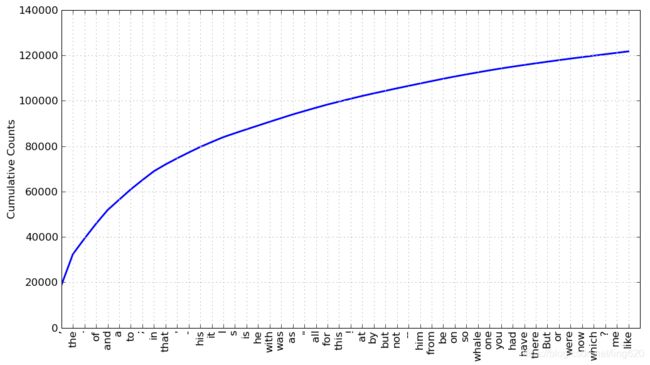
Collocations和Bigrams
提取单词对
>>>list(bigrams(['more', 'is', 'said', 'than', 'done']))
[('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')]
>>>
根据单个词的频率找到更为频繁发生的二元词组
使用collocations函数
>>> text4.collocations()
United States; fellow citizens; four years; years ago; Federal
Government; General Government; American people; Vice President; Old
World; Almighty God; Fellow citizens; Chief Magistrate; Chief Justice;
God bless; every citizen; Indian tribes; public debt; one another;
foreign nations; political parties
>>> text8.collocations()
would like; medium build; social drinker; quiet nights; non smoker;
long term; age open; Would like; easy going; financially secure; fun
times; similar interests; Age open; weekends away; poss rship; well
presented; never married; single mum; permanent relationship; slim
build
>>>
NTKL中频率分布函数
| Example | Description |
|---|---|
| fdist = FreqDist(samples) | create a frequency distribution containing the given samples |
| fdist[sample] += 1 | increment the count for this sample |
| fdist[‘monstrous’] | count of the number of times a given sample occurred |
| fdist.freq(‘monstrous’) | frequency of a given sample |
| fdist.N() | total number of samples |
| fdist.most_common(n) | the n most common samples and their frequencies |
| for sample in fdist: | iterate over the samples |
| fdist.max() | sample with the greatest count |
| fdist.tabulate() | tabulate the frequency distribution |
| fdist.plot() | graphical plot of the frequency distribution |
| fdist.plot(cumulative=True) | cumulative plot of the frequency distribution |
| fdist1 | = fdist2 |
| fdist1 < fdist2 | test if samples in fdist1 occur less frequently than in fdist2 |
4.3 WordNet
WordNet是一个面向语义的英语词典,类似于传统的词库,但结构更加丰富。NLTK包括英语WordNet,包含155,287个单词和117,659个同义词集。我们首先看一下同义词以及如何在WordNet中访问它们。
使用wordnet.synsets()可以查看单词的含义
>>> from nltk.corpus import wordnet as wn
>>> wn.synsets('motorcar')
[Synset('car.n.01')]
[Synset('car.n.01')]表示motorcar只有car这一个含义,汽车的第一个名词意义。实体Synset(‘car.n.01’)被称为synset,即同义词的集合。
查看词条名
>>> wn.synset('car.n.01').lemma_names()
['car', 'auto', 'automobile', 'machine', 'motorcar']
查看含义与例句
definition()和examples()
>>> wn.synset('car.n.01').definition()
'a motor vehicle with four wheels; usually propelled by an internal combustion engine'
>>> wn.synset('car.n.01').examples()
['he needs a car to get to work']

获取同义词
>>>wn.synset('car.n.01').lemma_names()
['car', 'auto', 'automobile', 'machine', 'motorcar']
