gremlin3.3.3 第三部分 - 1-图的遍历(3)

3.3.3
图的遍历

Group (分组) Step
当遍历器在遍历定义的图中传播时,有时需要进行其他(sideEffect) 计算。这种场景下,实际的路径或遍历器的当前位置都不是最终输出,而是遍历的其他表示。group()-step
(map/sideEffect)就是这样的场景之一,它根据对象的某个函数对对象进行组织。然后,如果需要,消费(reduce)该组织(或是遍历的集合)。下面提供了一个示例。
> gremlin\> g.V().group().by(label)
> ==\>[software:[v[3],v[5]],person:[v[1],v[2],v[4],v[6]]]
> gremlin\> g.V().group().by(label).by('name')
> ==\>[software:[lop,ripple],person:[marko,vadas,josh,peter]]
> gremlin\> g.V().group().by(label).by(count())
> ==\>[software:2,person:4]
-
按顶点的label值分组。
-
对于顶点的label值分组,获得它们的名称。
-
顶点的label值分组个数统计
类似于sql中的grouy-by形式,by()可用于 group() 的两个投影参数为:
-
键投影:分组对象的什么特性(生成映射键的函数)?
-
值投影:要存储在键列表中的组的什么特性?
其他用法
group(), group(String)
GroupCount (分组计数) Step
当需要知道特定对象在遍历的指定的内容出现了多少次时,使用groupCount()-step(map/sideEffect)。
> "图表中年龄的分布情况是怎样的?"
> gremlin\> g.V().hasLabel('person').values('age').groupCount()
> ==\>[32:1,35:1,27:1,29:1]
> gremlin\> g.V().hasLabel('person').groupCount().by('age')
> ==\>[32:1,35:1,27:1,29:1]
- 您还可以提供一个 pre-group投影,其中由 by()-确定如何对传入对象进行分组。
有一个人32岁,一个人35岁,一个人27岁,还有一个人29岁。
“反复遍历图表,数一下你看到每个名字的第二个字母的次数。”

> gremlin\> g.V().repeat(both().groupCount('m').by(label)).times(10).cap('m')
> ==\>[software:19598,person:39196]
上面的内容很形象地演示了使用字符串变量引用groupCount()的内部Map
其他用法
groupCount(), groupCount(String)
Has (存在) Step

可以使用has()-step
(filter)根据顶点、边和顶点的属性来过滤它们。has()有多种使用方式,包括:
-
has(key,value):如果其元素没有给定的key/value属性,则从遍历器删除。
-
has(label, key,
value):如果其元素没有给定的label和给定的key/value属性,则从遍历器删除。 -
has(key,predicate):如果其元素没有满足双谓词的键值,则从遍历器删除。有关谓词的更多信息,请阅读
A Note on
Predicates.。 -
hasLabel(labels…):如果遍历器的元素没有任何标签,则删除它。
-
hasId(id…):如果它的元素没有任何id,从遍历器删除。
-
hasKey(keys…):如果属性没有提供的所有键,则从遍历器删除。
-
hasValue(values…):如果遍历器的属性没有提供所有的值,则从遍历器删除。
-
has(key):如果其元素没有键值,则从遍历器删除。
-
hasNot(key):和上面相反,如果遍历器的元素具有键值,则从遍历器删除。
-
has(key,traversal):如果在遍历属性值时,其对象没有产生结果,则从遍历器删除。
gremlin\> g.V().hasLabel('person')
- ==\>v[1]
- ==\>v[2]
- ==\>v[4]
- ==\>v[6]
- gremlin\> g.V().hasLabel('person').out().has('name',within('vadas','josh'))
- ==\>v[2]
- ==\>v[4]
- gremlin\> g.V().hasLabel('person').out().has('name',within('vadas','josh')).
- outE().hasLabel('created')
- ==\>e[10][4-created-\>5]
- ==\>e[11][4-created-\>3]
- gremlin\> g.V().has('age',inside(20,30)).values('age') \\
- ==\>29
- ==\>27
- gremlin\> g.V().has('age',outside(20,30)).values('age')
- ==\>32
- ==\>35
- gremlin\> g.V().has('name',within('josh','marko')).valueMap() \\
- ==\>[name:[marko],age:[29]]
- ==\>[name:[josh],age:[32]]
- gremlin\> g.V().has('name',without('josh','marko')).valueMap() \\
- ==\>[name:[vadas],age:[27]]
- ==\>[name:[lop],lang:[java]]
- ==\>[name:[ripple],lang:[java]]
- ==\>[name:[peter],age:[35]]
- gremlin\> g.V().has('name',not(within('josh','marko'))).valueMap()
- ==\>[name:[vadas],age:[27]]
- ==\>[name:[lop],lang:[java]]
- ==\>[name:[ripple],lang:[java]]
- ==\>[name:[peter],age:[35]]
- gremlin\> g.V().properties().hasKey('age').value() \\
- ==\>29
- ==\>27
- ==\>32
- ==\>35
- gremlin\> g.V().hasNot('age').values('name')
- ==\>lop
- ==\>ripple
-
查找年龄在20(包含)到30(排除)之间的所有顶点。
-
查找年龄不在20(包含)到30(排除)之间的所有顶点。
-
在集合[josh,marko]中找到与所有名称完全匹配的所有顶点,显示这些顶点的所有键-值对。
-
找到所有名字不在集合中的顶点[josh,marko],显示这些顶点的所有键-值对。
-
和前面的例子一样,使用not 和 withi搭配替代 without。
-
找到所有的年龄属性并输出它们的值。
-
找到所有没有age属性的顶点,并输出它们的name。
TinkerPop不支持正则表达式谓词,尽管利用TinkerPop的图形数据库可能提供的扩展。
其他用法
has(String), has(String,Object), has(String,P), has(String,String,Object), has(String,String,P), has(String,Traversal), has(T,Object), has(T,P), has(T,Traversal), hasId(Object,Object…), hasId§, hasKey§, hasKey(String,String…), hasLabel§, hasLabel(String,String…), hasNot(String), hasValue(Object,Object…), hasValue§, P, T
Id (获取唯一标识) Step
id()-step (map)接受一个元素并从中提取其标识符。
> gremlin\> g.V().id()
> ==\>1
> ==\>2
> ==\>3
> ==\>4
> ==\>5
> ==\>6
> gremlin\> g.V(1).out().id().is(2)
> ==\>2
> gremlin\> g.V(1).outE().id()
> ==\>9
> ==\>7
> ==\>8
> gremlin\> g.V(1).properties().id()
> ==\>0
> ==\>1
其他用法
id
()
Identity (标识) Step
identity()-step (map)是一个标识函数,它将映射当前对象。
> gremlin\> g.V().identity()
> ==\>v[1]
> ==\>v[2]
> ==\>v[3]
> ==\>v[4]
> ==\>v[5]
> ==\>v[6]
其他用法
identity()
Inject (注入) Step
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BIr5Hjbn-1597728762396)(media/03a88d63bb09cdb1cedd1eaf47053450.png)]](http://img.e-com-net.com/image/info8/e4ef71141f234951b7167a166107e804.jpg)
TinkerPop3的主要特性之一是“可注入的步骤”。这使得可以任意地将对象插入遍历流中。下面提供一些inject()-step(sideEffect)示例。
> gremlin\> g.V(4).out().values('name').inject('daniel')
> ==\>daniel
> ==\>ripple
> ==\>lop
> gremlin\> g.V(4).out().values('name').inject('daniel').map
> {
it.get().length()}
> ==\>6
> ==\>6
> ==\>3
> gremlin\> g.V(4).out().values('name').inject('daniel').map
> {
it.get().length()}.path()
> ==\>[daniel,6]
> ==\>[v[4],v[5],ripple,6]
> ==\>[v[4],v[3],lop,3]
在上面的最后一个示例中,请注意以daniel开始的path长度只有2。这是因为daniel字符串是在遍历的中间处理才被插入的。最后,下面提供了一个典型的用例——当遍历的开始不是一个graph对象时。
> gremlin\> inject(1,2)
> ==\>1
> ==\>2
> gremlin\> inject(1,2).map {
it.get() + 1}
> ==\>2
> ==\>3
> gremlin\> inject(1,2).map {
it.get() + 1}.map
> {
g.V(it.get()).next()}.values('name')
> ==\>vadas
> ==\>lop
其他用法
注入(对象)
Is(等同于) Step
可以使用is()-step (filter)过滤指定的值 可以是表达式或者数值。
> gremlin\> g.V().values('age').is(32)
> ==\>32
> gremlin\> g.V().values('age').is(lte(30))
> ==\>29
> ==\>27
> gremlin\> g.V().values('age').is(inside(30, 40))
> ==\>32
> ==\>35
> gremlin\> g.V().where(\_\_.in('created').count().is(1)).values('name')
> ==\>ripple
> gremlin\> g.V().where(\_\_.in('created').count().is(gte(2))).values('name')
> ==\>lop
> gremlin\> g.V().where(\_\_.in('created').values('age').
> mean().is(inside(30d, 35d))).values('name')
> ==\>lop
> ==\>ripple
-
找到入边的数量=1的元素,并给出name。
-
找到入边的数量>=2的元素,并给出name。
-
找到入边的数量在30到35岁之间的元素, 并给出name。
其他用法
is(Object), is§, P
Key(属性键) Step
key()-step (map)可从Property 中获取key的名称。
> gremlin\> g.V(1).properties().key()
> ==\>name
> ==\>location
> ==\>location
> ==\>location
> ==\>location
> gremlin\> g.V(1).properties().properties().key()
> ==\>startTime
> ==\>endTime
> ==\>startTime
> ==\>endTime
> ==\>startTime
> ==\>endTime
> ==\>startTime
其他用法
key()
Label (标签) Step
label()-step (map)可以从一个 Element中提取其标签。
> gremlin\> g.V().label()
> ==\>person
> ==\>person
> ==\>software
> ==\>person
> ==\>software
> ==\>person
> gremlin\> g.V(1).outE().label()
> ==\>created
> ==\>knows
> ==\>knows
> gremlin\> g.V(1).properties().label()
> ==\>name
> ==\>age
其他用法
Label()
Limit (限制) Step
limit()-step与range()-step类似,只是可设置的最小值为0。
> gremlin\> g.V().limit(2)
> ==\>v[1]
> ==\>v[2]
> gremlin\> g.V().range(0, 2)
> ==\>v[1]
> ==\>v[2]
limit()步骤也可以应用于 Scope.local,在这种情况下,它对传入的收集进行操作。下面的示例使用Crew玩具数据集。
> gremlin\> g.V().valueMap().select('location').limit(local,2)
> ==\>[san diego,santa cruz]
> ==\>[centreville,dulles]
> ==\>[bremen,baltimore]
> ==\>[spremberg,kaiserslautern]
> gremlin\> g.V().valueMap().limit(local, 1)
> ==\>[name:[marko]]
> ==\>[name:[stephen]]
> ==\>[name:[matthias]]
> ==\>[name:[daniel]]
> ==\>[name:[gremlin]]
> ==\>[name:[tinkergraph]]
-
输出包含前两个local的每个顶点的List
。 -
输出包含第一个属性值的Map
其他用法
limit(long), limit(Scope,long) Scope
Local (本地) Step

graph遍历对连续的对象流进行操作。在许多情况下,对流中的单个元素进行操作是很重要的。要执行这样的对象局部遍历计算,需要存在local()-step(branch)。下面的示例使用Crew玩具数据集。
> gremlin\> g.V().as('person').
> properties('location').order().by('startTime',incr).limit(2).value().as('location').
> select('person','location').by('name').by() //
> ==\>[person:daniel,location:spremberg]
> ==\>[person:stephen,location:centreville]
> gremlin\> g.V().as('person').
> local(properties('location').order().by('startTime',incr).limit(2)).value().as('location').
> select('person','location').by('name').by() /
> ==\>[person:marko,location:san diego]
> ==\>[person:marko,location:santa cruz]
> ==\>[person:stephen,location:centreville]
> ==\>[person:stephen,location:dulles]
> ==\>[person:matthias,location:bremen]
> ==\>[person:matthias,location:baltimore]
> ==\>[person:daniel,location:spremberg]
> ==\>[person:daniel,location:kaiserslautern]
-
根据 startTime得到前两个人和他们各自的location。
-
每个人都要找到他们最具历史意义的两个location。
上面的两个遍历看起来几乎相同,只是包含了local(),它在对象局部遍历中包装了遍历的一部分。因此,order().by()和limit()引用一个特定对象,而不是整个流。
Local 在功能上与 Flat
Map非常相似,在这一点上它经常被混淆。local()按原样通过内部遍历传播遍历器,而不拆分/克隆它。因此,它是带有本地处理的“全局遍历”。它的使用很微妙,主要应用于编译优化(例如,在编写TraversalStrategy实现时)。再举一个例子:
> gremlin\> g.V().both().barrier().flatMap(groupCount().by("name"))
> ==\>[lop:1]
> ==\>[lop:1]
> ==\>[lop:1]
> ==\>[vadas:1]
> ==\>[josh:1]
> ==\>[josh:1]
> ==\>[josh:1]
> ==\>[marko:1]
> ==\>[marko:1]
> ==\>[marko:1]
> ==\>[peter:1]
> ==\>[ripple:1]
> gremlin\> g.V().both().barrier().local(groupCount().by("name"))
> ==\>[lop:3]
> ==\>[vadas:1]
> ==\>[josh:3]
> ==\>[marko:3]
> ==\>[peter:1]
> ==\>[ripple:1]
| WARNING | 匿名遍历local() “本地”处理当前对象。在OLAP中,计算的原子单位是顶点和它的局部“local() ”,重要的是匿名遍历不能离开顶点星图的范围。换句话说,它不能遍历相邻顶点的属性或边。 |
|---|
其他用法
local(Traversal)
Loops(循环) Step
loops()-step (map)提取遍历器通过当前循环的次数。
> gremlin\> g.V().emit(\_\_.has("name",
> "marko").or().loops().is(2)).repeat(\_\_.out()).values("name")
> ==\>marko
> ==\>ripple
> ==\>lop
其他用法
loops()
Match (匹配) Step
match()步骤(map)基于模式匹配的概念提供了一种更具声明性的图形查询形式。使用match(),用户提供一个“遍历片段”的集合,称为模式,其中定义了在整个match()过程中必须为真的变量。当一个遍历器处于match()中时,一个已注册的MatchAlgorithm 会分析遍历器的当前状态(即基于路径数据的历史记录)、遍历模式的运行时统计信息,并返回一个接下来遍历器应该尝试的遍历模式。提供的默认MatchAlgorithm 称为CountMatchAlgorithm,它根据模式的过滤能力(即先执行最大集缩减模式)对模式进行排序,从而动态修改模式执行计划。对于非常大的图,当开发人员不确定图的统计信息(例如图中有多少已知边和多少对边的工作)时,更利于使用match(),因为最佳计划将自动确定。而且,有些查询通过match()比通过单路径遍历更容易表示。
“谁创造了一个叫‘lop’的项目,而这个项目的创作者也是一个29岁的人?”把两个创造者还给我。”
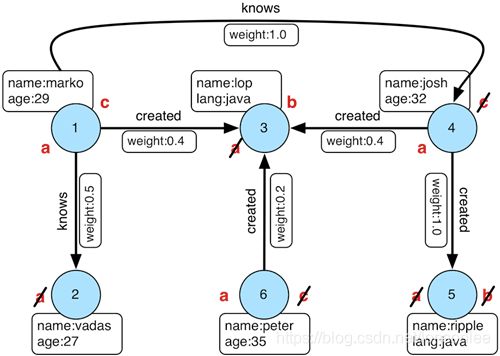
> gremlin\> g.V().match(
> \_\_.as('a').out('created').as('b'),
> \_\_.as('b').has('name', 'lop'),
> \_\_.as('b').in('created').as('c'),
> \_\_.as('c').has('age', 29)).
> select('a','c').by('name')
> ==\>[a:marko,c:marko]
> ==\>[a:josh,c:marko]
> ==\>[a:peter,c:marko]
注意,上面的代码也可以更简洁地写成下面的代码,它演示了可以任意定义标准的内部遍历。
> gremlin\> g.V().match(
> \_\_.as('a').out('created').has('name', 'lop').as('b'),
> \_\_.as('b').in('created').has('age', 29).as('c')).
> select('a','c').by('name')
> ==\>[a:marko,c:marko]
> ==\>[a:josh,c:marko]
> ==\>[a:peter,c:marko]
为了提高可读性,可以为as()-步骤提供有意义的标签,以便更好地展示domain。因此,可以用更有表现力的方式编写前一个查询,如下所示。
> gremlin\> g.V().match(
> \_\_.as('creators').out('created').has('name', 'lop').as('projects'), \\
> \_\_.as('projects').in('created').has('age', 29).as('cocreators')).
> select('creators','cocreators').by('name')
> ==\>[creators:marko,cocreators:marko]
> ==\>[creators:josh,cocreators:marko]
> ==\>[creators:peter,cocreators:marko]
-
找到顶点,匹配
‘creators’,然后找出他们为‘lop’创造了什么,这些顶点起别名为‘projects’。 -
使用这些“projects”顶点,找出他们29岁的创建者,并记住这些是“cocreators”。
-
返回’ creators’和’ cocreators’的名称。
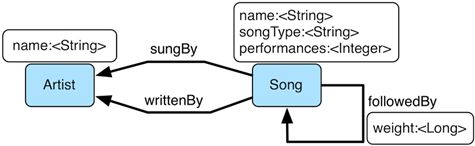
图4。Grateful Dead
MatchStep为Gremlin提供了类似于SPARQL的功能。与SPARQL类似,MatchStep将应用于图的一组模式连接在一起。例如,下面的遍历可以找到Jerry
Garcia唱过和写过的歌曲(使用分布在data/ 目录中的Grateful Dead图):
> gremlin\> graph.io(graphml()).readGraph('data/grateful-dead.xml')
> gremlin\> g = graph.traversal()
> ==\>graphtraversalsource[tinkergraph[vertices:808 edges:8049], standard]
> gremlin\> g.V().match(
> \_\_.as('a').has('name', 'Garcia'),
> \_\_.as('a').in('writtenBy').as('b'),
> \_\_.as('a').in('sungBy').as('b')).
> select('b').values('name')
> ==\>CREAM PUFF WAR
> ==\>CRYPTICAL ENVELOPMENT
将match()与SPARQL区分开来的特性有:
> gremlin\> g.V().match(
> \_\_.as('a').out('created').has('name','lop').as('b'),
> \_\_.as('b').in('created').has('age', 29).as('c'),
> \_\_.as('c').repeat(out()).times(2)). \\
> select('c').out('knows').dedup().values('name')
> ==\>vadas
> ==\>josh
-
任意复杂度的模式:match()不限于三组模式或属性路径。
-
递归支持:match()支持模式中基于分支的步骤,包括repeat()。
-
命令式/声明式混合:在match()之前和之后,可以利用经典的Gremlin遍历。
要扩展第3点,可以支持从命令式到声明式,再到命令式,直至无穷。
> gremlin\> g.V().match(
> \_\_.as('a').out('knows').as('b'),
> \_\_.as('b').out('created').has('name','lop')).
> select('b').out('created').
> match(
> \_\_.as('x').in('created').as('y'),
> \_\_.as('y').out('knows').as('z')).
> select('z').values('name')
> ==\>vadas
> ==\>josh
| IMPORTANT | match()StepStep是无状态的。遍历模式的变量绑定存储在遍历器的路径历史中。因此,所有的变量match() 遍历中的步骤是全局唯一的。这样做的一个好处是后续的where(), select(), match()等步骤可以在分析中利用相同的变量。 |
|---|
与Gremlin中的所有其他步骤一样,match()是一个函数,因此match()中的match()是Gremlin函数基础(即递归匹配)的自然结果。
> gremlin\> g.V().match(
> \_\_.as('a').out('knows').as('b'),
> \_\_.as('b').out('created').has('name','lop'),
> \_\_.as('b').match(
> \_\_.as('b').out('created').as('c'),
> \_\_.as('c').has('name','ripple')).
> select('c').as('c')).
> select('a','c').by('name')
> ==\>[a:marko,c:ripple]
如果使用步进标记的遍历执行match()步骤,并且进入match()的遍历程序注定要绑定到特定的变量,那么前面的步骤应该相应地标记。
> gremlin\> g.V().as('a').out('knows').as('b').
> match(
> \_\_.as('b').out('created').as('c'),
> \_\_.not(\_\_.as('c').in('created').as('a'))).
> select('a','b','c').by('name')
> ==\>[a:marko,b:josh,c:ripple]
match()遍历模式有三种类型。
-
as(‘a’)…as(‘b’):遍历的开始和结束都有一个声明的变量。
-
as(‘a’)…:只有遍历的开始有一个声明的变量。
-
:无参形式。
如果变量位于遍历模式的开头,那么它必须作为标签存在于遍历器的路径历史中,否则遍历器不能沿着该路径运行。如果变量位于遍历模式的末尾,那么如果该变量存在于遍历器的路径历史中,则遍历器的当前位置必须匹配(即等于)它在同一标签中的历史位置。但是,如果该变量在遍历器的路径历史中不存在,则将当前位置标记为该变量,从而成为后续遍历模式的绑定变量。如果一个遍历模式没有结束标签,那么遍历器必须“拯救”该模式(即未被过滤),以继续到下一个模式。如果一个遍历模式没有开始标签,那么遍历器可以沿着该路径在任何点进行遍历,但是只会沿着该模式进行一次,因为遍历模式执行一次,并且只对遍历器的历史执行一次。通常,没有开始和结束标签的遍历模式与and()、or()和where()一起使用。一旦遍历器“保存”了所有模式(或者至少一个for
or()),
match()步骤将分析遍历器的路径历史,并将变量绑定的Map 发送到遍历的下一个步骤。
> gremlin\> g.V().as('a').out().as('b').
> match(
> \_\_.as('a').out().count().as('c'),
> \_\_.not(\_\_.as('a').in().as('b')), \\
> or(
> \_\_.as('a').out('knows').as('b'),
> \_\_.as('b').in().count().as('c').and().as('c').is(gt(2)))). /
> dedup('a','c'). 7
> select('a','b','c').by('name').by('name').by()
> ==\>[a:marko,b:lop,c:3]
-
一般来讲 Step遍历可以在match()之前进行。
-
如果遍历器在输入match()之前的路径具有必需的标签值,则绑定这些历史值。
-
局部计算模式下,也可以使用barrier Step, (正如预期的那样)。
-
not()模式下的匹配。
-
用and()- 和 or()进行嵌套连接匹配。
-
支持中缀和前缀连接表示法。
-
可以去重指定的标签类型。
-
选取顶点abc的name,name类型不同
Match中使用Where
Match通常与select()(前面演示的)和where()(这里给出的)一起使用。where()步骤允许用户进Step限制match()提供的结果集。
> gremlin\> g.V().match(
> \_\_.as('a').out('created').as('b'),
> \_\_.as('b').in('created').as('c')).
> where('a', neq('c')).
> select('a','c').by('name')
> ==\>[a:marko,c:josh]
> ==\>[a:marko,c:peter]
> ==\>[a:josh,c:marko]
> ==\>[a:josh,c:peter]
> ==\>[a:peter,c:marko]
> ==\>[a:peter,c:josh]
where()步骤可以采用p谓词(上面的例子)或遍历(下面的例子)。通过使用MatchPredicateStrategy,
where()-子句将自动折叠到match()中,从而由match()-步骤中的查询优化器来执行。
> gremlin\> traversal = g.V().match(
> \_\_.as('a').has(label,'person'), \\
> \_\_.as('a').out('created').as('b'),
> \_\_.as('b').in('created').as('c')).
> where(\_\_.as('a').out('knows').as('c')).
> select('a','c').by('name'); null
> gremlin\> traversal.toString()
> ==\>[GraphStep(vertex,**[]**), MatchStep(AND,[[MatchStartStep(a),
> HasStep([\~label.eq(person)]), MatchEndStep], [MatchStartStep(a),
> VertexStep(OUT,[created],vertex), MatchEndStep(b)], [MatchStartStep(b),
> VertexStep(IN,[created],vertex), MatchEndStep(c)]]),
> WhereTraversalStep([WhereStartStep(a), VertexStep(OUT,[knows],vertex),
> WhereEndStep(c)]), SelectStep(last,[a, c],[value(name)])]
> gremlin\> traversal *//*
> ==\>[a:marko,c:josh]
> gremlin\> traversal.toString()
> ==\>[TinkerGraphStep(vertex,[\~label.eq(person)])\@[a],
> MatchStep(AND,[[MatchStartStep(a), VertexStep(OUT,[created],vertex),
> MatchEndStep(b)], [MatchStartStep(b), VertexStep(IN,[created],vertex),
> MatchEndStep(c)], [MatchStartStep(a), WhereTraversalStep([WhereStartStep,
> VertexStep(OUT,[knows],vertex), WhereEndStep(c)]), MatchEndStep]]),
> SelectStep(last,[a, c],[value(name)])]
-
从match()中取出以match()开始的所有has()步骤遍历模式,以使graph 系统能够利用筛选器进行索引查找。
-
where()绑定match()中声明的变量。
-
确保Gremlin控制台不迭代遍历的有用技巧。
-
以字符串的形式输出遍历结果。
-
Gremlin控制台将自动解析迭代器。
-
marko和josh都是合作开发者,marko认识josh。
-
应用策略后遍历的字符串表示(其中where() 被包含到match()中)
| IMPORTANT | where()-step是一个过滤器,在match ()使用是, where()中的变量子句不是绑定到全路径。因此, where ()步骤在match ()用于筛选,而不是绑定。 |
|---|
其他用法
match(Traversal…)
Math (数学计算) Step
math()步骤(math)在Gremlin中启用科学计算器功能。这Step不同于常见的函数组合和嵌套形式,而是提供了一个易于阅读的基于字符串的数学处理器。方程中的变量映射到Gremlin中的作用域,例如路径中的标签、副加效果( side-effects)或传入的映射键。Math支持by(),其中by()将按变量首次调用时的顺序应用。注意,保留变量_引用传入math()的当前数字遍历器对象。(PS:这一段翻译有点难懂,后续再优化)
> gremlin\> g.V().as('a').out('knows').as('b').math('a + b').by('age')
> ==\>56.0
> ==\>61.0
> gremlin\> g.V().as('a').out('created').as('b').
> math('b + a').
> by(both().count().math('\_ + 100')).
> by('age')
> ==\>132.0
> ==\>133.0
> ==\>135.0
> ==\>138.0
> gremlin\> g.withSideEffect('x',10).V().values('age').math('\_ / x')
> ==\>2.9
> ==\>2.7
> ==\>3.2
> ==\>3.5
> gremlin\>
> g.withSack(1).V(1).repeat(sack(sum).by(constant(1))).times(10).emit().sack().math('sin
> \_')
> ==\>0.9092974268256817
> ==\>0.1411200080598672
> ==\>-0.7568024953079282
> ==\>-0.9589242746631385
> ==\>-0.27941549819892586
> ==\>0.6569865987187891
> ==\>0.9893582466233818
> ==\>0.4121184852417566
> ==\>-0.5440211108893698
> ==\>-0.9999902065507035
计算器支持的运算符包括:*、+、\、^和%。并提供了以下内置方法:
-
abs:绝对值
-
acos:反余弦
-
asin:反正弦
-
atan::反正切
-
cbrt:立方根
-
ceil:最接近的上整数
-
cos:余弦
-
cosh:双曲余弦
-
exp:欧拉数的e^x次方
-
floor:向下取整
-
log:自然对数(底数e)
-
log10:对数(以10为底)
-
log2:对数(以2为底)
-
sin:正弦
-
sinh:双曲正弦
-
sqrt:平方根
-
tan:切
-
tanh:双曲正切
-
signum:符号函数
其他用法
math(String)
Max(获取最大值) Step
max()-step (map)用于从一个数字流中确定最大的数。
> gremlin\> g.V().values('age').max()
> ==\>35
> gremlin\> g.V().repeat(both()).times(3).values('age').max()
> ==\>35
| IMPORTANT | max(local)确定当前或本地对象(而不是遍历流中的对象)的最大值。此方式适用于Collection 和Number类型的对象。对于其他对象,以 Double.NaN返回最大值。 |
|---|
其他用法
max(), max(Scope), Scope
Mean(获取平均值) Step
mean()-step (map)对一个数字流求其平均值。
> gremlin\> g.V().values('age').mean()
> ==\>30.75
> gremlin\> g.V().repeat(both()).times(3).values('age').mean() \\
> ==\>30.645833333333332
> gremlin\> g.V().repeat(both()).times(3).values('age').dedup().mean()
> ==\>30.75
- 用repeat()填充遍历器。因此部分数据会有重复值,从而改变平均值。
| IMPORTANT | mean(local)确定当前或本地对象(而不是遍历流中的对象)的平均值。此方式适用于Collection 和Number类型的对象。对于其他对象,以 Double.NaN返回最大值。 |
|---|
其他用法
mean(), mean(Scope), Scope
Min(获取最小值) Step
min()-step (map)对一个数字流求最小值。
> gremlin\> g.V().values('age').min()
> ==\>27
> gremlin\> g.V().repeat(both()).times(3).values('age').min()
> ==\>27
| IMPORTANT | min(local)确定当前、本地对象(而不是遍历流中的对象)的最小值。此方式适用于Collection 和Number类型的对象。对于其他对象,以 Double.NaN返回最大值。 |
|---|
其他用法
min(), min(Scope), Scope
Not(非) Step
not()-step (filter) 看做一种过滤器,根据条件将从遍历流中删除对象。
> gremlin\> g.V().not(hasLabel('person')).valueMap(true)
> ==\>[id:3,name:[lop],label:software,lang:[java]]
> ==\>[id:5,name:[ripple],label:software,lang:[java]]
> gremlin\> g.V().hasLabel('person').
> not(out('created').count().is(gt(1))).values('name') \\
> ==\>marko
> ==\>vadas
> ==\>peter
- josh创建了两个项目,而vadas没有
其他用法
not(Traversal)
Option(条件分支) Step
branch() 或 choose()中均可使用Option
其他用法
option(Object,Traversal), option(Traversal)
Optional(可选条件) Step
optional()-step (branch/flatMap) 返回指定遍历的结果或返回标记的调用元素。
> gremlin\> g.V(2).optional(out('knows')) \\
> ==\>v[2]
> gremlin\> g.V(2).optional(\_\_.in('knows'))
> ==\>v[1]
-
vadas没有名为knows的出边,所以vadas被返回。
-
vadas确实有一个knows的入边,所以marko被返回。
当在图中与path 或 tree一起使用时,optional对于挖掘整个图很有效。
> gremlin\>
> g.V().hasLabel('person').optional(out('knows').optional(out('created'))).path()
> ==\>[v[1],v[2]]
> ==\>[v[1],v[4],v[5]]
> ==\>[v[1],v[4],v[3]]
> ==\>[v[2]]
> ==\>[v[4]]
> ==\>[v[6]]
- 按照created或knows的关系返回每个人的路径。
其他用法
Or(或) Step
or()-step作为一种过滤器,确保遍历中至少有一个产生结果。可参阅 and()了解and语义。
> gremlin\> g.V().or(
> \_\_.outE('created'),
> \_\_.inE('created').count().is(gt(1))).
> values('name')
> ==\>marko
> ==\>lop
> ==\>josh
> ==\>peter
or()可以执行任意次数的遍历。原始遍历器至少一个输出,以便传递给下Step。
也可以使用中缀表示法。但是,使用中缀表示法,只能同时执行两个遍历。
意思是or放在条件中间时,只允许两个条件做or判断,
> gremlin\> g.V().where(outE('created').or().outE('knows')).values('name')
> ==\>marko
> ==\>josh
> ==\>peter
其他用法
Order(排序) Step
当需要对遍历流的对象进行排序时,可以使用order()-step (map操作)。
> gremlin\> g.V().values('name').order()
> ==\>josh
> ==\>lop
> ==\>marko
> ==\>peter
> ==\>ripple
> ==\>vadas
> gremlin\> g.V().values('name').order().by(decr)
> ==\>vadas
> ==\>ripple
> ==\>peter
> ==\>marko
> ==\>lop
> ==\>josh
> gremlin\> g.V().hasLabel('person').order().by('age', incr).values('name')
> ==\>vadas
> ==\>marko
> ==\>josh
> ==\>peter
元素(Element)是遍历中被遍历次数最多的对象之一。元素可以有与之关联的属性(例如键/值对)。在许多情况下,根据元素的属性比较对元素遍历流进行排序。
> gremlin\> g.V().values('name')
> ==\>marko
> ==\>vadas
> ==\>lop
> ==\>josh
> ==\>ripple
> ==\>peter
> gremlin\> g.V().order().by('name',incr).values('name')
> ==\>josh
> ==\>lop
> ==\>marko
> ==\>peter
> ==\>ripple
> ==\>vadas
> gremlin\> g.V().order().by('name',decr).values('name')
> ==\>vadas
> ==\>ripple
> ==\>peter
> ==\>marko
> ==\>lop
> ==\>josh
order()-step允许用户提供任意数量的比较器,用于主排序、次排序等。在下面的示例中,主排序是基于created出边计数。次排序是基于人的年龄。
> gremlin\> g.V().hasLabel('person').order().by(outE('created').count(),
> incr). by('age', incr).values('name')
> ==\>vadas
> ==\>marko
> ==\>peter
> ==\>josh
> gremlin\> g.V().hasLabel('person').order().by(outE('created').count(),
> incr). by('age', decr).values('name')
> ==\>vadas
> ==\>peter
> ==\>marko
> ==\>josh
使用order .shuffle可以让指定的order遍历顺序随机。
> gremlin\> g.V().hasLabel('person').order().by(shuffle)
> ==\>v[2]
> ==\>v[4]
> ==\>v[1]
> ==\>v[6]
> gremlin\> g.V().hasLabel('person').order().by(shuffle)
> ==\>v[6]
> ==\>v[4]
> ==\>v[1]
> ==\>v[2]
用order(local)对当前本地对象(而不是整个遍历流)进行排序。这适用于Collection和Map类型的对象。对于任何其他对象无效。
> gremlin\> g.V().values('age').fold().order(local).by(decr)
> ==\>[35,32,29,27]
> gremlin\> g.V().values('age').order(local).by(decr) \\
> ==\>29
> ==\>27
> ==\>32
> ==\>35
> gremlin\> g.V().groupCount().by(inE().count()).order(local).by(values, decr)
> ==\>[1:3,0:2,3:1]
> gremlin\> g.V().groupCount().by(inE().count()).order(local).by(keys, incr)
> ==\>[0:2,1:3,3:1]
-
age被收集到一个列表中,然后按降序排序。
-
获取age之后没有被后面的order语句使用,
order(local)只是对这个结果的整数list排序。 -
groupCount()映射按name递减顺序排列。
-
groupCount()映射按key递增顺序排序。
| NOTE | values 和keys 的枚举是来自Column ,这个列可以是从Map, Map.Entry, 或者 Path里面获取。 |
|---|
其他用法
order(), order(Scope), Scope
。
> gremlin\> g.V().values('age').fold().order(local).by(decr)
> ==\>[35,32,29,27]
> gremlin\> g.V().values('age').order(local).by(decr) \\
> ==\>29
> ==\>27
> ==\>32
> ==\>35
> gremlin\> g.V().groupCount().by(inE().count()).order(local).by(values, decr)
> ==\>[1:3,0:2,3:1]
> gremlin\> g.V().groupCount().by(inE().count()).order(local).by(keys, incr)
> ==\>[0:2,1:3,3:1]
-
age被收集到一个列表中,然后按降序排序。
-
获取age之后没有被后面的order语句使用,
order(local)只是对这个结果的整数list排序。 -
groupCount()映射按name递减顺序排列。
-
groupCount()映射按key递增顺序排序。
| NOTE | values 和keys 的枚举是来自Column ,这个列可以是从Map, Map.Entry, 或者 Path里面获取。 |
|---|
其他用法
order(), order(Scope), Scope
原文链接:
http://tinkerpop.apache.org/docs/3.3.3/reference/