MobileNet V2 网络结构的原理与 Tensorflow2.0 实现
文章目录
- 介绍
- MobileNet V2 的创新
-
- 1、Inverted Residual Block
- 2、Linear Bottleneck
- MobileNet V2 网络结构
- 实验结果
- 代码实现
-
- 1、构建卷积模块
- 2、构建 Inverted Residual Block
- 3、MovblieNet V2 网络
- 4、查看 MovblieNet V2 网络结构
介绍
MobileNet V2 是对 MobileNet V1 的改进,同样是一个轻量级卷积神经网络。MobileNet V1 只是深度级可分离卷积的堆叠,但 MobileNet V2 借鉴了 ResNet 的思想,在网络中添加了 Residual Connection,进一步加强了网络的性能。
MobileNet V2 的创新
1、Inverted Residual Block
类似于 ResNet 中的 Residual Block,MobileNet V2 在 MobileNet V1 的深度级可分离卷积的基础上添加了 Residual Connection,形成 Inverted Residual Block。之所以叫做 Inverted Residual Block,是因为在 Residual Block 中,feature map 的通道数是先减少再增加的,而在 Inverted Residual Block 中,feature map 的通道数是先增加再减少的。如下图所示:
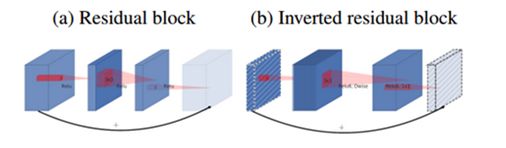
具体来说:
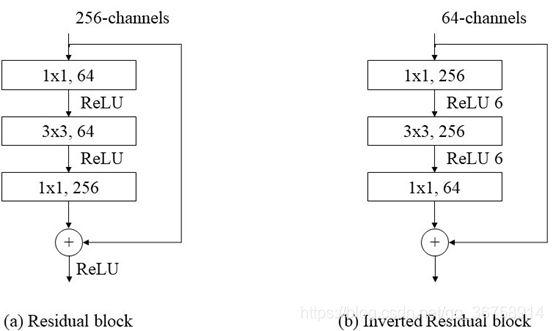
这么做的原因是:在 ResNet 中,使用的是标准的卷积层,如果不先用 1x1 conv 降低通道数,中间的 3x3 conv 计算量太大。因此,我们一般称这种 Residual Block 为 Bottleneck Block,即两头大中间小。但是在 MobileNet V2 中,中间的 3x3 conv 是深度级可分离卷积,计算量相比于标准卷积小很多,因此,为了提取更多特征,我们先用 1x1 conv 提升通道数,最后再用 1x1 conv 把通道数降下来,形成一种两头小中间大的模块,这与 Residual Block 是相反的。
另外说明一点,使用 1x1 conv 的网络结构将高维空间映射到低维空间的设计我们称之为 Bottleneck layer。
2、Linear Bottleneck
一般来说,卷积之后通常会接一个 ReLU 非线性激活(像 MobileNet V1 一样),而 ReLU6 就是普通的 ReLU 但是限制最大输出值为 6,即:
f ( x ) = m i n { m a x ( 0 , x ) , 6 } f_{(x)}=min\{max(0, x), 6\} f(x)=min{ max(0,x),6}
这是为了在移动端设备 float16/int8 的低精度的时候,也能有很好的数值分辨率,如果对 ReLU 的激活范围不加限制,输出范围为 0 到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的 float16/int8 无法很好地精确描述如此大范围的数值,带来精度损失。
因为 Xception 中已经证明,对于低维空间而言,进行线性映射会保存特征,而非线性映射会破坏特征。而 Inverted Residual Block 两端的输出通道数都比较少,属于这里说的“低维空间”,因此在 MobileNet V2 中,最后一个 1x1 conv 输出选择线性激活,即 Linear Bottleneck。
对比两个模块,在传统的 Residual Block 中使用了3个 ReLU 激活函数,而在 MobileNet V2 的 Inverted Residual Block 中只用了 2 个 ReLU6,最后一步是线性相加的。
MobileNet V2 网络结构
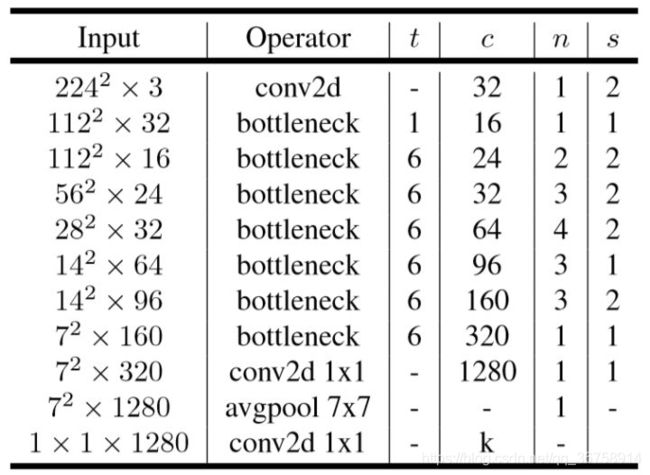
上图中的字母解释:
- t:扩展系数,即 Inverted Residual Block 中第一个 1x1 卷积核的个数是输入的通道数的多少倍,也就是中间部分的通道数是输入的通道数的多少倍;
- n:该模块重复次数;
- c:输出通道数;
- s:该模块第一次出现时的步长(后面重复该模块时步长都是 1)。
【注】上图中的 bottleneck 指的是 Inverted Residual Block,而不仅仅指 Linear Bottleneck,后者只是前者的一部分(1x1 conv)而已。
实验结果
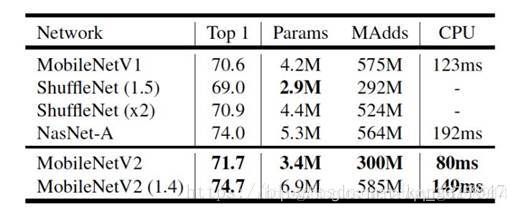
通过 Inverted Residual Block 这个新的结构,可以用较少的运算量得到较高的精度,适用于移动端的需求,在 ImageNet 上的准确率如下所示:
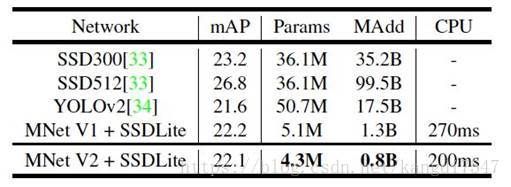
应用在目标检测任务上,基于 MobileNet V2 的 SSDLite 在 COCO 数据集上超过了 YOLO v2,并且在网络结构小 10 倍的情况下达到了 YOLO v2 20倍的速度:
代码实现
1、构建卷积模块
import tensorflow as tf
def conv_block (x, filters, kernel=(1,1), stride=(1,1)):
x = tf.keras.layers.Conv2D(filters, kernel, strides=stride, padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation(tf.nn.relu6)(x)
return x
2、构建 Inverted Residual Block
def depthwise_res_block(x, filters, kernel, stride, t, resdiual=False):
input_tensor = x
exp_channels = x.shape[-1]*t #扩展维度
x = conv_block(x, exp_channels, (1,1), (1,1))
x = tf.keras.layers.DepthwiseConv2D(kernel, padding='same', strides=stride)(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation(tf.nn.relu6)(x)
x = tf.keras.layers.Conv2D(filters, (1,1), padding='same', strides=(1,1))(x)
x = tf.keras.layers.BatchNormalization()(x)
if resdiual:
x = tf.keras.layers.add([x, input_tensor])
return x
def inverted_residual_layers(x, filters, stride, t, n):
x = depthwise_res_block(x, filters, (3,3), stride, t, False)
for i in range(1, n):
x = depthwise_res_block(x, filters, (3,3), (1,1), t, True)
return x
3、MovblieNet V2 网络
def MovblieNetV2 (classes):
img_input = tf.keras.layers.Input(shape=(224, 224, 3))
x = conv_block(img_input, 32, (3,3), (2,2))
x = tf.keras.layers.DepthwiseConv2D((3,3), padding='same', strides=(1,1))(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.Activation(tf.nn.relu6)(x)
x = inverted_residual_layers(x, 16, (1,1), 1, 1)
x = inverted_residual_layers(x, 24, (2,2), 6, 1)
x = inverted_residual_layers(x, 32, (2,2), 6, 3)
x = inverted_residual_layers(x, 64, (2,2), 6, 4)
x = inverted_residual_layers(x, 96, (1,1), 6, 3)
x = inverted_residual_layers(x, 160, (2,2), 6, 3)
x = inverted_residual_layers(x, 320, (1,1), 6, 1)
x = conv_block(x, 1280, (1,1), (2,2))
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Reshape((1,1,1280))(x)
x = tf.keras.layers.Conv2D(classes, (1,1), padding='same')(x)
x = tf.keras.layers.Reshape((classes,))(x)
x = tf.keras.layers.Activation('softmax')(x)
model = tf.keras.Model(img_input, x)
return model
4、查看 MovblieNet V2 网络结构
model = MovblieNetV2(1000)
model.summary()