linux之RHCS集群---Ricci+Luci+Fence_virtd实现web访问的高可用性
一. 服务简介
Ricci: ricci是安装在每个后端的每个节点上的,且监听在11111上,luci管理集群上的各个节点就是通过和节点上的ricci进行通信
Luci:luci是用来配置和管理集群,监听在8084上
Fence:
1.作用:在HA集群坏境中,备用服务器B通过心跳线来发送数据包来看主服务器A是否还活着,主服务器A接收了大量的客户端访问请求,服务器A的CPU负载达到100%响应不过来了,资源已经耗尽,没有办法回复服务器B数据包时,(回复数据包会延迟),服务器B认为服务器A已经挂了,于是备用服务器B把资源夺过来,自己做主服务器,过了一段时间服务器A响应过来了,服务器A觉得自己是老大,服务器B觉得自己也是老大,他们两个就挣着抢夺资源,集群资源被多个节点占有,两个服务器同时向资源写数据,破坏了资源的安全性和一致性,这种情况的发生叫做“脑裂”。服务器A负载过重,响应不过来了,有了Fence机制,Fence会自动的把服务器A给kill掉,以阻止“脑裂”的发生。
2.原理:当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资源进行了释放,保证了资源和服务始终运行在一个节点上。
3.类型:硬件Fence:电源Fence,通过关掉电源来踢掉坏的服务器 软件Fence:Fence卡(智能卡),通过线缆、软件来踢掉坏的服务器 。
二. 实验环境
主机环境 RedHat6.5 64位 实验环境
服务端1 ip 172.25.14.1 主机名:server1 ricci luci(为了提供Conga配置用户界面)
服务端2 ip 172.25.14.2 主机名:server2 ricci
管理端2 ip 172.25.14.2 fence_virtd 防火墙状态:关闭
三. 安装配置
1.安装ricci
server1&&server2
yum install -y ricci
passwd ricci #设置ricci用户的密码
/etc/init.d/ricci start #启动
chkconfig ricci on #开机自启
2.安装luci
server1 || server2
yum install luci -y
/etc/init.d/luci start #启动luci
chkconfig luci on #设置开机自启
3. 创建节点
##:操作之前需在几个节点之间配置好解析
通过网页登录到管理界面来进行配置 https://172.25.100.1:8084 ##:luci默认端口为8084
登陆到管理服务器的luci界面,登陆密码是安装luci虚拟机的root密码
选择Manage Clusters,之后点击Create创建集群
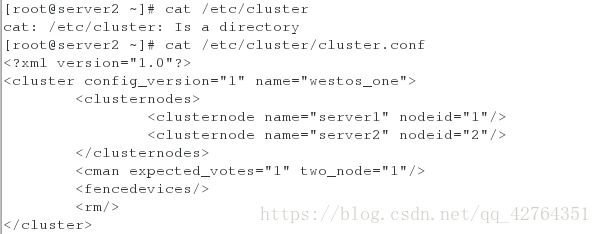
创建完成之后,在服务端的/etc/cluster/下会生成如下cluster.conf文件.
查看集群的系统中每个节点以及服务的运行状态。

##: 在上面的图中,可以看到每个节点都处于“Online”状态,表明每个节点都运行正常,如果某个节点退出了集群,对应的状态应该是“Offline”,通过“ID Status”一列可以知道集群节点的对应关系,例如,server1在此集群中对应的就是“Node 1”节点,同理,server2对应的是“Node 2”节点。了解集群节点顺序有助于对集群日志的解读。
4. 向集群中添加fence
在主机172.25.100.250安装软件fence-virtd-multicast、fence-virtd、fence-virtd-libvirt,作为fence主机使用
fence_virtd -c编写新的fence信息
选择工作模式 ”multicast”
地址”225.0.0.12”
端口”1229”
family”ipv4”
网络interface”br0”
Backend module “libvirt”;

生成128位的key,并将key发送到套件集群服务器(server1,server2)的/etc/cluster目录下
[root@foundation152 cluster]# dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1
[root@foundation152 cluster]# scp fence_xvm.key server1:/etc/cluster/
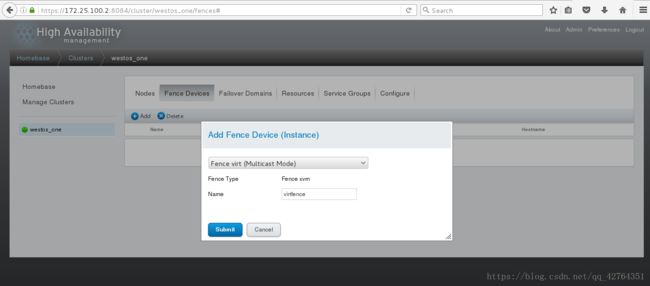
[root@foundation152 cluster]# scp fence_xvm.key server2:/etc/cluster/重新启动fence_virtd,在luci端进行配置: 登陆luci选择集群,点击Fence Devices
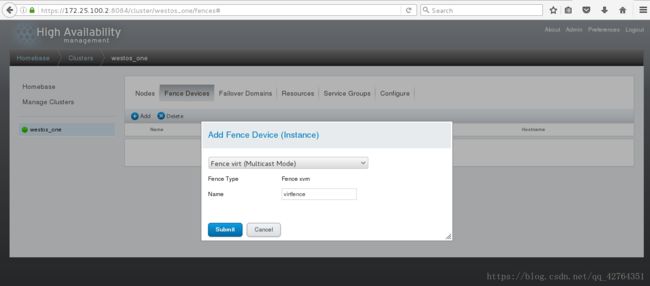
此时查看server1的集群信息文件/etc/cluster/cluster.conf,会发现virtfence,表明fence创建成功
添加fence method
点击Nodes,选择server1,点击界面下的”Add Fence Method”,输入一个自定义的server1的Fence名称,例如fence1;

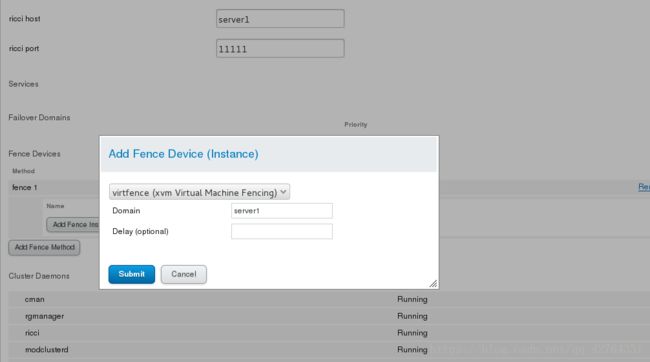
Add Fence Instance
点击Add Fence Instance,选择之前设置好的vmfence,输入Domain(虚拟服务器的UUID或主机名),在另一个server2上做同样操作
5. 添加服务
添加一个服务,这里以httpd为例
在server1和server2上均配置好httpd,编写各自的网页(index.html文件);
启动启动Apache服务检测是否正常显示网页,检测完成后server1和server2均需关闭httpd服务
##: 交给集群的资源一定是屏蔽掉的,因为要交给集群去开启
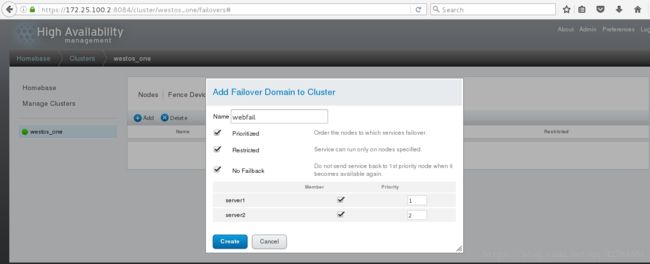
1.进入luci的集群,点击Faliover Domains,点击Add,输入Name,例如webfile,选中Prioritized、Restricted(只在指定节点跑)、No Failback(资源故障回切),选中下方的server1和server2的Member并输入优先级,这里server1输入1,server2输入2,就是以server1为主节点,数字越小优先级越高;
点击Resources,点击Add,选择模式IP Address,输入IP和NETMASK,IP不能被占用,这个IP就是VIP,点击Submit;

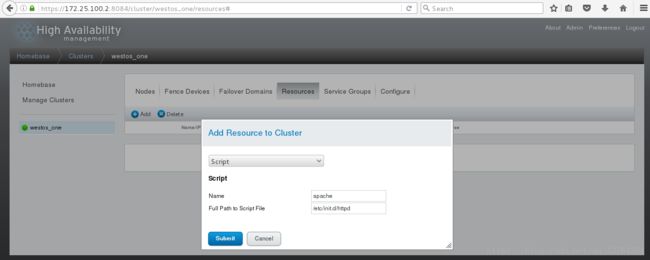
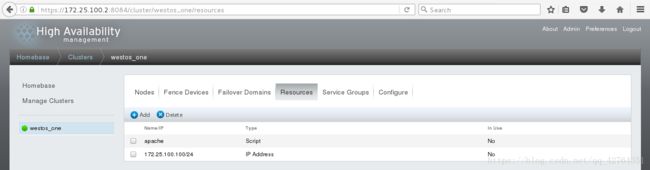
点击Resources,点击Add,选择模式Script,输入Name”apache“,并输入脚本路径”/etc/init.d/httpd“,点击Submit
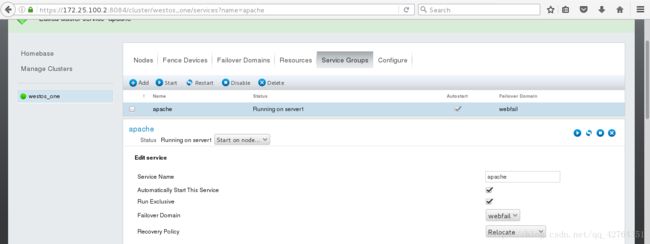
点击ServiceGroups,点击Add,输入一个自定义名称,例如”apache“,选中”Automatically Start This Service“(集群自动开启)和”Run Exclusive“,选中”FailoverDomain”下刚才创建的”webfile“,”Recovery Policy”选择”Relocate“,点击下方AddResource,选择之前创建的Resources,因为有两个,所以需要添加两次,完成后点击Submit;
三、测试
1. 在浏览器中输入域名(VIP--172.25.100.100),查看页面是否显示

clustat命令可知访问的主节点是apache

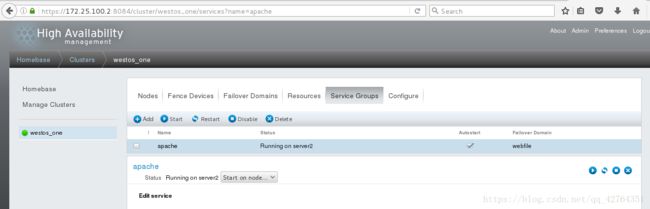
更改访问主节点为server2

2. 在server2中关闭httpd服务用clustat命令查看效果
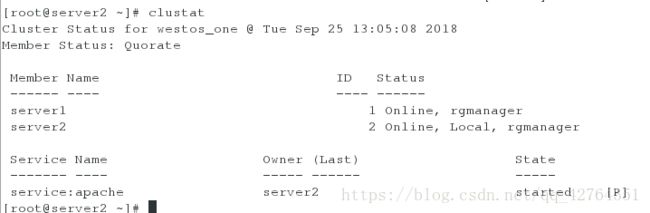
[root@server2 ~]# /etc/init.d/httpd stop
Stopping httpd: [ OK ]
3. 关于服务开闭命令 clusvcadm -s apache ##关闭httpd服务
##:一旦关闭,另一端自动开启 1 clusvcadm -e apache 打开httpd服务
4. 使用命令”echo c > /proc/sysrq-trigger“崩溃server1的内核(b,h…都有对应的操作项),并观察server1 发现server1崩溃后自动转换到server4的界面,并且server1重新启动,clustat查看server1重新started 其实server1不止是重新启动,还会自动添加到fence中,并且VIP也会自动飘过来; 在server1重新启动之后不做操作,直接将server2内核崩溃测试,发现网页自动调转到server1的界面了。 这就是故障切换。