GAN介绍 - GAN是如何工作的?
GAN介绍 - 介绍 https://blog.csdn.net/sean2100/article/details/83662975
GAN介绍 - 为什么学习生成式模型? https://blog.csdn.net/sean2100/article/details/83681043
GAN介绍 - 生成式模型是如何工作的? GAN与其他模型有什么区别?https://blog.csdn.net/sean2100/article/details/83907062
GAN介绍 - 提示与技巧 https://blog.csdn.net/sean2100/article/details/83964523
GAN介绍 - 相关研究课题 https://blog.csdn.net/sean2100/article/details/84010202
GAN介绍 - 即插即用生成网络(PPGN) https://blog.csdn.net/sean2100/article/details/84032930
GAN介绍 - 练习题 https://blog.csdn.net/sean2100/article/details/84037752
GAN介绍 - 练习题答案 https://blog.csdn.net/sean2100/article/details/84037768
GAN介绍 - 总结 https://blog.csdn.net/sean2100/article/details/84010467
May 3, 2017
我们已经了解了几种其他的一些生成模型,并且解释了GAN与这些模型的工作方式是不同的,那么GAN是如何工作的?
3.1 GAN 框架
GAN的基本思想是两个玩家共同参与的二人零和博弈。 其中一个叫生成器。 生成器试图生成与训练样本相同分布的样本。 另一个玩家是判别器。 判别器用来判别样本的真伪。 判别器使用传统的监督学习的方法,将输入分类为真和假两个类。 生成器被优化来试图欺骗判别器。 举个例子来说, 生成器类似于假币制造者,他试图制作假币, 判别器类似于警察, 他试图判别真币和假币。 为了在博弈中取得成功, 造假者必须学习制造能够以假乱真的假币, 意味着生成器必须学习生成与训练数据有同样分布的样本。 图12展示了这个过程。
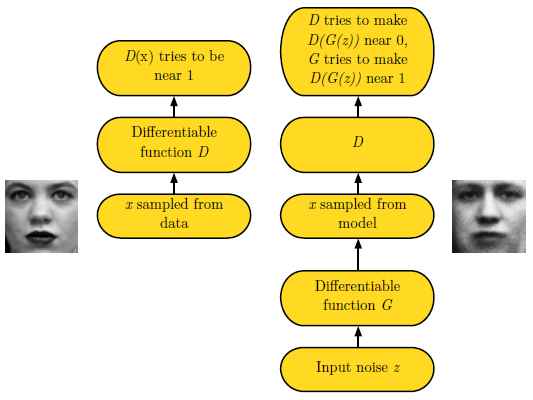
图12: GAN设计为两个对抗的玩家在同一个博弈游戏中互相对抗。 玩家被描述为由一组参数组成的可微函数。 通常情况下,这些函数都使用深度神经网络。 这个博弈可以被展开为两个场景。 第一个场景, 随机的从训练数据集中采样xx, 采样的数据作为判别器DD的输入。 判别器的目的是预测样本是真实样本的概率, 此判决假设输入的样本一半是真样本,另一半是伪样本。 在此场景中, 判别器的目标是让D(x)D(x)趋近于1。 第二个场景, 生成器的输入是隐变量zz, 此隐变量根据模型的一个先验分布进行随机采样。 然后, 生成器生成的伪样本G(z)G(z)被输入到判别器中。 在这个场景中, 两个玩家都在参与。 判别器试图让D(G(z))D(G(z))趋近于0, 生成器试图让其趋近于1。 如果两个模型具备足够的能力,那么最终博弈将达到纳什均衡, 也就是G(z)G(z)的生成样本将符合训练数据的分布, 并且对所有的xx, D(x)=1/2D(x)=1/2。
形式上, GAN是包含隐变量zz以及观测变量xx的结构化概率模型。 (参考Goodfellow et al, (2016) 第16章关于结构化概率模型的介绍) 图13给出了此图形结构。
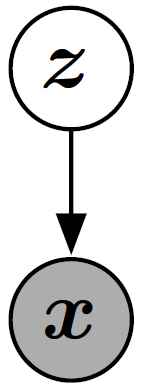
图13: GAN的图形化模型结构, 类似于VAEs, sparse coding, 等等。 它是一种直接的图像化模型也就是每一个隐变量影响每一个观测变量。 有些GAN变种去除了一些此种链接。
两个玩家被描述为两个函数, 每一个函数对输入和参数都是可微的。 判别器是函数DD, 输入是xx, 参数是θ(D)θ(D)。 生成器被定义为函数GG, 输入是zz, 参数是θ(G)θ(G)。
两个玩家的损失函数都对应着各自的参数。 判别器希望最小化J(D)(θ(D),θ(G))J(D)(θ(D),θ(G))但是只能通过对θ(D)θ(D)的控制完成。 同样的生成器希望最小化J(G)(θ(D),θ(G))J(G)(θ(D),θ(G))但是只能通过对θ(G)θ(G)的控制完成。 两个玩家的损失函数都受另一个玩家的参数影响, 但是却不能控制对方的参数, 这个场景更像是一个博弈游戏而不是一个优化问题。 优化问题的解是一个(局部)最小化问题, 也就是指一个参数空间的点,其邻近的点的损失都大于或者等于此点。 此问题在博弈中是一个纳什均衡问题。 这里我们使用的方法被称为局部微分纳什均衡(Ratliff et al., 2013)。 在本文中, 我们使用一个数组(θ(D),θ(G))(θ(D),θ(G))来表述纳什均衡, 其中对参数θ(D)θ(D)局部最小化J(D)J(D), 对参数θ(G)θ(G)局部最小化J(G)J(G)。
生成器 生成器是一个简单的可微函数GG。 zz根据一个简单的先验分布来采样, G(z)G(z)根据pmodelpmodel生成样本xx。 通常, GG使用深度神经网络模型。 GG的输入不一定对应着第一层, 输入可能在任何的网络层中。 比如说, 我们可以将zz分为两个向量, z(1)z(1), z(2)z(2), 然后z(1)z(1)可以作为第一层的输入, z(2)z(2)作为最后一层的输入。 如果z(2)z(2)是高斯分布的,那么xx就是一个给定z(1)z(1)的条件高斯分布。 另一个流行的策略是将额外的或者相乘噪音加入到隐含层中,或将噪音与网络的隐含层进行连接使用。 总之,我们可以看到生成器网络的设计有很少的限制。 如果我们希望pmodelpmodel完全的支持xx空间,那么我们需要zz的维数至少要和xx一样大, 并且GG是可微的, 以上为设计所需要的所有的条件。 特别是, 任何的非线性ICA方法可以使用的模型都可以作为GAN的生成器网络。 GAN与微分autoencoder的关系相对比较复杂; 有些GAN可以训练的一些模型,VAE不能训练, 反之也一样。 但是这两个架构也有很多的交叉。 最大的不同是,当使用标准的反向传递优化时, VAE不能使用离散变量作为输入, 但是GAN不能有离散变量的输出。
训练过程 训练过程包含同步SGD。 每一步训练有两个minibatch被采样: 一个是xx采样自训练数据,另一个是zz采样自模型的隐变量先验。 然后两个求导过程被同时执行: 一个是更新θ(D)θ(D)来最小化J(D)J(D), 另一个是更新θ(G)θ(G)来最小化J(G)J(G)。 在这两个情况下, 你可以使用基于求导的优化算法。 Adam是一个好的选择。 很多作者推荐对其中一个玩家进行更多步的优化。 但是直到2016年底, 作者的意见(经验)是,实际应用中运行的比较好的方案是: 使用同步梯度下降,并对每一个玩家分别进行单步优化。
3.2 损失函数
有很多不同的损失函数可以被用于GAN的架构中。
3.2.1 判别器的损失函数 J(D)J(D)
很多GAN相关的工作,都使用了相同的判别器损失函数, 也就是J(D)J(D)。 区别之处是使用了不同的生成器的损失函数,也就是J(G)J(G)。 判别器的损失函数被定义为:
![]()
这是一个标准的交叉熵损失函数, 此函数使用sigmoid的输出。 通过训练一个标准的两类分类问题来最小化损失函数。 不同之处是此分类器使用两个minibatch的数据来训练; 一个来自训练数据, 对应标签1, 另一个来自生成器,对应标签0。
所有GAN的版本都鼓励判别器来最小化方程式8。 在所有的版本中, 判别器都使用了相同的优化策略。 读者可以去完成7.1章的练习,答案在8.1章。 这个练习让我们了解如何得到最优的判别器优化策略, 并且讨论了此策略构成的重要性。
通过训练判别器, 我们可以得到对每一个xx的比值的估计, 也就是方程式9:
![]()
通过估计这个比值可以让我们计算多样的方差和其梯度。 此种优化是GAN区别于变分autoencoder和玻尔兹曼机的主要近似技术。 其他的深度生成模型基于下边界或者马尔可夫链来优化来近似; GAN使用监督学习优化来估计两个密度的比值来近似。 GAN优化受到监督学习过拟合和训练不足问题的影响。 理论上, 通过完美的优化和使用足够多的数据可以克服此问题。 使用其他优化方法的其他的生成式模型也有他们各自的一些问题。
使用博弈理论工具对GAN进行分析显得更加的自然, 我们称GAN为“对抗的”。 但是我们也可以认为他们是合作的, 在这种情况下,判别器估计密度的比例, 然后可以自由的与生成器分析这些信息。 从这一点上看, 判别器更像一个老师指导生成器如何提高自己并且超过对手。 当然,合作的观点没有在数学表达上有任何改变。
3.2.2 Minimax(极小极大, 极大中的极小)
到此为止,我们详述了判别器的损失函数。 完整的描述此博弈游戏也需要我们详述生成器的损失函数。
此博弈的最简单的版本是零和博弈, 也就是所有玩家的损失之和永远是零, 此博弈可以描述为:
![]()
因为J(G)J(G)是被直接绑定到J(D)J(D)上的, 所以我们可以通过一个描述判别器报酬的价值函数来归纳这个完整的博弈游戏:
![]()
零和博弈经常被称为极小极大博弈,因为这个方案包含一个外循环的最小化,和一个内循环的最大化:
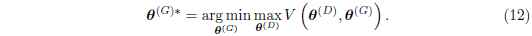
极小极大博弈最受关注是因为他在理论上容易控制。 Goodfellow et al. (2014b) 使用了GAN的一个变形来展示了这个博弈的学习类似于最小化数据和模型的分布的Jensen-Shannon散度, 以及只要两个玩家的策略可以在函数空间被直接更新, 那么博弈就可以收敛到均衡状态。 在实际应用中, 玩家被表达为深度神经网络,并且在参数空间被更新, 所以,一些凸问题,不在此列。
3.2.3 启发式(Heuristic), 非饱和博弈(non-saturating game)
极小极大博弈中生成器使用的损失函数(方程式10)在理论上分析很有效,但是在实际应用中表现并不好。
最小化目标类和分类器预测分布的交叉熵是很有效的, 因为只要分类器还有错误的输出,损失函数就不会达到饱和。 当然,损失最终将饱和, 也就是趋近于零, 但是这种情况只会发生在分类器能够进行正确分类的情况下。
在极小极大博弈中, 判别器最小化交叉熵, 但是生成器最大化同一个交叉熵。 这对生成器来说很不幸, 因为当判别器能够以很好的置信值成功拒绝生成样本时, 生成器的梯度将会消失。
为了解决此问题, 一个方式是继续对生成器使用交叉熵最小化。 我们直接使用目标来构建交叉熵损失函数, 而不是使用判别器的损失来获取生成器的损失。 所以生成器的损失函数变为:
![]()
在极小极大博弈中, 生成器最小化判别器的对数概率为真。 在此博弈中, 生成器最大化判别器的对数概率为错误。
这个版本的博弈是受到启发式方法的启发, 而不是基于理论的分析。
此博弈版本的唯一动机是保证当一个玩家面临失败时,也可以有一个稳定的梯度。
此博弈版本, 博弈不再是零和, 并且不能使用一个单一的值函数来描述。
3.2.4 最大似然博弈(Maximum likelihood game)
我们可能喜欢使用最大似然方法来优化GAN, 这样意味着最小化数据和模型分布的KL散度, 如方程式4. 另外,在第二章中,我们讨论过为了简化与其他方法的比较,GAN可以选择使用最大似然来优化。
在GAN的框架中, 有很多的方法可以优化方程式4。 Goodfellow (2014) 展示了使用:
![]()
σσ是logistic sigmoid函数, 当基于判别器最优假设时, 等价于最小化方程式4。 此等价保证了预期的优化: 在实际应用中, 因为我们使用采样数据(也就是说采样xx为了最大似然优化, 采样zz为了GAN优化)来对梯度进行估计, 所以会导致KL散度的随机梯度下降以及GAN训练过程的梯度与真实的期望梯度有一些扰动。 关于此等价的练习题,请参考7.3章, 答案在8.3章。
在GAN框架中,使用其他的近似最大似然的方法也是可能的, 比如说Nowozin et al. (2016).
3.2.5 散度的选择是否是GAN的可区分特征
作为我们调查GAN是如何工作的一部分, 我们可能好奇是什么让GAN在生成图片任务中表现的如此好。
以前, 很多人(包括作者本人)相信GAN能够提供锐化,很真实的样本,是因为他最小化Jensen-Shannon散度, 而VAE产生模糊的样本因为他们最小化数据和模型的KL散度。
KL散度不是对称的; 最小化DKL(pmodel||pdata)DKL(pmodel||pdata)与最小化DKL(pdata||pmodel)DKL(pdata||pmodel)是不同的。 最大似然估计执行的是前者, 最小化Jensen-Shannon散度更像是优化后者。 如图14所示, 后者可能会生成更好的样本, 因为使用此方差训练的模型更倾向于生成符合训练数据分布的样本, 即便是那意味着忽略了一些mode(众数), 而不是包括所有的mode,使生成的样本不符合任何训练集的mode。
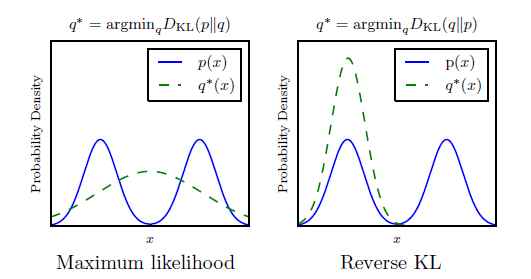
图14: KL散度的两个表达不是等价的。 最明显的不同是当模型拟合数据分布的能力很差时。 这里展示了一个一维数据xx分布的例子。 在这个例子中, 数据分布是两个混合的高斯分布的组合, 模型使用一个单一的高斯模型。 因为一个单一的高斯分布不能准确的表达真实的数据分布, 散度的选择将决定模型的选择。 左边的图使用了最大似然测度。 此模型选择对这两个mode进行平均处理, 因此它侧重于对两者整体的概率最大化。 右边的图, 使用相反顺序参数的KL散度。 我们可以认为DKL(pdata||pmodel)DKL(pdata||pmodel)倾向于对所有数据分布的整体都提高概率, 而DKL(pmodel||pdata)DKL(pmodel||pdata)侧重于降低数据不存在区域的概率。 通过这种观察, 使我们期待DKL(pmodel||pdata)DKL(pmodel||pdata)能够产生更好看的样本,因为模型将不会选择产生分布在数据的两种mode之间的非正常样本。
一些新的证据表明使用Jensen-Shannon散度不能解释为什么GAN会产生锐化的样本:
-
现在使用最大似然也能来训练GAN, 如3.2.4章描述的。 这些模型仍然可以生成锐化样本, 并且选择比较少的mode。 如图15。

图15: f-GAN模型能够最小化很多不同的散度。 因为模型被训练最小化DKL(pdata||pmodel)DKL(pdata||pmodel)并且仍然可以产生锐化的样本, 并且倾向于选择少量的mode, 我们可以总结为使用Jensen-Shannon散度不是GAN的特别重要的一个特征, 并且它也不能解释为什么GAN的样本会倾向于锐化。
-
GAN经常可以通过使用很少的mode就可以生成数据; 少于由于模型能力而限制的数量。 反向KL倾向于使用模型可以做到的尽可能多的mode来生成数据。 这说明mode collapse是由于一个其它的因素而不是由于散度选择造成的。
总之, GAN之所以选择少量的mode来生成数据, 是因为训练过程的一些缺点, 而不是因为要最小化的散度引起的。 我们将在第5.1.1章中进一步介绍。 GAN产生锐化图像的原因还没有完全的明确。 可能是因为使用GAN训练的这类模型与使用VAE训练的模型不同 (比如, 当xx有一个更加复杂的分布,而不是一个简单的高斯分布时, 使用GAN更容易构建模型)。 也可能是因为GAN的近似处理与其他方法的近似有不同的影响。
3.2.6 损失函数比较
我们可以认为生成器网络是通过一些特殊的增强学习来训练的。 与其说它是在让一个特定的输出xx与一个zz相关联, 还不如说是生成器采取一些行动,并且接收这些行动来带来的反馈(奖励)。 特别是, J(G)J(G)根本不直接参考训练数据; 所有的关于训练数据的的信息都是仅仅通过判别器反馈的信息来进行学习的 (附带着, 这将使得GAN更不容易过拟合, 因为生成器不会直接的复制训练数据)。 其学习过程与传统的增强学习不一样, 这是因为:
- 生成器不仅可以观察回报函数的输出,并且可以获得它的梯度。
- 回报函数是非稳定的; 回报是通过判别器对生成器策略改变的反应来获取的。
在所有情况下, 我们可以认为采样过程开始于选择一个特定的zz, 然后进行独立的处理并接受对应的的回报, 也就是说与其他的zz的相关行为无关。 生成器得到的反馈是一个标量函数,D(G(z))D(G(z))。 我们通常认为这与损失有关(负的回报)。 生成器的损失(D(G(z))D(G(z)))总是单调下降的, 但是不同的博弈被设计为使损失沿着不同的曲线快速下降。
图16展示了三个不同变种的GAN的损失曲线,也就是D(G(z))D(G(z))的曲线。 我们可以看到, 最大似然方法的损失函数有很高的方差, 因为大多数的损失的梯度来自很少样本(这些zz对应着的样本更像是真而不像伪样本)。 启发式非饱和的损失函数有很低的样本方差, 这可以解释为什么在实际应用中很成功。 这告诉我们减少方差的技术是提高GAN表现的很重要的研究领域, 特别是基于最大似然的GAN。
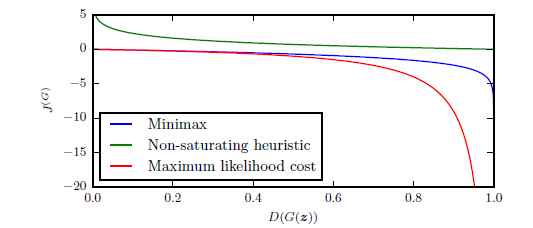
图16: 生成器接受的关于样本G(z)G(z)的损失只取决于判别器对此样本的反馈。 判别器将其识别为真样本的概率越高,那么生成器接受到的损失就越小。 我们可以看到当样本更像假样本时, minimax和最大似然都会有一个很小的梯度, 我们可以看到左边是很平坦的曲线。 启发式非饱和方法避免了此问题。 最大似然还受到绝大多数梯度值只是来自于很少的样本,如右边的曲线, 这意味着很少的样本影响了minibatch的梯度计算。 这告诉我们减少方差的技术是提高GAN表现的很重的研究领域, 特别是使用最大似然的GAN。
3.3 DCGAN结构
当前多数的GAN都基于DCGAN的结构 (Radford et al., 2015)。 DCGAN是“深度,卷积GAN”, 尽管在DCGAN以前,GAN也是使用深度和卷积网络的, DCGAN被用来指这个特定的结构。 DCGAN结构的一些主要的观点有:
- 在判别器和生成器的多数层中都使用Batch normalization(Ioffe and Szegedy, 2015), 判别器的两个minibatch被分别的标准化。 生成器的最后层和第一层没有使用batch normalization, 因此此模型可以学习到正确的数据分布的平均,缩放。 看图17.
- 整体网络结构借鉴了全卷积网络(Springenberg et al., 2015)。 这个结构即包含pooling 也包含unpooling层。 当生成器需要提高表达的空间维度时, 它使用stride大于1的转置卷积网络.
- 使用Ada优化器,而不是SGD加冲量。
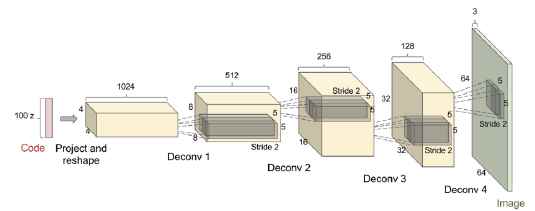
图17: DCGAN使用的生成器网络。 图来自Radford et al. (2015).
在DCGAN以前, LAPGAN(Denton et al., 2015)是唯一的可以处理(缩放)高分辨率图像的GAN版本。 LAPGAN需要一个多阶段的生成过程, 多个GAN生成多个不同层次的Laplacian金字塔来表达图像的细节。 DCGAN是第一个使用a single shot的方式来生成高分辨率图像的GAN模型。 如图18所示, 当限制图像的类别时DCGAN可以生成很高质量的图像, 比如说卧室图像。 DCGAN也清晰的展示了, GAN可以学习以有意义的方式来使用隐代码, 如图19所示, 对几个潜在空间的简单的算术操作(加,减等)可以有很明确的对应着其输入的语义上的解释。

图18: DCGAN生成的一些卧室图像, 使用LSUN数据集训练。

图19: DCGAN展示了GAN可以学习分布式表征,也就是可以区别性别信息和戴眼镜的信息。 假设有一个戴眼镜的男人的向量, 减去用来表达不带眼镜男人的向量, 最后加上表达不戴眼镜女人的向量, 就可以得到一个戴眼镜女人的向量。 生成模型正确的解码了所有的这些表达的向量, 并且这些被解码的向量可以被认为属于正确的类。 此图片来自Radford et al. (2015).
3.4 GAN与NCE和最大似然的关系
当我们试图去理解GAN是如何工作时, 我们可能想知道他与noise-contrastive estimation(NCE)的联系 (Gutmann and Hyvarinen, 2010)。 Minimax GAN使用来自NCE的损失函数作为他们的价值函数, 因此这两个方法好像很相近。 但实际上,他们学习非常不同的事情, 因为这两个方法针对的是博弈中不同的玩家。 简单的说, NCE的目标是学习判别器的密度模型, 但是GAN的目标是学习采样器来定义生成器。 这两个任务在定性分析来看是很相近的, 其实,两个任务的梯度实际上很不相同。 惊奇的是,最大似然估计(MLE)与NCE很相似, 并且在minimax博弈中有着一样的价值函数, 但是对其中的一个玩家使用了一系列启发式的更新策略而不是梯度下降。 图20总结了他们的关系。
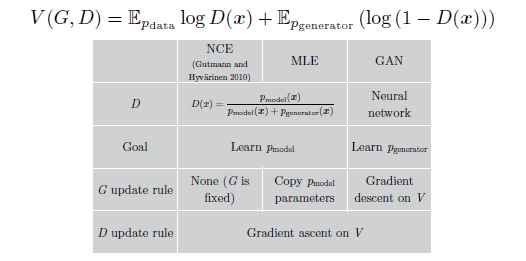
图20: Goodfellow(2014)展示了NCE,MLE,GAN的关系: 所有三种方法可以被解释为使用一样的价值函数来训练minimax博弈。 最大的不同是pmodelpmodel的分布。 对GAN来说, 生成器是pmodelpmodel, 但是NCE, MLE是指判别器。 除了这些, 还有更新策略的不同。 GAN学习两个玩家通过梯度下降。 MLE学习判别器也是使用梯度下降, 但是它为生成器使用了一个启发式的更新规则。 特别是, 在每一次判别器更新步骤以后, MLE将学习到的判别器的密度模型复制并将其转换为一个采样器,从而作为生成器来使用。 NCE从来不更新生成器, 他的生成器直接使用一个固定的噪音。
[最终修改于: 2017年6月9日]
来源:https://sinpycn.github.io/2017/05/03/GAN-Tutorial-How-do-GANs-work.html