优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam等
原博文:
1. SGD
Batch Gradient Descent
在每一轮的训练过程中,Batch Gradient Descent算法用整个训练集的数据计算cost fuction的梯度,并用该梯度对模型参数进行更新:
Θ=Θ−α⋅▽ΘJ(Θ)
Θ=Θ−α⋅▽ΘJ(Θ)
优点:
- cost fuction若为凸函数,能够保证收敛到全局最优值;若为非凸函数,能够收敛到局部最优值
缺点:
- 由于每轮迭代都需要在整个数据集上计算一次,所以批量梯度下降可能非常慢
- 训练数较多时,需要较大内存
- 批量梯度下降不允许在线更新模型,例如新增实例。
Stochastic Gradient Descent
和批梯度下降算法相反,Stochastic gradient descent 算法每读入一个数据,便立刻计算cost fuction的梯度来更新参数:
Θ=Θ−α⋅▽ΘJ(Θ;x(i),y(i))
Θ=Θ−α⋅▽ΘJ(Θ;x(i),y(i))
优点:
- 算法收敛速度快(在Batch Gradient Descent算法中, 每轮会计算很多相似样本的梯度, 这部分是冗余的)
- 可以在线更新
- 有几率跳出一个比较差的局部最优而收敛到一个更好的局部最优甚至是全局最优
缺点:
- 容易收敛到局部最优,并且容易被困在鞍点
Mini-batch Gradient Descent
mini-batch Gradient Descent的方法是在上述两个方法中取折衷, 每次从所有训练数据中取一个子集(mini-batch) 用于计算梯度:
Θ=Θ−α⋅▽ΘJ(Θ;x(i:i+n),y(i:i+n))
Θ=Θ−α⋅▽ΘJ(Θ;x(i:i+n),y(i:i+n))
Mini-batch Gradient Descent在每轮迭代中仅仅计算一个mini-batch的梯度,不仅计算效率高,而且收敛较为稳定。该方法是目前深度学训练中的主流方法
上述三个方法面临的主要挑战如下:
- 选择适当的学习率α
- α 较为困难。太小的学习率会导致收敛缓慢,而学习速度太块会造成较大波动,妨碍收敛。
- 目前可采用的方法是在训练过程中调整学习率大小,例如模拟退火算法:预先定义一个迭代次数m,每执行完m次训练便减小学习率,或者当cost function的值低于一个阈值时减小学习率。然而迭代次数和阈值必须事先定义,因此无法适应数据集的特点。
- 上述方法中, 每个参数的 learning rate 都是相同的,这种做法是不合理的:如果训练数据是稀疏的,并且不同特征的出现频率差异较大,那么比较合理的做法是对于出现频率低的特征设置较大的学习速率,对于出现频率较大的特征数据设置较小的学习速率。
- 近期的的研究表明,深层神经网络之所以比较难训练,并不是因为容易进入local minimum。相反,由于网络结构非常复杂,在绝大多数情况下即使是 local minimum 也可以得到非常好的结果。而之所以难训练是因为学习过程容易陷入到马鞍面中,即在坡面上,一部分点是上升的,一部分点是下降的。而这种情况比较容易出现在平坦区域,在这种区域中,所有方向的梯度值都几乎是 0。
2. Momentum
SGD方法的一个缺点是其更新方向完全依赖于当前batch计算出的梯度,因而十分不稳定。Momentum算法借用了物理中的动量概念,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力:
vt=γ⋅vt−1+α⋅▽ΘJ(Θ)
vt=γ⋅vt−1+α⋅▽ΘJ(Θ)
Θ=Θ−vt
Θ=Θ−vt
Momentum算法会观察历史梯度vt−1
vt−1,若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度,若当前梯度与历史梯方向不一致,则梯度会衰减。**一种形象的解释是:**我们把一个球推下山,球在下坡时积聚动量,在途中变得越来越快,γ可视为空气阻力,若球的方向发生变化,则动量会衰减。
3. Nesterov Momentum
在小球向下滚动的过程中,我们希望小球能够提前知道在哪些地方坡面会上升,这样在遇到上升坡面之前,小球就开始减速。这方法就是Nesterov Momentum,其在凸优化中有较强的理论保证收敛。并且,在实践中Nesterov Momentum也比单纯的 Momentum 的效果好:
vt=γ⋅vt−1+α⋅▽ΘJ(Θ−γvt−1)
vt=γ⋅vt−1+α⋅▽ΘJ(Θ−γvt−1)
Θ=Θ−vt
Θ=Θ−vt
其核心思想是:注意到 momentum 方法,如果只看 γ * v 项,那么当前的 θ经过 momentum 的作用会变成 θ-γ * v。因此可以把 θ-γ * v这个位置看做是当前优化的一个”展望”位置。所以,可以在 θ-γ * v求导, 而不是原始的θ。
4. Adagrad
上述方法中,对于每一个参数θi
θi 的训练都使用了相同的学习率α。Adagrad算法能够在训练中自动的对learning rate进行调整,对于出现频率较低参数采用较大的α更新;相反,对于出现频率较高的参数采用较小的α更新。因此,Adagrad非常适合处理稀疏数据。
我们设gt,i
gt,i为第t轮第i个参数的梯度,即gt,i=▽ΘJ(Θi)
gt,i=▽ΘJ(Θi)。因此,SGD中参数更新的过程可写为:
Θt+1,i=Θt,i−α⋅gt,i
Θt+1,i=Θt,i−α⋅gt,i
Adagrad在每轮训练中对每个参数θi
θi的学习率进行更新,参数更新公式如下:
Θt+1,i=Θt,i−αGt,ii+ϵ√⋅gt,i
Θt+1,i=Θt,i−Gt,ii+ϵα⋅gt,i
其中,Gt∈Rd×d
Gt∈Rd×d为对角矩阵,每个对角线位置i,ii,i为对应参数θi
θi从第1轮到第t轮梯度的平方和。ϵ是平滑项,用于避免分母为0,一般取值1e−8。Adagrad的缺点是在训练的中后期,分母上梯度平方的累加将会越来越大,从而梯度趋近于0,使得训练提前结束。
5. RMSprop
RMSprop是Geoff Hinton提出的一种自适应学习率方法。Adagrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应的平均值,因此可缓解Adagrad算法学习率下降较快的问题。
E[g2]t=0.9E[g2]t−1+0.1g2t
E[g2]t=0.9E[g2]t−1+0.1gt2
Θt+1=Θt−αE[g2]t+ϵ√⋅gt
Θt+1=Θt−E[g2]t+ϵα⋅gt
6. Adam
Adam(Adaptive Moment Estimation)是另一种自适应学习率的方法。它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。公式如下:
mt=β1mt−1+(1−β1)gt
mt=β1mt−1+(1−β1)gt
vt=β2vt−1+(1−β2)g2tvt=β2vt−1+(1−β2)gt2
mˆt=mt1−βt1m^t=1−β1tmt
vˆt=vt1−βt2v^t=1−β2tvt
Θt+1=Θt−αvˆt√+ϵmˆt
Θt+1=Θt−v^t+ϵαm^t
其中,mt
mt,vtvt分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望E[gt]E[gt],E[g2t]E[gt2]的近似;mtˆmt^,vtˆvt^是对mtmt,vtvt的校正,这样可以近似为对期望的无偏估计。 Adam算法的提出者建议β1β1 的默认值为0.9,β2β2的默认值为.999,$\epsilon $默认为10−8
10−8。 另外,在数据比较稀疏的时候,adaptive的方法能得到更好的效果,例如Adagrad,RMSprop, Adam 等。Adam 方法也会比 RMSprop方法收敛的结果要好一些, 所以在实际应用中 ,Adam为最常用的方法,可以比较快地得到一个预估结果。
最后两张动图从直观上展现了算法的优化过程。第一张图为不同算法在损失平面等高线上随时间的变化情况,第二张图为不同算法在鞍点处的行为比较。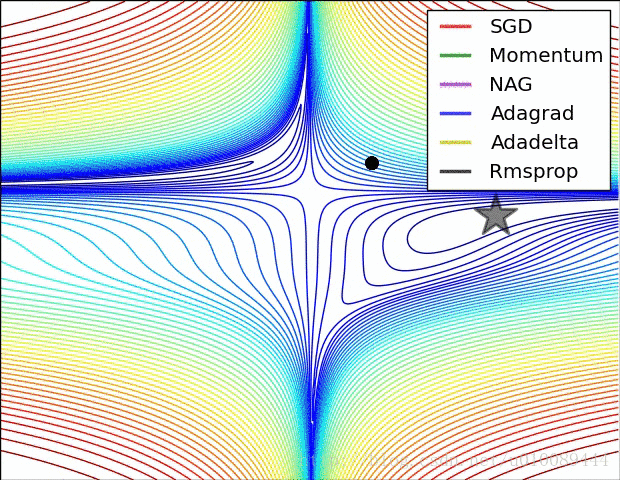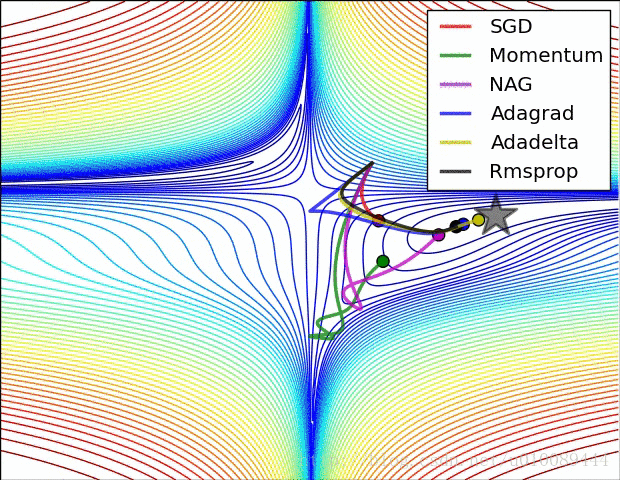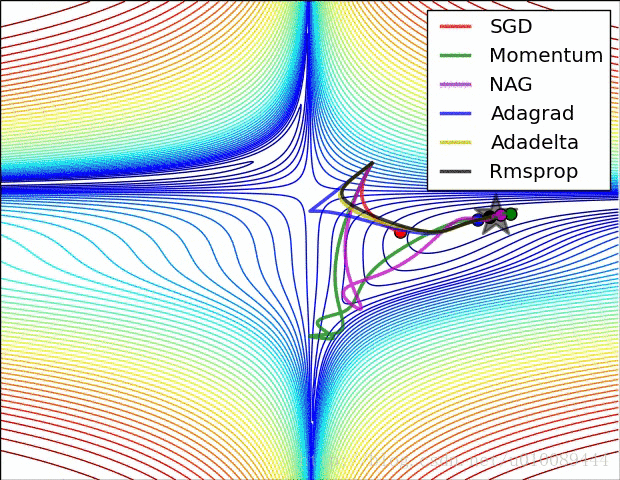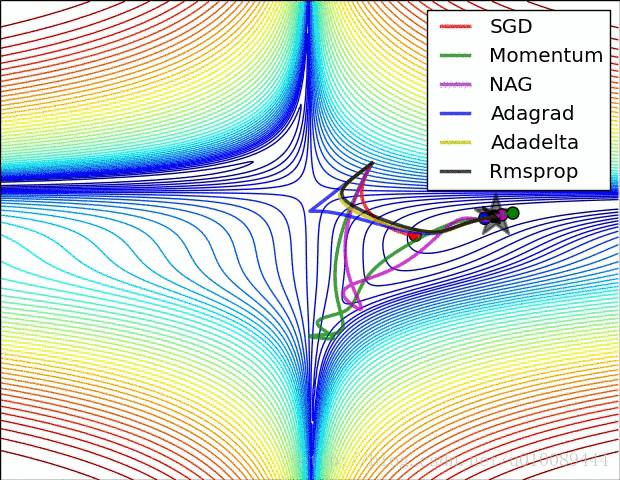

7. 参考资料
- An overview of gradient descent optimization algorithms