GAN及其变体C_GAN,infoGAN,AC_GAN,DC_GAN(一)
当时害怕篇幅过大,拆分两部分编写,下一篇文章见:GAN及其变体DCGAN, CGAN,infoGAN,BiGAN,ACGAN,WGAN,DualGAN(二)
在介绍GAN之前,我们先了解一些什么是生成模型(Generative Model)和判别模型(Discriminative Model)。
- 生成模型:学习联合概率分布P(X,Y), 即特征X和标签Y共同出现的概率,然后求条件概率分布P(Y|X)=P(X,Y)/P(X),即为生成模型。简言之,先通过学习先验分布P(x, y)来推导后验分布P(Y|X)
- 判别模型:学习条件概率分布P(Y|X),即在特征X出现的条件下标记Y出现的概率,简言之,直接学习后验分布P(Y|X)
GAN生成对抗网络
论文:Generative Adversarial Nets(2014)
GAN包含两个部分,即生成器generative和判别器discriminative。以生成图片为例,生成器主要用于学习真实图像分布从而让自身生成的图像更加真实,使得判别器分辨不出生成的数据是否是真实数据。判别器则需要对接受到的图片进行真假判别。整个过程可以看作是生成器和判别器的博弈,随着时间的推移,最终两个网络达到一个动态均衡:生成器生成的图像近似于真实图像分布,而判别器对给定图像的判别概率约为0.5,相当于盲猜。
假设真实数据data分布为 ,生成器G学习到的数据分布为
,生成器G学习到的数据分布为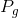 ,z为随机噪声,
,z为随机噪声,![]() 为噪声分布,
为噪声分布,![]() 为生成映射函数,将这个随机噪声转化为数据x,
为生成映射函数,将这个随机噪声转化为数据x,![]() 为判别映射函数,输出是判别x来自真实数据data而不是生成数据的概率。训练判别器D使得判别概率最大化,同时,训练生成器G最小化
为判别映射函数,输出是判别x来自真实数据data而不是生成数据的概率。训练判别器D使得判别概率最大化,同时,训练生成器G最小化![]() ,这个优化过程可以被归结于一个‘二元极小极大博弈’(two-player minimax game),目标函数被定义如下:
,这个优化过程可以被归结于一个‘二元极小极大博弈’(two-player minimax game),目标函数被定义如下:
从判别器D的角度,D希望它自己能够尽可能地判别出真实数据和生成数据,即使得D(x)尽可能的达,D(G(z))尽可能的小,即V(D,G)尽可能的大。从生成器G的角度来说,G希望自己生成的数据尽可能地接近于真实数据,也就是希望D(G(z))尽可能地大,D(x)尽可能的小,即V(D,G)尽可能的小。两个模型相互对抗,最后达到全局最优。
用图示解释,如图1所示,假设在训练伊始,真实数据分布为图中的黑色点线,生成样本分布为途中绿色实线,判别模型分布为紫色虚线。图一:开始时,判别模型不能很好地区分真实样本和生成样本;图二:当固定生成模型,训练判别模型时,可以看到这时候判别模型有所进步,能够较好的区分真实样本和生成样本;图三:固定判别模型,训练生成模型,可以看出这时候生成模型生成的样本的分布与真实样本的分布更加接近;这样不断迭代,图四:到最后达到一个平衡,生成样本分布和真实样本分布重合,判别模型的识别概率为0.5。
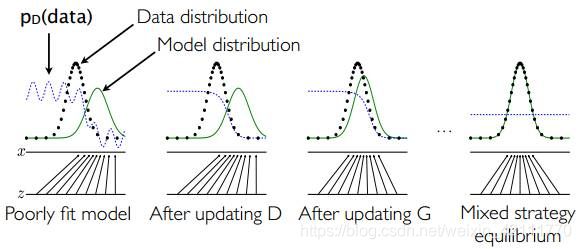 图1:GAN
图1:GAN
C_GAN (Conditional Adversarial Net)
论文:Conditional Generative Adversarial Nets(2014)
条件生成式对抗网络C_GAN是对原始GAN的一个扩展,生成器和判别器都增加额外信息y为条件,y可以是任何类型的附加信息,例如类别信息或者来自其他模态的数据。 图2中展示了一个简单的条件生成式对抗网络C_GAN的结构信息。在生成模型中,输入噪声P(z)和条件信息y联合组成了联合隐层表征。对抗训练在隐层表征的组成方式方面相当地灵活。类似的,C_GAN则被看做是带有条件概率的二人极大极小值博弈,目标函数被定义如下:
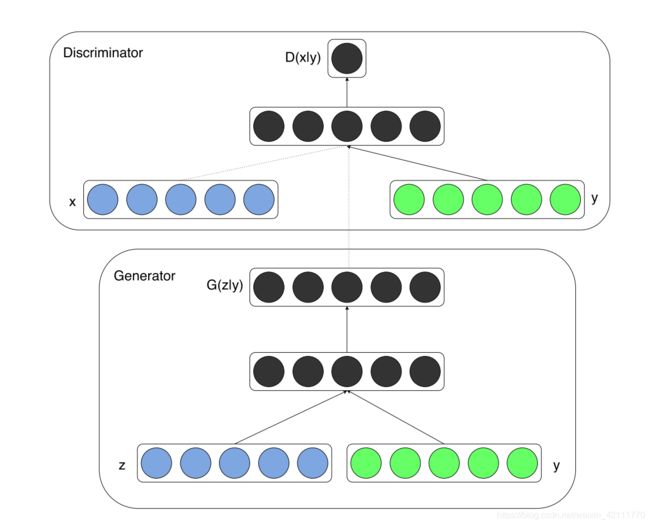 图2:CGAN结构
图2:CGAN结构
InfoGAN(Information Maximizing Generative Adversarial Network)
论文:infoGAN:Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets(2016)
首先我们先介绍一些信息论的一些知识,X和Y之间的互信息(mutual information)I(X;Y)表示变量间相互依赖性的度量。依图3所见,互信息了一看作两个熵的差值,![]() 。
。
如果X和Y是独立的,那么I(X;Y)=0。X与Y之间关联性越大,I(X;Y)就越大
 图3:互信息
图3:互信息
信息最大化生成对抗网络infoGAN的提出是为了无监督学习得到可分解的特征表示。由于原始GAN的生成器的输入仅仅是一个连续的噪声向量z,没有加任何限制,所以是在以一种高度混合的方式使用z,导致生成器无法将z的维度和数据的语义特征联系起来。然而,many domains natually decompose into a set of semantically meaningful factors of variation.
基于上面的分析,在生成器的输入中加入了隐含编码c,现在输入变量包含两部分,不能压缩的噪声z和隐含编码c,所以生成器记作G(z, c)。在原先的GAN中,生成器将会忽略附加的隐含编码c,而仅仅去学习变量分布,![]() 。因此,作者提出infoGAN,其中info表示生成分布G(z, c)和隐含编码c之间的互信息,而且为了使得x和c之间关联密切,应当最大化
。因此,作者提出infoGAN,其中info表示生成分布G(z, c)和隐含编码c之间的互信息,而且为了使得x和c之间关联密切,应当最大化![]() 。
。
因此在原始GAN目标函数的基础上,增加了正则项约束,如下:
![]()
实际上,因为需要后验![]() ,互信息
,互信息![]() 是很难直接最大化的,我们可以通过定义一个辅助的分布
是很难直接最大化的,我们可以通过定义一个辅助的分布![]() 来逼近
来逼近![]() ,从而得到
,从而得到![]() 的变分下界。经过一系列的公式推导和证明,最后目标函数可以等价于:
的变分下界。经过一系列的公式推导和证明,最后目标函数可以等价于:
![]()
其中![]()
具体实现中,我们使用神经网络来参数化辅助分布Q。在具体实现中,Q和D共用所有的卷积层,并且在最后的全连接层输出条件分布Q(c|x)的参数,因此infoGAN相比于原GAN来说,仅仅增加了微不足道的计算消耗。
ACGAN(Auxiliary Classifier Generative Adversarial Networks)
论文:Conditional Image Synthesis with Auxiliary Classifier GANs (2017)
如上面介绍的CGAN,使用side information扩充原GAN,为了能够生成class conditional samples, 给生成器和判别器提供类别标签(class labels);如上面介绍的infoGAN,调整判别器,使其包含一个辅助解码网络(auxiliary decoder network),网络的输出为生成样本隐含量的一个子集(semi-Supervised GAN中辅助网络输出的是训练数据的类别标签)。结合这两种策略利用side information,因此ACGAN应用而生,ACGAN模型属于class contional, 但是是使用一个辅助的解码器来重建类别标签。盗一个图使得上述语言描述图示化。
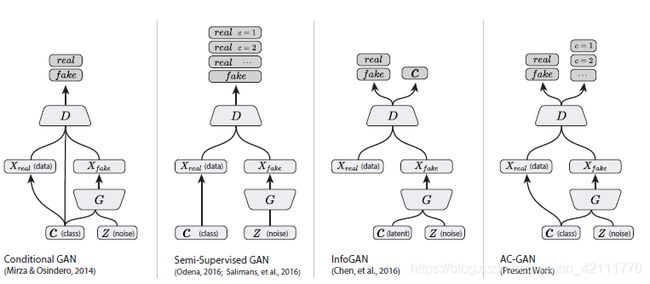
ACGAN中,生成器不仅仅包含噪声z,还包含对应的类别标签![]() ,生成器G使用两者来生成样本
,生成器G使用两者来生成样本![]() ,判别器D分别对图像的真假和类别标签给出判别概率,所以目标方程包含两部分,如下所示:
,判别器D分别对图像的真假和类别标签给出判别概率,所以目标方程包含两部分,如下所示:
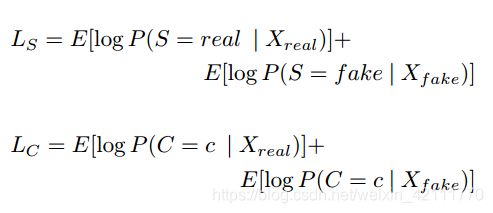
判别器D训练最大化![]() ,而生成器G训练最大化
,而生成器G训练最大化![]() ,ACGAN学习关于z独立于类标签的表达。
,ACGAN学习关于z独立于类标签的表达。
DC_GAN(Deep Convolutional Generative Adversarial Networks)
论文:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (2016)
CNN在监督学习(supervised learning)领域取得了不俗的成就,相对地,CNN在无监督学习(unsupervised learning)领域却没有很大的进展,为了填补CNN在监督学习和无监督学习之间的gap,此篇论文提出了将CNN和GAN结合的DCGAN(深度卷积生成对抗网络),并且DCGAN在无监督学习中取得不错的结果。
GAN的一大问题是训练不稳定,有时候会得到没有意义的输出,通过对卷积GAN结构添加一些限制,可以使得卷积GAN可以保持稳定,如下所述:
- 生成器中使用fractional-strided convolutions(deconvolutions)替代池化层,判别器中使用strided convolutions替代池化层
- 在生成模型和判别模型中使用batchnorm(直接将BN应用到所有层会导致样本震荡和模型不稳定,在生成器中将BN应用带输出 层,在判别器中将BN应用于输出层可避免这种现象)
- 对于更深的架构,移除全连接隐含层
- 在生成器中,除了输出层使用tanh激活函数,其他层都使用ReLU激活函数
- 在判别器中,所有层中都使用LeakyReLu激活函数
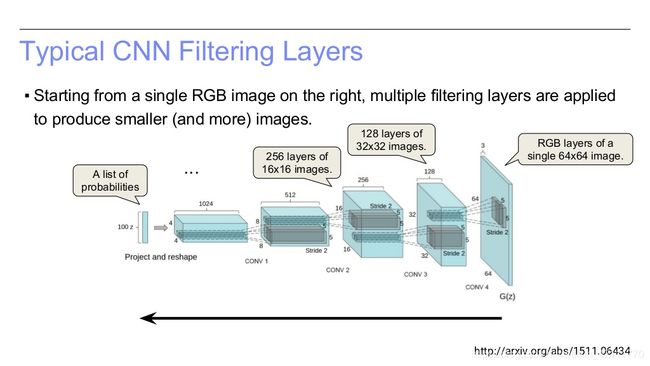
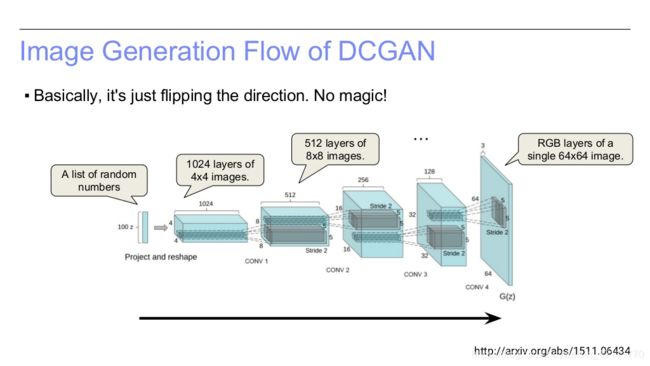
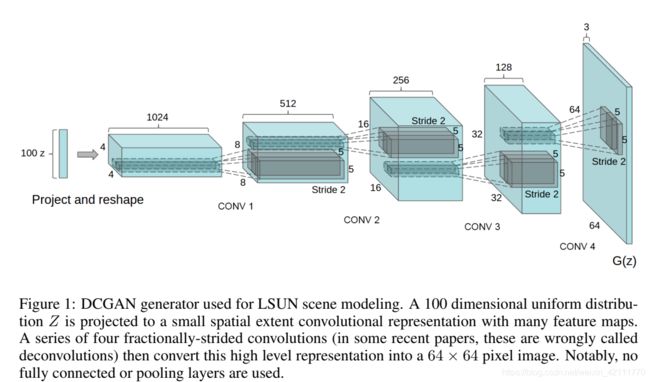 图4:深度卷积生成对抗网络
图4:深度卷积生成对抗网络
如图4所示,DCGAN的输入是个100维的均匀分布的向量,然后经过一系列的反卷积操作输出64*64大小的RGB图像。如下面三张PPT所示,DCGAN的操作恰恰与传统的CNN的计算方向相反,CNN中使用卷积操作,则DCGAN中使用反卷积(deconvolutional/transposed-convolution)。