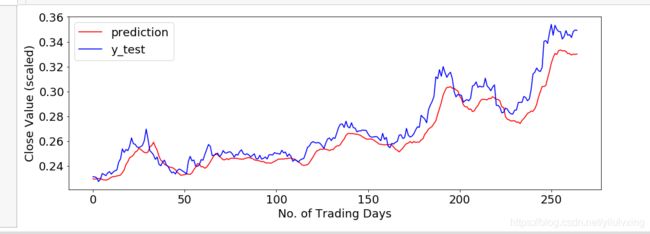
CNN & LSTM & Conv1D+LSTM 同一数据集预测案例分析
1:前言
利用CNN、LSTM 和Conv1D+LSTM 分别对同一数据集进行预测分析,并用训练集和测试集比较结果;
time_steps 设置为6,经过数据预处理和数据切分处理后,输入特征为4维,利用每个sample中的前5行数据预测第6个数据中的最后一个特征数值,属于多变量预测
代码放在github上,GitHub地址,分为.py文件和.ipynb文件,可以根据运行环境选择运行不同的文件,备注:文件名相同的.py和.ipynb文件代码相同。
算法分为:
- 数据预处理
- 数据切分
- 构建模型
- 测试数据集验证
- 对比预测值和真实值损失图像等
2:数据集
数据集为tcs_stock_2018-05-26.csv,包含1331条记录,时间日期从2013-01-01—2018-05-18,包含当日股票的最高值,最低值,开盘价格等数据特征。
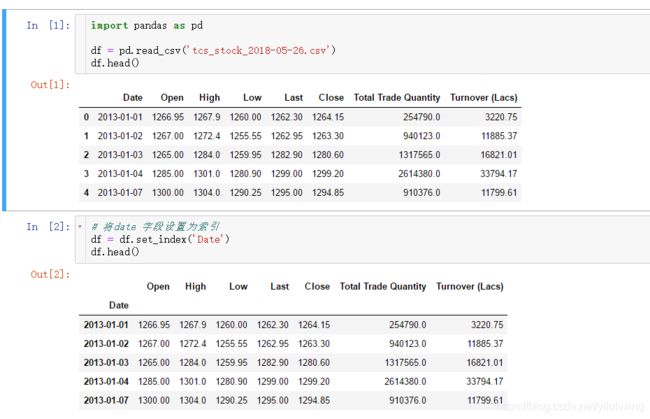
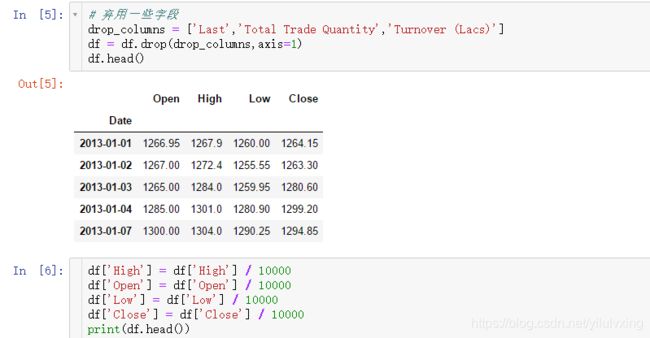
最终只保留开盘价,最高价,最低价和当日闭市价格,即:Open,High,Low,Close这四个特征,并统一进行归一化处理:
3:数据切分
time_step 设置为6,将数据集切分为训练数据集和测试数据集,并转换为array格式

取出其中一个sample的数据查看:
# 举例:用前5行数据,预测第6行的最后一个数据
# train
#[[[0.126695 0.12679 0.126 0.126415]
# [0.1267 0.12724 0.125555 0.12633 ]
# [0.1265 0.1284 0.125995 0.12806 ]
# [0.1285 0.1301 0.12809 0.12992 ]
# [0.13 0.1304 0.129025 0.129485]
# [0.1295 0.13043 0.12943 0.130025]]
# x_train
# [[[0.126695 0.12679 0.126 0.126415]
# [0.1267 0.12724 0.125555 0.12633 ]
# [0.1265 0.1284 0.125995 0.12806 ]
# [0.1285 0.1301 0.12809 0.12992 ]
# [0.13 0.1304 0.129025 0.129485]]
# y_train
#[0.130025]4:构建模型
构建CNN模型(其他LSTM和Conv1D+LSTM的build_model函数可在github上查看),下面代码是以CNN为例:
from __future__ import print_function
import math
from keras.models import Sequential
from keras.layers import Dense,Activation,Dropout,Flatten,Conv1D,MaxPooling1D
from keras.layers.recurrent import LSTM
from keras import losses
from keras import optimizers
def build_model(input):
model = Sequential()
model.add(Dense(128,input_shape=(input[0],input[1])))
model.add(Conv1D(filters=112,kernel_size=1,padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling1D(pool_size=2,padding='valid'))
model.add(Conv1D(filters=64,kernel_size=1,padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling1D(pool_size=1,padding='valid'))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(100,activation='relu',kernel_initializer='uniform'))
model.add(Dense(1,activation='relu',kernel_initializer='uniform'))
model.compile(loss='mse',optimizer='adam',metrics=['mae'])
return model
model = build_model([5,4,1])
# Summary of the Model
print(model.summary())
训练数据预测:
# 训练数据
from timeit import default_timer as timer
start = timer()
history = model.fit(x_train,
y_train,
batch_size=128,
epochs=35,
validation_split=0.2,
verbose=2)
end = timer()
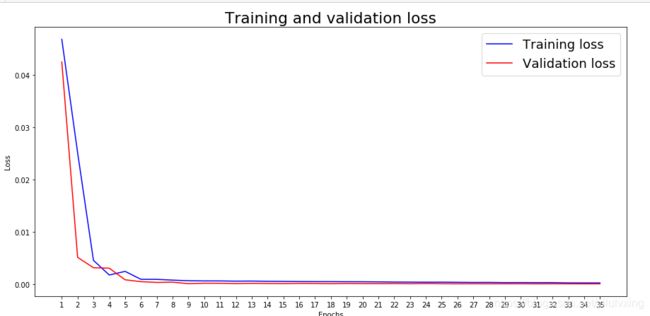
print(end - start)训练接和测试集损失函数曲线:
# 返回history
history_dict = history.history
history_dict.keys()
# 画出训练集和验证集的损失曲线
import matplotlib.pyplot as plt
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
loss_values50 = loss_values[0:150]
val_loss_values50 = val_loss_values[0:150]
epochs = range(1, len(loss_values50) + 1)
plt.plot(epochs, loss_values50, 'b',color = 'blue', label='Training loss')
plt.plot(epochs, val_loss_values50, 'b',color='red', label='Validation loss')
plt.rc('font', size = 18)
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.xticks(epochs)
fig = plt.gcf()
fig.set_size_inches(15,7)
#fig.savefig('img/tcstest&validationlosscnn.png', dpi=300)
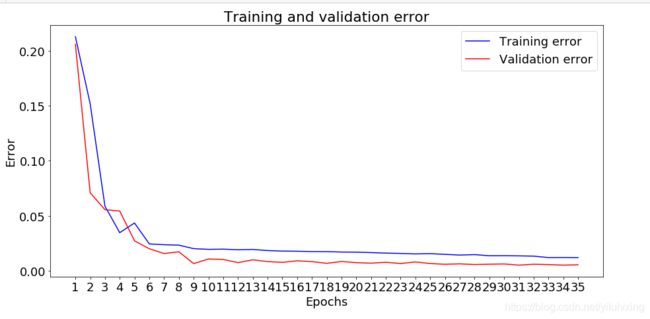
plt.show()结果如下:
另外的训练集和测试集误差函数曲线
真实值和测试集的预测值之间的误差图像