Python 深度学习--学习笔记(三)
路透社新闻分类问题
首先,导入数据:
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
限制每条新闻数据限制在常用的10 000个单词。
让我们看看数据的大小:
print(train_data.shape,train_labels.shape)
print(test_data.shape,test_labels.shape)
输出:
(8982,) (8982,)
(2246,) (2246,)
可知,训练集大小为8982,测试集有2246条。
接着,我们随便输出一条新闻看看:
print(train_data[3])
输出一个列表,里面都是1~10 000的数字,可知单词已经转化为对应的序列号了。
我们再来看看标签的大小:
print(min(train_labels))
print(max(train_labels))
输出:
0
45
可知,新闻有46(0~45)个类别。每个类别有一个对应的数字。
这里我们要处理数据,将数据转为one-hot形式,同时留出验证集,因为全连接层只能学习向量数据:
import numpy as np
def vectorize_sequences(sequences,dimension=10000):
results = np.zeros((len(sequences),dimension))
for i, sequence in enumerate(sequences):
results[i,sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = train_labels[:1000]
partial_y_train = train_labels[1000:]
留出验证集的目的是可以在训练过程中实时检查模型是否过拟合。
现在,定义模型:
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(46,activation='softmax'))
值得注意的是,输入input_shape为单个数据的大小,我们已将数据二进制向量化,这里输入大小为10 000.
同时,输出为46个新闻类别概率,激活函数为softmax。
然后,我们编译模型:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
optimizer(优化器):选择adam优化方案
loss(损失函数):这里需要注意,输出为46个新闻类别概率,而标签仍然为一个数字,我们可以在处理数据时,将标签one-hot化,(也可以用keras内置的to_categorical()),然后损失函数选择categorical_crossentropy。但我们也可以不处理标签,直接在损失函数中选择sparse_categorical_crossentropy。
metrics(评定标准):分类问题都是选择准确度。
现在,训练模型:
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val,y_val))
这里传入验证集:validation_data=(x_val,y_val)
输出结果:

可以看到,在训练每一个epoch后,都会输出验证集的损失值和准确度,来观察是否有过拟合,即准确度 acc 先上升后减小。
最后,我们来可视化训练数据:
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history['acc']
val_acc = history.history["val_acc"]
epochs = range(1,len(loss)+1)
plt.figure(1)
plt.plot(epochs,loss,'bo',label='Training loss')
plt.plot(epochs,val_loss,'b',label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.figure(2)
plt.plot(epochs,acc,'bo',label='Training accuracy')
plt.plot(epochs,val_acc,'b',label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
输出:
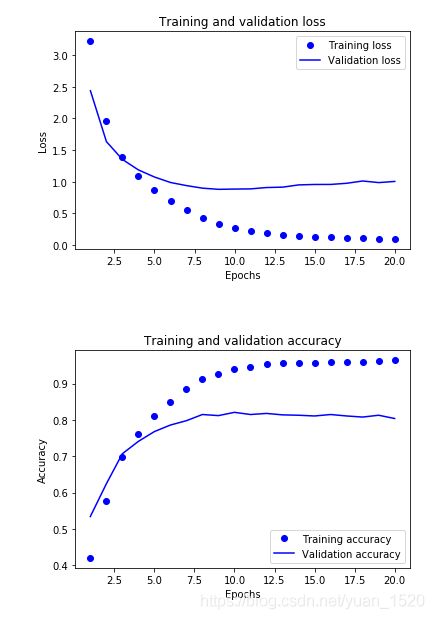
可以看出,validation accuracy曲线又开始减小的趋势,即发生过拟合。
我们在后面的学习中会学到抑制过拟合的方法。