Hadoop3.2.1 【 HDFS 】源码分析 :FSEditLog 解析
Table of Contents
一. 前言
二.transactionId机制
三.构造方法
四. FSEditLog状态机
4.1.initJournalsForWrite()
4.2.initSharedJournalsForRead()
4.3.openForWrite
4.4.endCurrentLogSegment()
4.5.close()
五.EditLogOutputStream
5.1.JournalSetOutputStream
5.2.EditLogFileOutputStream
5.2.1. 构造方法
5.2.2. 常量
5.2.2. write()方法、 setReadyToFlush()方法
5.2.3 EditsDoubleBuffer类
5.3.EditLogFileInputStream
5.4.EditLogFileInputStream
5.4.1. 构造方法
5.4.2. 属性
5.4.3. init 方法
5.4.5. EditLogInputStream #readOp 读取数据.
5.4.4.nextOpImpl实现
六.FSEditLog.log*()方法
6.1.logDelete()方法
6.2.logEdit()方法
6.3.beginTransaction()
6.5.endTransaction()方法
6.4.logSync()方法
一. 前言
在Namenode中, 命名空间( namespace, 指文件系统中的目录树、 文件元数据等信息) 是被全部缓存在内存中的, 一旦Namenode重启或者宕机, 内存中的所有数据将会全部丢失, 所以必须要有一种机制能够将整个命名空间持久化保存, 并且能在Namenode重启时重建命名空间。
目前Namenode的实现是将命名空间信息记录在一个叫作fsimage( 命名空间镜像) 的二进制文件中, fsimage将文件系统目录树中的每个文件或者目录的信息保存为一条记录, 每条记录中包括了该文件( 或目录) 的名称、 大小、 用户、 用户组、 修改时间、 创建时间等信息。 Namenode重启时, 会读取这个fsimage文件来重构命名空间。 但是fsimage始终是磁盘上的一个文件, 不可能时时刻刻都跟Namenode内存中的数据结构保持同步, 并且fsimage文件一般都很大( GB级别的很常见) , 如果所有的更新操作都实时地写fsimage文件, 则会导致Namenode运行得十分缓慢, 所以HDFS每过一段时间才更新一次fsimage文件.
HDFS将这些操作记录在editlog(编辑日志) 文件中,editlog是一个日志文件,HDFS客户端执行的所有写操作首先会被记录到editlog文件中。 HDFS会定期地将editlog文件与fsimage文件进行合并, 以保持fsimage跟Namenode内存中记录的命名空间完全同步。
在HDFS源码中, 使用FSEditLog类来管理editlog文件。 和fsimage文件不同, editlog文件会随着Namenode的运行实时更新, 所以FSEditLog类的实现依赖于底层的输入流和输出流, 同时FSEditLog类还需要对外提供大量的log*()方法用于记录命名空间的修改操作。

二.transactionId机制
TransactionId与客户端每次发起的RPC操作相关, 当客户端发起一次RPC请求对Namenode的命名空间修改后, Namenode就会在
editlog中发起一个新的transaction用于记录这次操作, 每个transaction会用一个唯一的transactionId标识。

■ edits_start transaction id-end transaction id: edits文件就是我们描述的editlog文件,edits文件中存放的是客户端执行的所有更新命名空间的操作。 每个edits文件都包含了文件名中start trancsaction id - end transaction id之间的所有事务。
比如 edits_0000000000000000001-0000000000000000006 , 这个文件记录了transaction id在1和6之间的所有事务(transaction)
■ edits_inprogress_start transaction id: 正在进行处理的editlog。 所有从start transaction id开始的新的修改操作都会记录在这个文件中, 直到HDFS重置(roll) 这个日志文件。 重置操作会将inprogress文件关闭, 并将inprogress文件改名为正常的editlog文件(如上一项所示) , 同时还会打开一个新的inprogress文件, 记录正在进行的事务。 例如当前文件夹中的edits_inprogress_0000000000000000478文件, 这个文件记录了所有transaction id大于478的新开始的事务, 我们将这个事务区间称为一个日志段落(segment) 。Namenode元数据文件夹中存在这个文件有两种可能: 要么是Active Namenode正在写入数据, 要么是前一个Namenode没有正确地关闭。
■ fsimage_end transaction id: fsimage文件是Hadoop文件系统元数据的一个永久性的检查点, 包含Hadoop文件系统中end transaction id前的完整的HDFS命名空间元数据镜像, 也就是HDFS所有目录和文件对应的INode的序列化信息。 以当前文件夹为例, fsimage_0000000000000000473就是fsimage_0000000000000000472与edits_0000000000000000473-0000000000000000473合并后的镜像文件, 保存了transaction id小于473的HDFS命名空间的元数据。 每个fsimage文件还有一个对应的md5文件, 用来确保fsimage文件的正确性, 以防止磁盘异常发生。
■ seen_txid: 这个文件中保存了上一个检查点(checkpoint) (合并edits和fsimage文件) 以及编辑日志重置(editlog roll) (持久化当前的inprogress文件并且创建一个新的inprogress文件) 时最新的事务id (transaction id) 。 要特别注意的是, 这个事务id并不是Namenode内存中最新的事务id, 因为seen_txid只在检查点操作以及编辑日志重置操作时更新。 这个文件的作用在于Namenode启动时, 可以利用这个文件判断是否有edits文件丢失。 例如, Namenode使用不同的目录保存fsimage以及edits文件, 如果保存edits的目录内容丢失, Namenode将会使用上一个检查点保存的fsimage启动, 那么上一个检查点之后的所有事务都会丢失。 为了防止发生这种状况, Namenode启动时会检查seen_txid并确保内存中加载的事务id至少超过seen_txid; 否则Namenode将终止启动操作。
/**
* TransactionId与客户端每次发起的RPC操作相关,
* 当客户端发起一次RPC请求对Namenode的命名空间修改后,
* Namenode就会在editlog中发起一个新的transaction用于记录这次操作,
* 每个transaction会用一个唯一的transactionId标识。
*
*/
private static class TransactionId {
public long txid;
TransactionId(long value) {
this.txid = value;
}
}
三.构造方法
FSEditLog 是通过newInstance方法进行构造的, 可以根据配置dfs.namenode.edits.asynclogging 生成不同的FSEditLog 实例, 默认是 FSEditLogAsync .


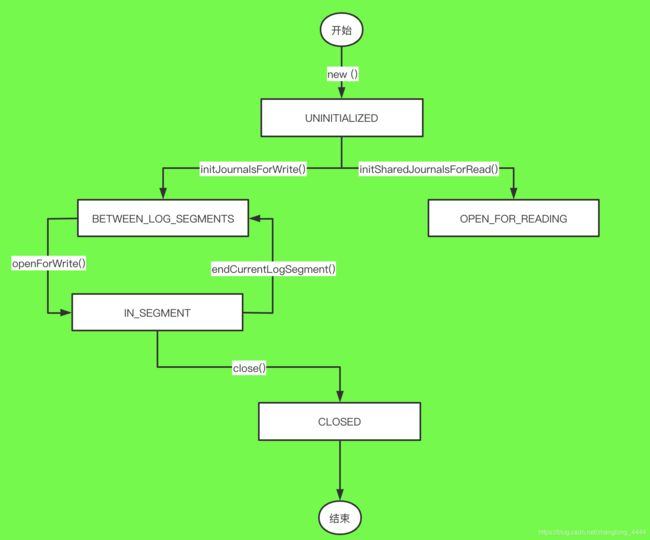
四. FSEditLog状态机
FSEditLog类被设计成一个状态机, 用内部类FSEditLog.State描述。
FSEditLog有以下5个状态。
■ UNINITIALIZED: editlog的初始状态。
■ BETWEEN_LOG_SEGMENTS: editlog的前一个segment已经关闭, 新的还没开始。
■ IN_SEGMENT: editlog处于可写状态。
■ OPEN_FOR_READING: editlog处于可读状态。
■ CLOSED: editlog处于关闭状态。
/**
*
* ■ UNINITIALIZED: editlog的初始状态。
* ■ BETWEEN_LOG_SEGMENTS: editlog的前一个segment已经关闭,新的还没开始。
* ■ IN_SEGMENT: editlog处于可写状态。
* ■ OPEN_FOR_READING: editlog处于可读状态。
* ■ CLOSED: editlog处于关闭状态。
*
* 对于非HA机制的情况:
* FSEditLog应该开始于UNINITIALIZED或者CLOSED状态
* (因为在构造FSEditLog对象时,FSEditLog的成员变量state默认为State.UNINITIALIZED)
*
* FSEditLog初始化完成之后进入BETWEEN_LOG_SEGMENTS 状态,
* 表示前一个segment已经关闭,新的还没开始,日志已经做好准备了。
* 当打开日志服务时,改变FSEditLog状态为IN_SEGMENT状态,表示可以写editlog文件了。
*
*
* 对于HA机制的情况:
* FSEditLog同样应该开始于UNINITIALIZED或者CLOSED状 态,
* 但是在完成初始化后FSEditLog并不进入BETWEEN_LOG_SEGMENTS状态,
* 而是进入OPEN_FOR_READING状态
* (
* 因为目前Namenode启动时都是以Standby模式启动的,
* 然后通过DFSHAAdmin发送命令把其中一个Standby NameNode转换成Active Namenode
* )。
*
*
*/
private enum State {
// editlog的初始状态。
UNINITIALIZED,
// editlog的前一个segment已经关闭,新的还没开始。
BETWEEN_LOG_SEGMENTS,
// editlog处于可写状态。
IN_SEGMENT,
// editlog处于可读状态。
OPEN_FOR_READING,
// editlog处于关闭状态。
CLOSED;
}
对于非HA机制的情况, FSEditLog应该开始于UNINITIALIZED或者CLOSED状态(因为在构造FSEditLog对象时, FSEditLog的成员变量state默认为State.UNINITIALIZED) 。 FSEditLog初始化完成之后进入BETWEEN_LOG_SEGMENTS状态, 表示前一个segment已经关闭, 新的还没开始, 日志已经做好准备了。 当打开日志服务时, 改变FSEditLog状态为IN_SEGMENT状态, 表示可以写editlog文件了
对于HA机制的情况, FSEditLog同样应该开始于UNINITIALIZED或者CLOSED状态, 但是在完成初始化后FSEditLog并不进入BETWEEN_LOG_SEGMENTS状态, 而是进入OPEN_FOR_READING状态( 因为目前Namenode启动时都是以Standby模式启动的, 然后通过DFSHAAdmin发送命令把其中一个Standby NameNode转换成Active Namenode) 。
4.1.initJournalsForWrite()
iniJournalsForWrite()方法是FSEditLog的public方法, 调用这个方法会将FSEditLog从UNINITIALIZED状态转换为BETWEEN_LOG_SEGMENTS状态
/**
* iniJournalsForWrite()方法是FSEditLog的public方法,
* 调用这个方法会将FSEditLog从 UNINITIALIZED状态转换为BETWEEN_LOG_SEGMENTS状态。
*/
public synchronized void initJournalsForWrite() {
Preconditions.checkState(state == State.UNINITIALIZED ||
state == State.CLOSED, "Unexpected state: %s", state);
//调用initJournals()方法
// initJournals()方法会根据传入的dirs 变量
// (保存的是editlog文件的存储位置,都是URI)
// 初始化journalSet字段 (JournalManager对象的集合)。
// 初始化之后,FSEditLog就可以调用journalSet对象的方法向多个日志存储位置写editlog文件了。
initJournals(this.editsDirs);
//状态转换为BETWEEN_LOG_SEGMENTS
state = State.BETWEEN_LOG_SEGMENTS;
}在这里会调用initJournals(this.editsDirs); 方法 进行初始化操作 . initJournals()方法会根据传入的dirs变量(保存的是editlog文件的存储位置, 都是URI) 初始化journalSet字段.(JournalManager对象的集合) 。 初始化之后, FSEditLog就可以调用journalSet对象的方法
向多个日志存储位置写editlog文件了
JournalManager类是负责在特定存储目录上持久化editlog文件的类, 它的format()方法负责格式化底层存储, startLogSegment()方法负责从指定事务id开始记录一个操作的段落, finalizeLogSegment()方法负责完成指定事务id区间的写操作。 这里之所以抽象这个接
口, 是因为Namenode可能将editlog文件持久化到不同类型的存储上, 也就需要不同类型的JournalManager来管理, 所以需要定义一个抽象的接口。 JoumalManager有多个子类, 普通的文件系统由FileJournalManager类管理、 共享NFS由BackupJournalManager类管理、 Bookkeeper由BookkeeperJournalManager类管理、 Quorum集群则由QuorumJournalManager类管理。
/**
* dirs editsDirs
* @param dirs
*/
private synchronized void initJournals(List dirs) {
// dfs.namenode.edits.dir.minimum 默认值: 1
int minimumRedundantJournals = conf.getInt(
DFSConfigKeys.DFS_NAMENODE_EDITS_DIR_MINIMUM_KEY,
DFSConfigKeys.DFS_NAMENODE_EDITS_DIR_MINIMUM_DEFAULT);
synchronized(journalSetLock) {
//初始化journalSet集合,存放存储路径对应的所有JournalManager对象
journalSet = new JournalSet(minimumRedundantJournals);
//根据传入的URI获取对应的JournalManager对象
for (URI u : dirs) {
boolean required = FSNamesystem.getRequiredNamespaceEditsDirs(conf)
.contains(u);
if (u.getScheme().equals(NNStorage.LOCAL_URI_SCHEME)) {
StorageDirectory sd = storage.getStorageDirectory(u);
if (sd != null) {
//本地URI,则加入FileJournalManager即可
journalSet.add(new FileJournalManager(conf, sd, storage),
required, sharedEditsDirs.contains(u));
}
} else {
//否则根椐URI创建对应的JournalManager对象,并放入journalSet中保存
journalSet.add(createJournal(u), required,
sharedEditsDirs.contains(u));
}
}
}
if (journalSet.isEmpty()) {
LOG.error("No edits directories configured!");
}
}
4.2.initSharedJournalsForRead()
initSharedJournalsForRead()方法是FSEditLog的public方法, 用在HA情况下。 调用这个方法会将FSEditLog从UNINITIALIZED状态转换为OPEN_FOR_READING状态。
与initJournalsForWrite()方法相同, initSharedJournalsForRead()方法也调用了initJournals()方法执行初始化操作, 只不过editlog文件的存储位置不同, 在HA的情况下,editlog文件的存储目录为共享存储目录, 这个共享存储目录由Active Namenode和StandbyNamenode共享读取。 [这里的共享存储待处理..]
// initSharedJournalsForRead()方法是FSEditLog的public方法,用在HA情况下。调用这个
//方法会将FSEditLog从UNINITIALIZED状态转换为OPEN_FOR_READING状态。
public synchronized void initSharedJournalsForRead() {
if (state == State.OPEN_FOR_READING) {
LOG.warn("Initializing shared journals for READ, already open for READ",
new Exception());
return;
}
Preconditions.checkState(state == State.UNINITIALIZED ||
state == State.CLOSED);
//对于HA的情况,editlog的日志存储目录为共享的目录sharedEditsDirs
initJournals(this.sharedEditsDirs);
state = State.OPEN_FOR_READING;
}
4.3.openForWrite
openForWrite()方法用于初始化editlog文件的输出流, 并且打开第一个日志段落(log segment) 。 在非HA机制下, 调用这个方法会完成BETWEEN_LOG_SEGMENTS状态到IN_SEGMENT状态的转换。
/**
* openForWrite()方法用于初始化editlog文件的输出流,
* 并且打开第一个日志段落(log segment)。
* 在非HA机制下,调用这个方法会完成BETWEEN_LOG_SEGMENTS状态到 IN_SEGMENT状态的转换。
* Initialize the output stream for logging, opening the first
* log segment.
*/
synchronized void openForWrite(int layoutVersion) throws IOException {
Preconditions.checkState(state == State.BETWEEN_LOG_SEGMENTS,
"Bad state: %s", state);
//返回最后一个写入log的transactionId+1,作为本次操作的transactionId , 假设当前的transactionId为31
long segmentTxId = getLastWrittenTxId() + 1;
// Safety check: we should never start a segment if there are
// newer txids readable.
List streams = new ArrayList();
//传入了参数segmentTxId,
// 这个参数会作为这次 操作的transactionId,
// 值为editlog已经记录的最新的transactionId加1(这里是 31+1=32)。
//
// selectInputStreams()方法会判断有没有一个以segmentTxId(32)开 始的日志,如果没有则表示当前transactionId 的值选择正确,可以打开新的editlog文件记录以segmentTxId开始的日志段落。 如果方法找到了包含这个transactionId的editlog文件,则表示出现了两个日志 transactionId交叉的情况,抛出异常。
journalSet.selectInputStreams(streams, segmentTxId, true, false);
//这里判断,有没有包含这个新的segmentTxId的editlog文件,如果有则抛出异常
if (!streams.isEmpty()) {
String error = String.format("Cannot start writing at txid %s " +
"when there is a stream available for read: %s",
segmentTxId, streams.get(0));
IOUtils.cleanupWithLogger(LOG,
streams.toArray(new EditLogInputStream[0]));
throw new IllegalStateException(error);
}
//写入日志
startLogSegmentAndWriteHeaderTxn(segmentTxId, layoutVersion);
assert state == State.IN_SEGMENT : "Bad state: " + state;
} 在所有editlog文件的存储路径上构造输出流,并将这些输 出流保存在FSEditLog的字段journalSet.journals中。
/**
*
* 这个方法调用了 journalSet.startLogSegment()方法在所有editlog文件的存储路径上构造输出流,
* 并将这些输 出流保存在FSEditLog的字段journalSet.journals中。
*
* Start writing to the log segment with the given txid.
* Transitions from BETWEEN_LOG_SEGMENTS state to IN_LOG_SEGMENT state.
*/
private void startLogSegment(final long segmentTxId, int layoutVersion)
throws IOException {
assert Thread.holdsLock(this);
LOG.info("Starting log segment at " + segmentTxId);
Preconditions.checkArgument(segmentTxId > 0,
"Bad txid: %s", segmentTxId);
Preconditions.checkState(state == State.BETWEEN_LOG_SEGMENTS,
"Bad state: %s", state);
Preconditions.checkState(segmentTxId > curSegmentTxId,
"Cannot start writing to log segment " + segmentTxId +
" when previous log segment started at " + curSegmentTxId);
Preconditions.checkArgument(segmentTxId == txid + 1,
"Cannot start log segment at txid %s when next expected " +
"txid is %s", segmentTxId, txid + 1);
numTransactions = 0;
totalTimeTransactions = 0;
numTransactionsBatchedInSync.set(0L);
// TODO no need to link this back to storage anymore!
// See HDFS-2174.
storage.attemptRestoreRemovedStorage();
try {
//初始化editLogStream
editLogStream = journalSet.startLogSegment(segmentTxId, layoutVersion);
} catch (IOException ex) {
throw new IOException("Unable to start log segment " +
segmentTxId + ": too few journals successfully started.", ex);
}
//当前正在写入txid设置为segmentTxId
curSegmentTxId = segmentTxId;
state = State.IN_SEGMENT;
}4.4.endCurrentLogSegment()
endCurrentLogSegment()会将当前正在写入的日志段落关闭, 它调用了journalSet.finalizeLogSegment()方法将curSegmentTxid -> lastTxId之间的操作持久化到磁盘上。
这个方法会将FSEditLog状态机更改为BETWEEN_LOG_SEGMENTS状态.
/**
*
* endCurrentLogSegment()会将当前正在写入的日志段落关闭,
*
* 它调用了journalSet.finalizeLogSegment()方法将
*
* curSegmentTxid -> lastTxId之间的操作持久化到磁盘上。
*
* 如上例中, 调用endCurrentLogSegment()方法就会产生editlog文件edits_0032-0034。
* 同时这个方法会将FSEditLog状态机更改为BETWEEN_LOG_SEGMENTS状态
*
*
* Finalize the current log segment.
* Transitions from IN_SEGMENT state to BETWEEN_LOG_SEGMENTS state.
*/
public synchronized void endCurrentLogSegment(boolean writeEndTxn) {
LOG.info("Ending log segment " + curSegmentTxId +
", " + getLastWrittenTxId());
Preconditions.checkState(isSegmentOpen(),
"Bad state: %s", state);
if (writeEndTxn) {
logEdit(LogSegmentOp.getInstance(cache.get(),
FSEditLogOpCodes.OP_END_LOG_SEGMENT));
}
// always sync to ensure all edits are flushed.
logSyncAll();
printStatistics(true);
final long lastTxId = getLastWrittenTxId();
//获取当前写入的最后一个id
final long lastSyncedTxId = getSyncTxId();
Preconditions.checkArgument(lastTxId == lastSyncedTxId,
"LastWrittenTxId %s is expected to be the same as lastSyncedTxId %s",
lastTxId, lastSyncedTxId);
try {
//调用journalSet.finalizeLogSegment将curSegmentTxid -> lastTxId之间的操作
// 写入磁盘(例如editlog文件edits_0032-0034)
journalSet.finalizeLogSegment(curSegmentTxId, lastTxId);
editLogStream = null;
} catch (IOException e) {
//All journals have failed, it will be handled in logSync.
}
//更改状态机的状态
state = State.BETWEEN_LOG_SEGMENTS;
}journalSet.finalizeLogSegment()方法也会调用mapJournalsAndReportErrors()方法将finalizeLogSegment()调用前转到journals集合中保存的所有的JournalManager对象上。比如FileJournalManager, FileJoumalManager.finalizeLogSegment()方法会将edit_inprogress文件改名为edit文件, 新生成的edit文件覆盖了curSegmentTxid -> lastTxId之间的所有事务。
@Override
synchronized public void finalizeLogSegment(long firstTxId, long lastTxId) throws IOException {
// 原有的inprogress文件
File inprogressFile = NNStorage.getInProgressEditsFile(sd, firstTxId);
// 构造新的edit文件
File dstFile = NNStorage.getFinalizedEditsFile( sd, firstTxId, lastTxId);
LOG.info("Finalizing edits file " + inprogressFile + " -> " + dstFile);
Preconditions.checkState(!dstFile.exists(),
"Can't finalize edits file " + inprogressFile + " since finalized file " +
"already exists");
try {
//执行重命名操作
NativeIO.renameTo(inprogressFile, dstFile);
} catch (IOException e) {
errorReporter.reportErrorOnFile(dstFile);
throw new IllegalStateException("Unable to finalize edits file " + inprogressFile, e);
}
if (inprogressFile.equals(currentInProgress)) {
currentInProgress = null;
}
}
4.5.close()
close()方法用于关闭editlog文件的存储, 完成了IN_SEGMENT到CLOSED状态的改变。 close()会首先等待sync操作完成, 然后调用endCurrentLogSegment()方法, 将当前正在进行写操作的日志段落结束。 之后close()方法会关闭journalSet对象, 并将FSEditLog状态机转变为CLOSED状态。
/**
*
* close()方法用于关闭editlog文件的存储, 完成了IN_SEGMENT到CLOSED状态的改
* 变。 close()会首先等待sync操作完成, 然后调用上一节介绍的endCurrentLogSegment()方
* 法, 将当前正在进行写操作的日志段落结束。 之后close()方法会关闭journalSet对象, 并将
* FSEditLog状态机转变为CLOSED状态。
*
*
* Shutdown the file store.
*/
synchronized void close() {
if (state == State.CLOSED) {
LOG.debug("Closing log when already closed");
return;
}
try {
if (state == State.IN_SEGMENT) {
assert editLogStream != null;
//如果有sync操作, 则等待sync操作完成
waitForSyncToFinish();
//结束当前logSegment
endCurrentLogSegment(true);
}
} finally {
//关闭journalSet
if (journalSet != null && !journalSet.isEmpty()) {
try {
synchronized(journalSetLock) {
journalSet.close();
}
} catch (IOException ioe) {
LOG.warn("Error closing journalSet", ioe);
}
}
//将状态机更改为CLOSED状态
state = State.CLOSED;
}
}
五.EditLogOutputStream
FSEditLog类会调用FSEditLog.editLogStream字段的write()方法在editlog文件中记录一个操作, 数据会先被写入到editlog文件输出流的缓存中, 然后FSEditLog类会调用editLogStream.flush()方法将缓存中的数据同步到磁盘上。
FSEditLog的editLogStream字段是EditLogOutputStream类型的, EditLogOutputStream类是一个抽象类, 它定义了向持久化存储上写editlog文件的相关接口。
EditLogOutputStream定义了多个子类来向不同存储系统上的editlog文件中写入数据。

5.1.JournalSetOutputStream
JournalSetOutputStream类是EditLogOutputStream的子类, 在JournalSetOutputStream对象上调用的所有EditLogOutputStream接口方法都会被前转到FSEditLog.journalSet字段中保存的editlog文件在所有存储位置上的输出流对象(通过调用mapJournalsAndReportErrors()方法实现) 。
FSEditLog的editLogStream字段就是JournalSetOutputStream类型的(是在startLogSegment()方法中赋值的) , 通过调用JournalSetOutputStream对象提供的方法, FSEditLog可以将Namenode多个存储位置上的editlog文件输出流对外封装成一个输出流, 大大方便了调用。
JournalSetOutputStream类是通过mapJournalsAndReportErrors()方法, 将EditLogOutputStream接口上的write()调用前转到了FSEditLog中保存的所有存储路径上editlog文件对应的EditLogOutputStream输出流对象上的。 这个方法会遍历
FSEditLog.journalSet.journals集合, 然后将write()请求前转到journals集合中保存的所有JournalAndStream对象上。 journalSet的journals字段是一个JournalAndStream对象的集合,JournalAndStream对象封装了一个JournalManager对象, 以及在这个JournalManager上打开
的editlog文件的EditLogOutputStream对象。
journalSet.journals字段是在FSEditLog.startLogSegment()方法中赋值的 , 这个方法调用了journalSet.startLogSegment()方法在所有editlog文件的存储路径上构造输出流, 并将这些输出流保存在FSEditLog的journalSet.journals字段中。

/**
* Apply the given operation across all of the journal managers, disabling
* any for which the closure throws an IOException.
* @param closure {@link JournalClosure} object encapsulating the operation.
* @param status message used for logging errors (e.g. "opening journal")
* @throws IOException If the operation fails on all the journals.
*/
private void mapJournalsAndReportErrors(
JournalClosure closure, String status) throws IOException{
List badJAS = Lists.newLinkedList();
//遍历journals字段中保存的所有JournalAndStream对象
for (JournalAndStream jas : journals) {
try {
//在闭包对象上调用apply()方法前转请求
closure.apply(jas);
} catch (Throwable t) {
if (jas.isRequired()) {
final String msg = "Error: " + status + " failed for required journal ("
+ jas + ")";
LOG.error(msg, t);
// If we fail on *any* of the required journals, then we must not
// continue on any of the other journals. Abort them to ensure that
// retry behavior doesn't allow them to keep going in any way.
abortAllJournals();
// the current policy is to shutdown the NN on errors to shared edits
// dir. There are many code paths to shared edits failures - syncs,
// roll of edits etc. All of them go through this common function
// where the isRequired() check is made. Applying exit policy here
// to catch all code paths.
terminate(1, msg);
} else {
LOG.error("Error: " + status + " failed for (journal " + jas + ")", t);
badJAS.add(jas);
}
}
}
disableAndReportErrorOnJournals(badJAS);
if (!NameNodeResourcePolicy.areResourcesAvailable(journals,
minimumRedundantJournals)) {
String message = status + " failed for too many journals";
LOG.error("Error: " + message);
throw new IOException(message);
}
} mapJournalsAndReportErrors()方法在调用时传入了一个闭包对象closure,这个对象是在JournalSetOutputStream实现的EditLogOutputStream接口方法上定义的。 以JournalSetOutputStream.write()方法为例, write()方法定义了写操作的闭包对象, 这个闭
包对象会提取出JournalAndStream对象中封装的EditLogOutputStream对象, 然后调用这个对象上的write()方法来完成写数据的功能。 通过这种闭包机制, JournalSetOutputStream完成了将EditLogOutputStream接口上的write()调用前转到JournalAndStream保存的EditLogOutputStream对象上的操作。
写入方法:
@Override
public void write(final FSEditLogOp op)
throws IOException {
mapJournalsAndReportErrors(new JournalClosure() {
@Override
public void apply(JournalAndStream jas) throws IOException {
if (jas.isActive()) {
// 提取出JournalAndStream对象中封装的EditLogOutputStream对象,
// 并在EditLogOutputStream对象上调用write()方法
jas.getCurrentStream().write(op);
}
}
}, "write op");
}
5.2.EditLogFileOutputStream
EditLogFileOutputStream是向本地文件系统中保存的editlog文件写数据的输出流, 向EditLogFileOutputStream写数据时, 数据首先被写入到输出流的缓冲区中, 当显式地调用flush()操作后, 数据才会从缓冲区同步到editlog文件中。
5.2.1. 构造方法
/**
* Creates output buffers and file object.
*
* @param conf
* Configuration object
* @param name
* File name to store edit log
* @param size
* Size of flush buffer
* @throws IOException
*/
public EditLogFileOutputStream(Configuration conf, File name, int size)
throws IOException {
super();
shouldSyncWritesAndSkipFsync = conf.getBoolean(
DFSConfigKeys.DFS_NAMENODE_EDITS_NOEDITLOGCHANNELFLUSH,
DFSConfigKeys.DFS_NAMENODE_EDITS_NOEDITLOGCHANNELFLUSH_DEFAULT);
file = name;
doubleBuf = new EditsDoubleBuffer(size);
RandomAccessFile rp;
if (shouldSyncWritesAndSkipFsync) {
rp = new RandomAccessFile(name, "rws");
} else {
rp = new RandomAccessFile(name, "rw");
}
fp = new FileOutputStream(rp.getFD()); // open for append
fc = rp.getChannel();
fc.position(fc.size());
}5.2.2. 常量
public static final int MIN_PREALLOCATION_LENGTH = 1024 * 1024;
// 输出流对应的editlog文件。
private File file;
// editlog文件对应的输出流。
private FileOutputStream fp; // file stream for storing edit logs
// editlog文件对应的输出流通道。
private FileChannel fc; // channel of the file stream for sync
// 一个具有两块缓存的缓冲区, 数据必须先写入缓存, 然后再由缓存同步到磁盘上。
private EditsDoubleBuffer doubleBuf;
//用来扩充editlog文件大小的数据块。 当要进行同步操作时,
// 如果editlog文件不够大, 则使用fill来扩充editlog。
// 文件最小1M
static final ByteBuffer fill = ByteBuffer.allocateDirect(MIN_PREALLOCATION_LENGTH);
private boolean shouldSyncWritesAndSkipFsync = false;
private static boolean shouldSkipFsyncForTests = false;
// EditLogFileOutputStream有一个static的代码段, 将fill字段用
// FSEditLogOpCodes.OP_INVALID 字节填满。
static {
fill.position(0);
for (int i = 0; i < fill.capacity(); i++) {
fill.put(FSEditLogOpCodes.OP_INVALID.getOpCode());
}
}
■ file: 输出流对应的editlog文件。
■ fp: editlog文件对应的输出流。
■ fc: editlog文件对应的输出流通道。
■ doubleBuf: 一个具有两块缓存的缓冲区, 数据必须先写入缓存, 然后再由缓存同步到磁盘上。
■ fill: 用来扩充editlog文件大小的数据块。 默认填充 1M大小的文件.这里单独说了一下静态方法
在创建[ edits_inprogress_0000000000000000485 ]文件的时候, 首先会用"-1"填充1M大小的文件空间,然后将写入的指针归0. 当有数据的时候,进行写入, 写入的时候,会覆盖之前预制填充的数据. 但不管怎么样, 如果数据大小不满1M的话, 那么edits文件的大小最小为1M.
每次重启namenode 的时候都会将之前的edits_inprogress文件关闭,并重命名为edits_**** 文件, 创建一个新的edits_inprogress_0000000000000000485文件.
5.2.2. write()方法、 setReadyToFlush()方法
// 直接调用doubleBuf中的对应方法
// 向输出流写入一个操作
@Override
public void write(FSEditLogOp op) throws IOException {
//向doubleBuf写入FSEditLogOp对象
doubleBuf.writeOp(op, getCurrentLogVersion());
}
/**
*
* 为同步数据做准备
* 调用doubleBuf.setReadyToFlush()交换两个缓冲区
*
* All data that has been written to the stream so far will be flushed. New
* data can be still written to the stream while flushing is performed.
*/
@Override
public void setReadyToFlush() throws IOException {
doubleBuf.setReadyToFlush();
}
flushAndSync()方法则用于将输出流中缓存的数据同步到磁盘上的editlog文件中。
/**
*
* 将准备好的缓冲区刷新到持久性存储。
* 由于会刷新和同步readyBuffer,因此currentBuffer不会累积新的日志记录,因此不会刷新。
*
* Flush ready buffer to persistent store. currentBuffer is not flushed as it
* accumulates new log records while readyBuffer will be flushed and synced.
*/
@Override
public void flushAndSync(boolean durable) throws IOException {
if (fp == null) {
throw new IOException("Trying to use aborted output stream");
}
if (doubleBuf.isFlushed()) {
LOG.info("Nothing to flush");
return;
}
// preallocate()方法用于在editLog文件大小不够时, 填充editlog文件。
preallocate(); // preallocate file if necessary
//将缓存中的数据同步到editlog文件中。
doubleBuf.flushTo(fp);
if (durable && !shouldSkipFsyncForTests && !shouldSyncWritesAndSkipFsync) {
fc.force(false); // metadata updates not needed
}
}
5.2.3 EditsDoubleBuffer类
EditsDoubleBuffer中包括两块缓存, 数据会先被写入到EditsDoubleBuffer的一块缓存中, 而EditsDoubleBuffer的另一块缓存可能正在进行磁盘的同步操作(就是将缓存中的文件写入磁盘的操作) 。
EditsDoubleBuffer这样的设计会保证输出流进行磁盘同步操作的同时, 并不影响数据写入的功能。
//正在写入的缓冲区
private TxnBuffer bufCurrent; // current buffer for writing
//准备好同步的缓冲区
private TxnBuffer bufReady; // buffer ready for flushing
//缓冲区的大小 默认 512K
private final int initBufferSize;输出流要进行同步操作时, 首先要调用EditsDoubleBuffer.setReadyToFlush()方法交换两个缓冲区, 将正在写入的缓存改变为同步缓存, 然后才可以进行同步操作。
// 将正在写入的缓存改变为同步缓存, 然后才可以进行同步操作。
public void setReadyToFlush() {
assert isFlushed() : "previous data not flushed yet";
//交换两个缓冲区
TxnBuffer tmp = bufReady;
bufReady = bufCurrent;
bufCurrent = tmp;
}完成了setReadyToFlush()调用之后, 输出流就可以调用flushTo()方法将同步缓存中的数据写入到文件中。
/**
* Writes the content of the "ready" buffer to the given output stream,
* and resets it. Does not swap any buffers.
*
*/
public void flushTo(OutputStream out) throws IOException {
//将同步缓存中的数据写入文件
bufReady.writeTo(out); // write data to file
//将同步缓存中保存的数据清空
bufReady.reset(); // erase all data in the buffer
}
5.3.EditLogFileInputStream
EditLogFileInputStream类抽象了从持久化存储上读editlog文件的相关接口。
5.4.EditLogFileInputStream
EditLogFileInputStream定义了本地文件系统的editlog文件的输入流。 它定义的方法都很简单, 都是返回了EditLogFileInputStream初始化以后的相应字段, 或者调用了FSEditLogOp.Reader对象的readOp()方法从editlog文件中解析出一个FSEditLogOp对象。
5.4.1. 构造方法
private EditLogFileInputStream(LogSource log,
long firstTxId, long lastTxId,
boolean isInProgress) {
this.log = log;
this.firstTxId = firstTxId;
this.lastTxId = lastTxId;
this.isInProgress = isInProgress;
// 最大值 50 * 1024 * 1024 ==> 50M ???????
this.maxOpSize = DFSConfigKeys.DFS_NAMENODE_MAX_OP_SIZE_DEFAULT;
}
5.4.2. 属性
private final LogSource log;
private final long firstTxId;
private final long lastTxId;
private final boolean isInProgress;
private int maxOpSize;
static private enum State {
UNINIT,
OPEN,
CLOSED
}
private State state = State.UNINIT;
private InputStream fStream = null;
private int logVersion = 0;
private FSEditLogOp.Reader reader = null;
private FSEditLogLoader.PositionTrackingInputStream tracker = null;
private DataInputStream dataIn = null;
static final Logger LOG = LoggerFactory.getLogger(EditLogInputStream.class);
5.4.3. init 方法
private void init(boolean verifyLayoutVersion)
throws LogHeaderCorruptException, IOException {
Preconditions.checkState(state == State.UNINIT);
BufferedInputStream bin = null;
try {
fStream = log.getInputStream();
bin = new BufferedInputStream(fStream);
tracker = new FSEditLogLoader.PositionTrackingInputStream(bin);
dataIn = new DataInputStream(tracker);
try {
logVersion = readLogVersion(dataIn, verifyLayoutVersion);
} catch (EOFException eofe) {
throw new LogHeaderCorruptException("No header found in log");
}
if (logVersion == -1) {
// The edits in progress file is pre-allocated with 1MB of "-1" bytes
// when it is created, then the header is written. If the header is
// -1, it indicates the an exception occurred pre-allocating the file
// and the header was never written. Therefore this is effectively a
// corrupt and empty log.
throw new LogHeaderCorruptException("No header present in log (value " +
"is -1), probably due to disk space issues when it was created. " +
"The log has no transactions and will be sidelined.");
}
// We assume future layout will also support ADD_LAYOUT_FLAGS
if (NameNodeLayoutVersion.supports(
LayoutVersion.Feature.ADD_LAYOUT_FLAGS, logVersion) ||
logVersion < NameNodeLayoutVersion.CURRENT_LAYOUT_VERSION) {
try {
LayoutFlags.read(dataIn);
} catch (EOFException eofe) {
throw new LogHeaderCorruptException("EOF while reading layout " +
"flags from log");
}
}
reader = FSEditLogOp.Reader.create(dataIn, tracker, logVersion);
reader.setMaxOpSize(maxOpSize);
state = State.OPEN;
} finally {
if (reader == null) {
IOUtils.cleanupWithLogger(LOG, dataIn, tracker, bin, fStream);
state = State.CLOSED;
}
}
}5.4.5. EditLogInputStream #readOp 读取数据.
/**
* Read an operation from the stream
* @return an operation from the stream or null if at end of stream
* @throws IOException if there is an error reading from the stream
*/
public FSEditLogOp readOp() throws IOException {
FSEditLogOp ret;
if (cachedOp != null) {
ret = cachedOp;
cachedOp = null;
return ret;
}
return nextOp();
}5.4.4.nextOpImpl实现
// skipBrokenEdits 是否跳过阻塞的edits .
private FSEditLogOp nextOpImpl(boolean skipBrokenEdits) throws IOException {
FSEditLogOp op = null;
switch (state) {
case UNINIT:
try {
// 执行初始化操作
init(true);
} catch (Throwable e) {
LOG.error("caught exception initializing " + this, e);
if (skipBrokenEdits) {
return null;
}
Throwables.propagateIfPossible(e, IOException.class);
}
Preconditions.checkState(state != State.UNINIT);
return nextOpImpl(skipBrokenEdits);
case OPEN:
//读取 FSEditLogOp类型操作
op = reader.readOp(skipBrokenEdits);
if ((op != null) && (op.hasTransactionId())) {
long txId = op.getTransactionId();
if ((txId >= lastTxId) &&
(lastTxId != HdfsServerConstants.INVALID_TXID)) {
//
// Sometimes, the NameNode crashes while it's writing to the
// edit log. In that case, you can end up with an unfinalized edit log
// which has some garbage at the end.
// JournalManager#recoverUnfinalizedSegments will finalize these
// unfinished edit logs, giving them a defined final transaction
// ID. Then they will be renamed, so that any subsequent
// readers will have this information.
//
// Since there may be garbage at the end of these "cleaned up"
// logs, we want to be sure to skip it here if we've read everything
// we were supposed to read out of the stream.
// So we force an EOF on all subsequent reads.
//
long skipAmt = log.length() - tracker.getPos();
if (skipAmt > 0) {
if (LOG.isDebugEnabled()) {
LOG.debug("skipping " + skipAmt + " bytes at the end " +
"of edit log '" + getName() + "': reached txid " + txId +
" out of " + lastTxId);
}
tracker.clearLimit();
IOUtils.skipFully(tracker, skipAmt);
}
}
}
break;
case CLOSED:
break; // return null
}
return op;
}
六.FSEditLog.log*()方法
FSEditLog类最重要的作用就是在editlog文件中记录Namenode命名空间的更改, FSEditLog类对外提供了若干log*()方法用于执行这个操作。
6.1.logDelete()方法
logDelete()方法用于在editlog文件中记录删除HDFS文件的操作。
logDelete()方法首先会构造一个DeleteOp对象, 这个DeleteOp类是FSEditLogOp类的子类, 用于记录删除操作的相关信息, 包括了ClientProtocol.delete()调用中所有参数携带的信息。构造DeleteOp对象后, logDelete()方法会调用logRpcIds()方法在DeleteOp对象中添加RPC调用相关信息, 之后logDelete()方法会调用logEdit()方法在editlog文件中记录这次删除操作。 l
/**
* Add delete file record to edit log
*/
void logDelete(String src, long timestamp, boolean toLogRpcIds) {
// 构造DeleteOp对象
DeleteOp op = DeleteOp.getInstance(cache.get())
.setPath(src)
.setTimestamp(timestamp);
//记录RPC调用相关信息
logRpcIds(op, toLogRpcIds);
//调用logEdit()方法记录删除操作
logEdit(op);
}
6.2.logEdit()方法
基本上所有的log*()方法(例如logDelete()、 logCloseFile()) 在底层都调用了logEdit()方法来执行记录操作, 这里会传入一个FSEditLogOp对象来标识当前需要被记录的操作类型以及操作的信息。
/**
* Write an operation to the edit log.
*
* Additionally, this will sync the edit log if required by the underlying
* edit stream's automatic sync policy (e.g. when the buffer is full, or
* if a time interval has elapsed).
*/
void logEdit(final FSEditLogOp op) {
boolean needsSync = false;
synchronized (this) {
assert isOpenForWrite() :
"bad state: " + state;
// 如果自动同步开启, 则等待同、 步完成
// wait if an automatic sync is scheduled
waitIfAutoSyncScheduled();
// check if it is time to schedule an automatic sync
needsSync = doEditTransaction(op);
if (needsSync) {
isAutoSyncScheduled = true;
}
}
// Sync the log if an automatic sync is required.
if (needsSync) {
logSync();
}
}
// 同步操作, 即使是多个线程, 依旧会进行同步操作. txid 不会错乱
// 保证了多个线程调用FSEditLog.log*()方法向editlog文件中写数据时,
// editlog文件记录的内容不会相互影响。
// 同时, 也保证了这几个并发线程保存操作对应的transactionId(通过调用beginTransaction()方法获得,
synchronized boolean doEditTransaction(final FSEditLogOp op) {
//开启一个新的transaction , 更新 txid
long start = beginTransaction();
op.setTransactionId(txid);
try {
// 使用editLogStream写入Op操作
editLogStream.write(op);
} catch (IOException ex) {
// All journals failed, it is handled in logSync.
} finally {
op.reset();
}
//结束当前的transaction
endTransaction(start);
//检查是否需要强制同步
return shouldForceSync();
}
logEdit()方法会调用beginTransaction()方法在editlog文件中开启一个新的transaction, 然后使用editlog输入流写入要被记录的操作, 接下来调用endTransaction()方法关闭这个transaction, 最后调用logSync()方法将写入的信息同步到磁盘上。
logEdit()方法调用beginTransaction()、 editLogStream.write()以及endTransaction()三个方法时使用了synchronized关键字进行同步操作, 这样就保证了多个线程调用FSEditLog.log*()方法向editlog文件中写数据时, editlog文件记录的内容不会相互影响。 同时, 也保证了这几个并发线程保存操作对应的transactionId(通过调用beginTransaction()方法获得) 是唯一并递增的。
logEdit()方法中调用logSync()方法执行刷新操作的语句并不在synchronized代码段中。 这是因为调用logSync()方法必然会触发写editlog文件的磁盘操作, 这是一个非常耗时的操作, 如果放入同步模块中会造成其他调用FSEditLog.log*()线程的等待时间过长。 所以, HDFS设计者将需要进行同步操作的synchronized代码段放入logSync()方法中, 也就让输出日志记录和刷新缓冲区数据到磁盘这两个操作分离了。 同时, 利用EditLogOutputStream的两个缓冲区, 使得日志记录和刷新缓冲区数据这两个操作可以并发执行, 大大地提高了Namenode的吞吐量。
6.3.beginTransaction()
logEdit()方法会调用beginTransaction()方法开启一个新的transaction, 也就是将FSEditLog.txid字段增加1并作为当前操作的transactionId。 FSEditLog.txid字段维护了一个全局递增的transactionId, 这样也就保证了FSEditLog为所有操作分配的transactionId是唯一且递增的。 调用beginTransaction()方法之后会将新申请的transactionId放入ThreadLocal的变量my TransactionId中, myTransactionId保存了当前线程记录操作对应的transactionId, 方便了以后线程做sync同步操作。
对于FSEditLog类, 可能同时有多个线程并发地调用log*()方法执行日志记录操作,所以FSEditLog类使用了一个ThreadLocal变量myTransactionId为每个调用log*()操作的线程保存独立的txid, 这个txid为当前线程记录操作对应的transactionId。
/**
* logEdit()方法会调用beginTransaction()方法开启一个新的transaction, 也就是将
* FSEditLog.txid字段增加1并作为当前操作的transactionId。 FSEditLog.txid字段维护了一个
* 全局递增的transactionId, 这样也就保证了FSEditLog为所有操作分配的transactionId是唯一
* 且递增的。 调用beginTransaction()方法之后会将新申请的transactionId放入ThreadLocal的变
* 量my TransactionId中, myTransactionId保存了当前线程记录操作对应的transactionId, 方
* 便了以后线程做sync同步操作。
*
* @return
*/
private long beginTransaction() {
assert Thread.holdsLock(this);
// get a new transactionId
// 全局的transactionId ++
txid++;
//
// 使用ThreadLocal变量保存当前线程持有的transactionId
// record the transactionId when new data was written to the edits log
//
TransactionId id = myTransactionId.get();
id.txid = txid;
return monotonicNow();
}6.5.endTransaction()方法
logEdit()方法会调用endTransaction()方法结束一个transaction, 这个方法就是更改一些统计数据,
private void endTransaction(long start) {
assert Thread.holdsLock(this);
// update statistics
long end = monotonicNow();
numTransactions++;
totalTimeTransactions += (end-start);
if (metrics != null) // Metrics is non-null only when used inside name node
metrics.addTransaction(end-start);
}6.4.logSync()方法
logEdit()方法通过调用beginTransaction()方法成功地获取一个transactionId之后, 就会通过输出流向editlog文件写数据以记录当前的操作, 但是写入的这些数据并没有直接保存在editlog文件中, 而是暂存在输出流的缓冲区中。 所以当logEdit()方法将一个完整的操作写入输出流后, 需要调用logSync()方法同步当前线程对editlog文件所做的修改。
editlog同步策略:
■ 所有的操作项同步地写入缓存时, 每个操作会被赋予一个唯一的transactionId。
■ 当一个线程要将它的操作同步到editlog文件中时, logSync()方法会使用ThreadLocal变量myTransactionId获取该线程需要同步的transactionId, 然后对比这个transactionId和已经同步到editlog文件中的transactionId。 如果当前线程的transactionId大于editlog文件中的transactionId, 则表明editlog文件中记录的数据不是最新的, 同时如果当前没有别的线程执行同步操作, 则开始同步操作将输出流缓存中的数据写入editlog文件中。 需要注意的是, 由于editlog输出流使用了双buffer的结构, 所以在进行sync操作的同时, 并不影响editlog输出流的使用。
■ 在logSync()方法中使用isSyncRunning变量标识当前是否有线程正在进行同步操作, 这里注意isSyncRunning是一个volatile的boolean类型变量。
logSync()方法分为以下三个部分, 并分开进行加锁操作, 这样的设计提高了并发的程度:
■ 判断当前操作是否已经同步到了editlog文件中, 如果还没有同步, 则将editlog的双buffer调换位置, 为同步操作做准备, 同时将isSyncRunning标志位设置为true, 这部分代码需要进行synchronized加锁操作。
■ 调用logStream.flush()方法将缓存的数据持久化到存储上, 这部分代码不需要进行加锁操作, 因为在上一段同步代码中已经将双buffer调换了位置, 不会有线程向用于刷新数据的缓冲区中写入数据, 所以调用flush()操作并不需要加锁。
■ 重置isSyncRunning标志位, 并且通知等待的线程, 这部分代码需要进行synchronized加锁操作。
/**
* 当一个线程要将它的操作同步到editlog文件中时, logSync()方法会使用
* ThreadLocal变量myTransactionId获取该线程需要同步的transactionId, 然后对比
* 这个transactionId和已经同步到editlog文件中的transactionId。 如果当前线程的
* transactionId大于editlog文件中的transactionId, 则表明editlog文件中记录的数据不
* 是最新的, 同时如果当前没有别的线程执行同步操作, 则开始同步操作将输出流
* 缓存中的数据写入editlog文件中。 需要注意的是, 由于editlog输出流使用了双
* buffer的结构, 所以在进行sync操作的同时, 并不影响editlog输出流的使用
*
* ■ 判断当前操作是否已经同步到了editlog文件中, 如果还没有同步, 则将editlog的
* 双buffer调换位置, 为同步操作做准备, 同时将isSyncRunning标志位设置为
* true, 这部分代码需要进行synchronized加锁操作。
*
* ■ 调用logStream.flush()方法将缓存的数据持久化到存储上, 这部分代码不需要进行
* 加锁操作, 因为在上一段同步代码中已经将双buffer调换了位置, 不会有线程向
* 用于刷新数据的缓冲区中写入数据, 所以调用flush()操作并不需要加锁。
*
* ■ 重置isSyncRunning标志位, 并且通知等待的线程, 这部分代码需要进行
* synchronized加锁操作。
*
*
*
* @param mytxid
*/
protected void logSync(long mytxid) {
long syncStart = 0;
boolean sync = false;
long editsBatchedInSync = 0;
try {
EditLogOutputStream logStream = null;
synchronized (this) {
try {
//第一部分, 头部代码 打印统计信息
printStatistics(false);
// 当前txid大于editlog中已经同步的txid,
// 并且有线程正在同步, 则等待.
// if somebody is already syncing, then wait
while (mytxid > synctxid && isSyncRunning) {
try {
wait(1000);
} catch (InterruptedException ie) {
}
}
//
// 如果txid小于editlog中已经同步的txid, 则表明当前操作已经被同步到存储上, 不需要再次同步
//
// If this transaction was already flushed, then nothing to do
//
if (mytxid <= synctxid) {
return;
}
// 开始同步操作, 将isSyncRunning标志位设置为true
// now, this thread will do the sync. track if other edits were
// included in the sync - ie. batched. if this is the only edit
// synced then the batched count is 0
editsBatchedInSync = txid - synctxid - 1;
syncStart = txid;
isSyncRunning = true;
sync = true;
// swap buffers
try {
if (journalSet.isEmpty()) {
throw new IOException("No journals available to flush");
}
//通过调用setReadyToFlush()方法将两个缓冲区互换, 为同步做准备
editLogStream.setReadyToFlush();
} catch (IOException e) {
final String msg =
"Could not sync enough journals to persistent storage " +
"due to " + e.getMessage() + ". " +
"Unsynced transactions: " + (txid - synctxid);
LOG.error(msg, new Exception());
synchronized(journalSetLock) {
IOUtils.cleanupWithLogger(LOG, journalSet);
}
terminate(1, msg);
}
} finally {
// 防止其他log edit 写入阻塞, 引起的RuntimeException
// Prevent RuntimeException from blocking other log edit write
doneWithAutoSyncScheduling();
}
//editLogStream may become null,
//so store a local variable for flush.
logStream = editLogStream;
}
// 第二部分, 调用flush()方法, 将缓存中的数据同步到editlog文件中
// do the sync
long start = monotonicNow();
try {
if (logStream != null) {
logStream.flush();
}
} catch (IOException ex) {
synchronized (this) {
final String msg =
"Could not sync enough journals to persistent storage. "
+ "Unsynced transactions: " + (txid - synctxid);
LOG.error(msg, new Exception());
synchronized(journalSetLock) {
IOUtils.cleanupWithLogger(LOG, journalSet);
}
terminate(1, msg);
}
}
long elapsed = monotonicNow() - start;
if (metrics != null) { // Metrics non-null only when used inside name node
metrics.addSync(elapsed);
metrics.incrTransactionsBatchedInSync(editsBatchedInSync);
numTransactionsBatchedInSync.addAndGet(editsBatchedInSync);
}
} finally {
// Prevent RuntimeException from blocking other log edit sync
//第三部分, 恢复标志位
synchronized (this) {
if (sync) {
// 已同步txid赋值为开始sync操作的txid
synctxid = syncStart;
for (JournalManager jm : journalSet.getJournalManagers()) {
/**
* {@link FileJournalManager#lastReadableTxId} is only meaningful
* for file-based journals. Therefore the interface is not added to
* other types of {@link JournalManager}.
*/
if (jm instanceof FileJournalManager) {
((FileJournalManager)jm).setLastReadableTxId(syncStart);
}
}
isSyncRunning = false;
}
this.notifyAll();
}
}
}
由于logEdit()方法中输出日志记录和调用logSync()刷新缓冲区数据到磁盘这两个操作是独立加锁的, 同时EditLogOutputStream提供了两个缓冲区可以同时进行日志记录和刷新缓冲区操作, 它们都使用FSEditLog对象作为锁对象, 所以logEdit()方法中使用synchronized关键字同步的日志记录操作和logSync()方法中使用synchronized关键字同步的刷新缓冲区数据到磁盘的操作是可以并发同步进行的。 这种设计大大地提高了多个线程记录editlog操作的并发性, 且通过transactionId机制保证了editlog日志记录的正确性.
感谢 :
Hadoop 2.X HDFS源码剖析-徐鹏
深度剖析Hadoop HDFS -林意群