【叙述】Java的IO流的缓冲流的原理(前面简单阐述,后面带源码剖析)
Hello,大家好,我是尘封已久的恨意。感谢老铁们能点进来一看。
这个文章,我就说下缓冲流,输出和输入和缓冲区的一些常识。
我们先来看个图:
(图我自己绘制的,凑合着看吧)
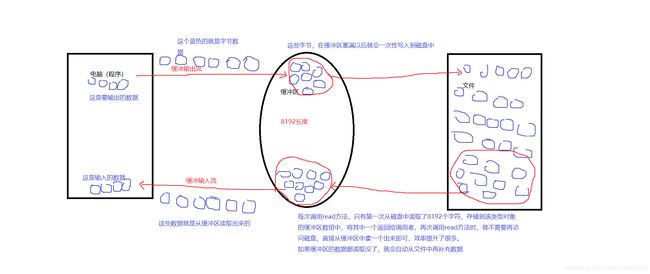
为了提高数据读写的速度,Java API提供了带缓冲功能的流类,在使用这些流类时,会创建一个内部缓冲区数组,缺省使用8192个字节(8Kb)的缓冲区。
缓冲流和普通的流区别就在于多了一个缓冲区。
不管是读取数据还是输出数据都要经过缓冲区。
普通的数据流每次读写都要访问磁盘,但是磁盘的速度很慢,所以如果你频繁访问消耗的时间就比较大。缓冲流可以解决这个问题。
使用BufferedOutputStream输出数据的时候,先写到缓冲区中,直到缓冲区写满, BufferedOutputStream才会把缓冲区中的数据一次性写到文件里。使用方法 flush()可以强制将缓冲区的内容全部写入输出流(这样一来和磁盘打交道的次数减少了,效率也就高了。)
使用BufferedIntputStream输入数据的时候,,BufferedInputStream会一次性从 文件中读取8192个(8Kb),存在缓冲区中,再这之后的读取都是直接从缓冲区里读取数据,直到缓冲区里的数据读取没了,才重新从文件中 读取下一个8192个字节数组。(因为读取访问的是数组,访问速度比磁盘快好几倍,所以效率高)
来看一波代码:
public class Main {
public static void main(String[] args)throws Exception {
//字节缓冲输出流
BufferedOutputStream bfoutput=new BufferedOutputStream(new FileOutputStream(new File("d:"+File.separator+"demo"+File.separator+"mldn.txt")));
String str="尘封已久的恨意";
byte[] bytes=str.getBytes();//把字符串转成byte[]数组
bfoutput.write(bytes);//这里就直接一次性全部输出数组
bfoutput.close();
}
}
这种是一次性把数据输入到缓冲区,然后调用close()方法关闭流的时候,会刷新一次缓冲区,把数据写入磁盘。
如果这样使用缓冲流(单次写入) 效率会比普通流效率还低。因为缓冲流会先把数据放缓冲区,然后再放到磁盘里,而普通的流是直接把数据写入磁盘里。
而且还有一个点要注意就是,你必须要调用flush()方法或者close()方法刷新缓冲区,这样数据才能写入到磁盘里,不然数据都留在缓冲区里。
但是如果代码这样写:
public class Main {
public static void main(String[] args)throws Exception {
//字节缓冲输出流
BufferedOutputStream bfoutput=new BufferedOutputStream(new FileOutputStream(new File("d:"+File.separator+"demo"+File.separator+"mldn.txt")));
String str="尘封已久的恨意666";
byte[] bytes=str.getBytes();//把字符串转成byte[]数组
for(int x=0;x<bytes.length;x++){
bfoutput.write(bytes[x]);
}
bfoutput.close();//关闭流,关闭之前会刷新缓冲区,不然数据都在缓冲区,没法写入磁盘
}
}
这个和刚才的唯一区别就是,这次使用了循环输出,输出的次数频繁了。
这样缓冲区的优势就出来了。
比单次写入的话,缓冲流的效率比普通流低。
但是比循环写入的话,缓冲流的效率比普通流高。
普通的数据流每次读写都要访问磁盘,但磁盘的速度很慢,频繁访问磁盘消耗的时间就比较长。缓冲流是先在缓冲区(缓冲数组)里存数据,存满了,再写入磁盘。访问的次数要比普通流要少,消耗的时间也就少,所以效率高。
还有一个就是Question1:写入数据时,如果写入的数据长度大于缓冲区的长度,那么缓冲流会怎么处理这种情况???
Question2:写入数据时,写入数据的长度超过了缓冲区的剩余长度,那么缓冲流会怎么处理这种情况??
这两个疑问,也是我写这篇帖子的动力,因为除了这个,上面讲的那些东西纯粹算是科普,毫无难度可言。
/**
* Writes {@code len} bytes from the specified byte array
* starting at offset {@code off} to this buffered output stream.
*
* Ordinarily this method stores bytes from the given array into this
* stream's buffer, flushing the buffer to the underlying output stream as
* needed. If the requested length is at least as large as this stream's
* buffer, however, then this method will flush the buffer and write the
* bytes directly to the underlying output stream. Thus redundant
* {@code BufferedOutputStream}s will not copy data unnecessarily.
*
* @param b the data.
* @param off the start offset in the data.
* @param len the number of bytes to write.
* @throws IOException if an I/O error occurs.
*/
@Override
public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) {
/* If the request length exceeds the size of the output buffer,
flush the output buffer and then write the data directly.
In this way buffered streams will cascade harmlessly. */
flushBuffer();
out.write(b, off, len);
return;
}
if (len > buf.length - count) {
flushBuffer();
}
System.arraycopy(b, off, buf, count, len);
count += len;
}
以上就是源码了。
if (len >= buf.length) ,如果你写入的数据长度超过缓冲区的长度,那么就会刷新缓冲区,然后直接把数据写入磁盘,就不用缓冲区了。
刷新缓冲区的原因也很好理解:可能之前写入的数据还再缓冲区里面,所以先把缓冲区刷新,缓冲区中的数据写入到磁盘。然后再把这次超过缓冲区长度的数据写入。这样才能完整的拼接数据。
if (len > buf.length - count) len是你要写入的字节数,buf.length是缓存数组的长度,count是缓冲区中的有效字节数。
如果,你写入的数据长度超过缓冲区中剩余空间的长度。
那么就会刷新当前的缓冲区,即把缓冲区的数据写入到磁盘中。
然后再进行数据写入(把新的数据写入缓冲区)
以下,我给出机翻对比。大家细品吧。
/* If the request length exceeds the size of the output buffer, flush the output buffer and then write the data directly. In this way buffered streams will cascade harmlessly. */
如果请求长度超过输出缓冲区的大小,请刷新输出缓冲区,然后直接写入数据。这样,缓冲流将无害地级联。
从指定的字节数组写入{@code len}个字节
从偏移量{@code off}开始到这个缓冲的输出流。
通常,此方法将给定数组中的字节存储到
流的缓冲区,将缓冲区刷新为基础输出流
需要。如果请求的长度至少与此流的长度一样大
但是,此方法将刷新缓冲区并写入
直接指向基础输出流的字节。因此是多余的
{@code BufferedOutputStream}s不会不必要地复制数据。
@参数b数据。
@参数关闭数据中的起始偏移量。
@param len要写入的字节数。
@如果发生I/O错误,则引发IOException。
这里我用的字节缓冲流做的演示,字符缓冲流也同理,只不过它是操作的字符。
OK,就到这里结束了。