爬虫打卡2之定位工具xpath、bs4、re学习总结
xpath
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。在XPath中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML文档是被作为节点树来对待的。
XPath和CSS选择符十分相像!但XPath有更强大的地方,比如它可以定位到body元素下具体位置上的p或可以选择前N个p:
body/p[position()=4] //这个XPath表达式将选取body子元素中第4个p元素,注意这里从1开始计数
body/p[position()❤️] //将选取body子元素中前两个p元素。
xpath常用语法:
nodeName 选取名称为nodeName的节点
/ 从根节点选取
// 选择元素后代元素,必须在后面跟上nodeName
. 选取当前节点
… 选取当前节点的父节点
@ 选取属性节点(@是attribute的缩写)
谓语为xpath提供更详尽的信息,谓语被嵌在方括号中。下面是一些带有谓语的XPath表达式:
/root/child[3] {选取root元素的第三个child子元素,注意,这和数组下标不一样,从1开始计数
//child[@attr] {选取所有具有属性attr的child元素
//child[@attr=“val”]/desc {选取所有属性attr的值为val的child元素的子元素desc
//child[desc] {选取所有的有desc子元素的child
//child[position()>3] {position()是XPath中的一个函数,表示节点的位置
//child[@attr>12] {XPath表达式还可以进行数值比较,该表达式将选取attr属性值大于12的child元素
//child[last()] {last()函数返回节点列表最后的位置,该表达式将选取最后一个child元素
XPath 通配符可用来选取未知的 XML 元素。
- ,和CSS中的选择符一样,这将匹配任何元素节点
@* ,匹配任何属性节点
node() ,匹配任何类型的节点
/root/* {选取根元素下面的所有子元素
/root/node() {选取根元素下面的所有节点,包括文本节点
//* {选取文档中所有元素
//child[@] {选取所有具有属性的child元素
//@ {选取所有的属性节点
使用lxml解析
导入库:from lxml import etree
lxml将html文本转成xml对象
tree = etree.HTML(html)
用户名称:tree.xpath(’//div[@class=“auth”]/a/text()’)
回复内容:tree.xpath(’//td[@class=“postbody”]’) 因为回复内容中有换行等标签,所以需要用string()来获取数据。
Xpath中text(),string(),data()的区别如下:
text()仅仅返回所指元素的文本内容。
string()函数会得到所指元素的所有节点文本内容,这些文本会被拼接成一个字符串。
data()大多数时候,data()函数和string()函数通用,而且不建议经常使用data()函数,该函数可能会影响XPath的性能。
爬取丁香园用户名和回复内容

bs
Beautiful Soup库的理解: Beautiful Soup库是解析、遍历、维护“标签树”的功能库,对应一个HTML/XML文档的全部内容
BeautifulSoup类的基本元素:
Tag 标签,最基本的信息组织单元,分别用<>和标明开头和结尾;
Name 标签的名字,
…
的名字是’p’,格式:.name;Attributes 标签的属性,字典形式组织,格式:.attrs;
NavigableString 标签内非属性字符串,<>…中字符串,格式:.string;
Comment 标签内字符串的注释部分,一种特殊的Comment类型;
基于bs4库的HTML内容遍历方法
HTML基本格式:<>…构成了所属关系,形成了标签的树形结构
标签树的下行遍历
.contents 子节点的列表,将所有儿子节点存入列表
.children 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
.descendants 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
标签树的上行遍
.parent 节点的父亲标签
.parents 节点先辈标签的迭代类型,用于循环遍历先辈节点
标签树的平行遍历
.next_sibling 返回按照HTML文本顺序的下一个平行节点标签
.previous_sibling 返回按照HTML文本顺序的上一个平行节点标签
.next_siblings 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签
.previous_siblings 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签
常见的bs方法

用bs做一个中国大学排名的爬取,虽然这个排名没有什么意义还很功利
http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html
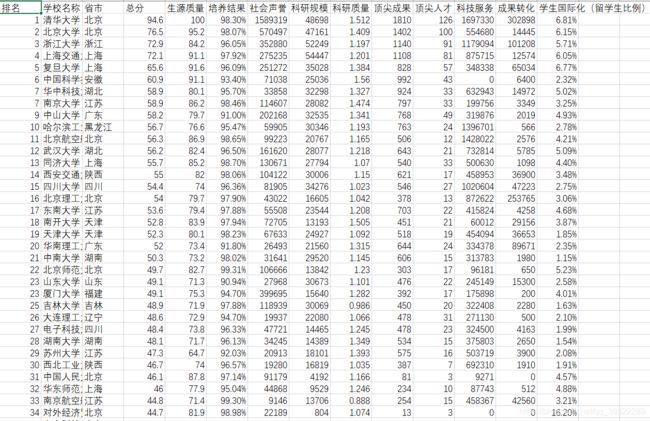

数据处理方面花了些时间才弄好,这方面还要加强
同时bs可以与正则和css相互配合
比如soup.find_all(xxx = re.compile(‘xxxx’,re.S))以及soup.select(‘xxxx’)
re正则表达式
正则表达式在爬虫中通俗来讲是用一种语言在html中定位你所需要的内容

re很基础,各种资料都有,常用.*?非贪婪进行字符匹配,写一个爬取淘宝商品价格的例子。
登录淘宝,搜书包,第一页url为
https://s.taobao.com/search?q=书包&js=1&stats_click=search_radio_all%25
第二页为https://s.taobao.com/searchq=%E4%B9%A6%E5%8C%85&js=1&stats_click=search_radio_all%25&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=44
第三页为
https://s.taobao.com/searchq=%E4%B9%A6%E5%8C%85&js=1&stats_click=search_radio_all%25&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=88
第四页为
https://s.taobao.com/searchq=%E4%B9%A6%E5%8C%85&js=1&stats_click=search_radio_all%25&bcoffset=-3&ntoffset=-3&p4ppushleft=1%2C48&s=132
很简单有三个参数在变
循环翻页时改为https://s.taobao.com/searchq=%E4%B9%A6%E5%8C%85&js=1&stats_click=search_radio_all%25&bcoffset=(9-3i)&ntoffset=(9-3i)&p4ppushleft=1%2C48&s=44(i-1)
对于登录页面的爬虫,可以在获取登录的cookie之后把cookie放入请求头,cookie在哪呢,搜索js可以看到与url类似的一个链接有cookie,同时确定请求方式为get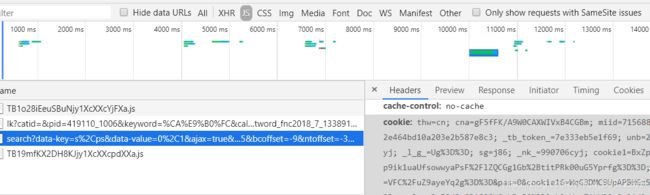
初步获取html,很多

接着用re进行商品定位

然后可以写
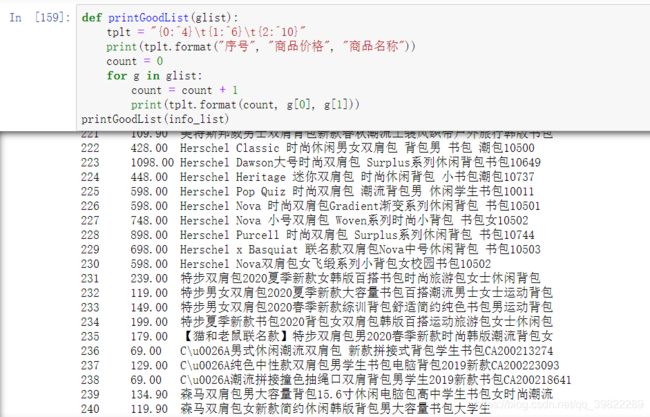
price_list = re.findall(r’(.?)’, html)
name_list = re.findall(r’,“raw_title”:"(.?)",“pic_url”:’, html)
同时可以发现网页的html和get的不一样,需要按照get的html进行定位
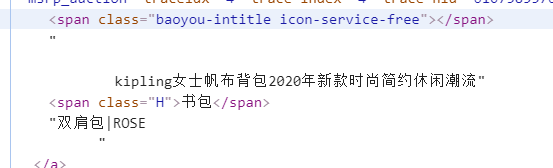
先进行局部测试,爬取一页发现ok
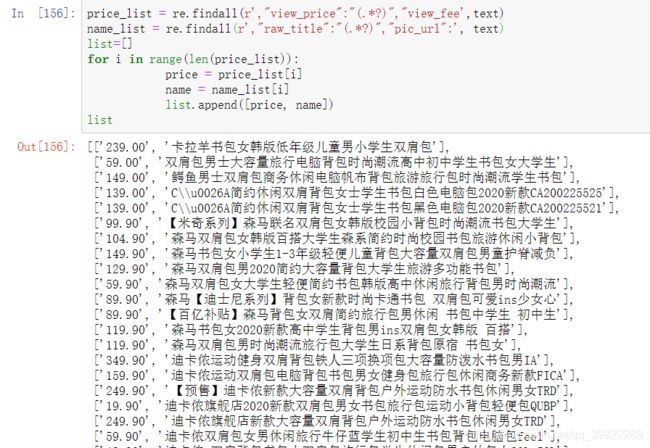
然后设置解析与循环
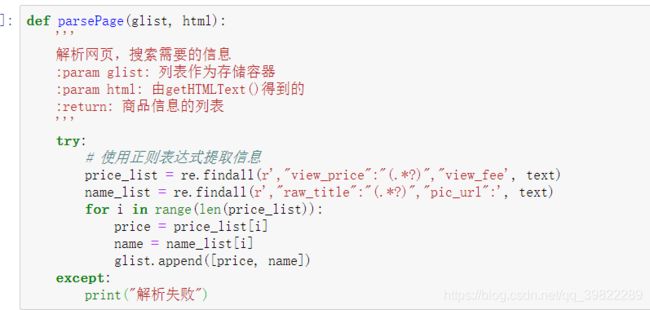

根据不同页的url规律设置url,最后写打印函数,其中循环设置了一个伪指针count,进行商品序号的表示。