传统机器学习模型解说01:一元线性回归模型
引入
年薪和工作年限有关吗?
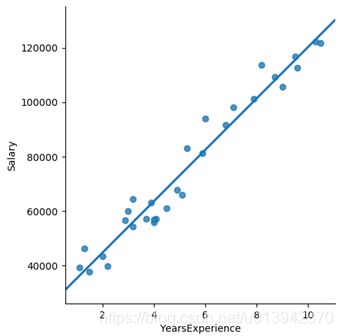
可见两个变量之间存在明显的线性关系,而根据常识,工作年限是因,年薪是果。
那么,是否存在某个模型,如图中的一次函数直线,来描述两个变量之间的关系呢?
原理简述与背景介绍
一元线性回归模型也被称为简单线性回归模型,指模型中只有一个自变量和一个因变量。
其原理可以简述为:用一个(二维中的)直线(以及高维中的超平面)去最大程度地拟合样本特征和样本输出标记(即数据点)之间的关系。
一元线性回归思想简单,但背后有强大的数学理论支持,具有很好的可解释性,是许多强大的非线性模型的基础。
算法推导
基本设定
给定数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\} T={(x1,y1),(x2,y2),⋯,(xN,yN)}其中 x i ∈ X ⊆ R x_{i} \in \mathcal{X} \subseteq \mathbb{R} xi∈X⊆R, y i ∈ Y ⊆ R y_{i} \in \mathcal{Y} \subseteq \mathbb{R} yi∈Y⊆R, i = 1 , 2 , ⋯ , N i=1,2, \cdots, N i=1,2,⋯,N
假设决策函数为 f ( x ) = a x + b f(x)=ax+b f(x)=ax+b其中 a , b a,b a,b称为回归系数。
可知第 i i i个元素 x i x_{i} xi的预测值为 y i ^ = f ( x i ) = a x i + b {\hat{y_{i}}}=f(x_{i})=ax_{i}+b yi^=f(xi)=axi+b使用平方损失函数作为损失函数: L ( y , f ( x ) ) = ( y − f ( x ) ) 2 L\left(y,f(x)\right)=\left(y-f(x)\right)^2 L(y,f(x))=(y−f(x))2求以下经验风险最小化 J ( a , b ) = ∑ i = 1 N ( y i − y i ^ ) 2 = ∑ i = 1 N ( y i − a x i − b ) 2 J(a, b)=\sum_{i=1}^{N}(y_{i}-{\hat{y_{i}}})^{2}=\sum_{i=1}^{N}\left(y_{i}-ax_{i}-b\right)^{2} J(a,b)=i=1∑N(yi−yi^)2=i=1∑N(yi−axi−b)2即目标是求取使目标函数 J J J最小的回归系数 a , b a,b a,b.
参数求解
1. 求解 b b b
对 b b b求偏导并另令其等于 0 0 0
∂ J ( a , b ) ∂ b = ∑ i = 1 N 2 ( y i − a x i − b ) ( − 1 ) = 0 \frac{\partial J(a, b)}{\partial b}=\sum_{i=1}^{N} 2\left(y_{i}-a x_{i}-b\right)(-1)=0 ∂b∂J(a,b)=i=1∑N2(yi−axi−b)(−1)=0去除系数,即得 ∑ i = 1 N ( y i − a x i − b ) = 0 \sum_{i=1}^{N}\left(y_{i}-a x_{i}-b\right)=0 i=1∑N(yi−axi−b)=0展开得到 ∑ i = 1 N y i − a ∑ i = 1 N x i − ∑ i = 1 N b = 0 \sum_{i=1}^{N} y_{i}-a \sum_{i=1}^{N} x_{i}-\sum_{i=1}^{N} b=0 i=1∑Nyi−ai=1∑Nxi−i=1∑Nb=0由于 b b b是常数,最后一项可以改写为 ∑ i = 1 N y i − a ∑ i = 1 N x i − N b = 0 \sum_{i=1}^{N} y_{i}-a \sum_{i=1}^{N} x_{i}-Nb=0 i=1∑Nyi−ai=1∑Nxi−Nb=0因此移项得到 N b = ∑ i = 1 N y i − a ∑ i = 1 N x i Nb= \sum_{i=1}^{N} y_{i}-a \sum_{i=1}^{N} x_{i} Nb=i=1∑Nyi−ai=1∑Nxi注意到左边有所有 y y y值的和与所有 x x x的值,因此如果左右两边都除以 N N N值,将得到 b = y ‾ − a x ‾ b=\overline{y}-a \overline{x} b=y−ax其中 y ‾ , x ‾ \overline{y}, \overline{x} y,x分别是所有 y , x y,x y,x的均值。
2. 求解 a a a
对 a a a求偏导并令其等于 0 0 0
∂ J ( a , b ) ∂ a = ∑ i = 1 N 2 ( y i − a x i − b ) ( − x i ) = 0 \frac{\partial J(a, b)}{\partial a}=\sum_{i=1}^{N} 2\left(y_{i}-a x_{i}-b\right)\left(-x_i\right)=0 ∂a∂J(a,b)=i=1∑N2(yi−axi−b)(−xi)=0去除系数得到 ∑ i = 1 N ( y i − a x i − b ) x i = 0 \sum_{i=1}^{N} \left(y_{i}-a x_{i}-b\right)x_i=0 i=1∑N(yi−axi−b)xi=0将 b = y ‾ − a x ‾ b=\overline{y}-a \overline{x} b=y−ax代入得到 ∑ i = 1 N ( y i − a x i − y ‾ + a x ‾ ) x i = 0 \sum_{i=1}^{N}\left(y_{i}-a x_{i}-\overline{y}+a \overline{x}\right) x_i=0 i=1∑N(yi−axi−y+ax)xi=0将 x i x_i xi乘入得到 ∑ i = 1 N [ y i x i − a ( x i ) 2 − y ‾ x i + a x ‾ x i ] = 0 \sum_{i=1}^{N}\left[y_{i}x_i-a(x_{i})^2-\overline{y}x_i+a \overline{x}x_i\right] =0 i=1∑N[yixi−a(xi)2−yxi+axxi]=0可以看到系数 a a a在第二项和第四项,拆开并提取 a a a得到 ∑ i = 1 N ( y i x i − y ‾ x i ) − a ∑ i = 1 N [ ( x i ) 2 − x ‾ x i ] = 0 \sum_{i=1}^{N}(y_ix_i-\overline{y}x_i)-a\sum_{i=1}^{N}[(x_i)^2-\overline{x}x_i]=0 i=1∑N(yixi−yxi)−ai=1∑N[(xi)2−xxi]=0移项并作除法得到 a = ∑ i = 1 N ( x i y i − x i y ‾ ) ∑ i = 1 N [ ( x i ) 2 − x i x ‾ ] a=\frac{\sum_{i=1}^{N}\left(x_iy_i-x_i \overline{y}\right)}{\sum_{i=1}^{N}\left[(x_i)^2-x_i \overline{x}\right]} a=∑i=1N[(xi)2−xix]∑i=1N(xiyi−xiy)计算结束。
3. 优化
考虑到 y ‾ , x ‾ \overline{y}, \overline{x} y,x都是定值,有以下等式:
∑ i = 1 N x i y ‾ = y ‾ ∑ i = 1 N x i = N y ‾ x ‾ = x ‾ ∑ i = 1 N y i = ∑ i = 1 N x ‾ y i = ∑ i = 1 N x ‾ ∗ y ‾ \sum_{i=1}^{N} x_i \overline{y}=\overline{y} \sum_{i=1}^{N} x_i=N \overline{y} \overline{x}=\overline{x} \sum_{i=1}^{N} y_i=\sum_{i=1}^{N} \overline{x} y_i=\sum_{i=1}^{N} \overline{x} *\overline{y} i=1∑Nxiy=yi=1∑Nxi=Nyx=xi=1∑Nyi=i=1∑Nxyi=i=1∑Nx∗y
同理有 ∑ i = 1 N x i x ‾ = x ‾ ∑ i = 1 N x i = x ‾ N x ‾ = N ( x ‾ ) 2 = ∑ i = 1 N ( x ‾ ) 2 \sum_{i=1}^{N}x_i\overline{x} =\overline{x} \sum_{i=1}^{N}x_i=\overline{x}N\overline{x}=N({\overline{x}})^2=\sum_{i=1}^{N}({\overline{x}})^2 i=1∑Nxix=xi=1∑Nxi=xNx=N(x)2=i=1∑N(x)2因此对于 a a a有 a = ∑ i = 1 N ( x i y i − x i y ‾ ) ∑ i = 1 N [ ( x i ) 2 − x i x ‾ ] = ∑ i = 1 N ( x i y i − x i y ‾ − x ‾ y i + x ‾ ∗ y ‾ ) ∑ i = 1 N [ ( x i ) 2 − x ‾ x i − x ‾ x i + ( x ‾ ) 2 ] = ∑ i = 1 N ( x i − x ‾ ) ( y i − y ‾ ) ∑ i = 1 N ( x i − x ‾ ) 2 a=\frac{\sum_{i=1}^{N}\left(x_iy_i-x_i \overline{y}\right)}{\sum_{i=1}^{N}\left[(x_i)^2-x_i \overline{x}\right]}=\frac{\sum_{i=1}^{N}\left(x_iy_i-x_i \overline{y}-\overline{x} y_i+\overline{x}* \overline{y}\right)}{\sum_{i=1}^{N}\left[\left(x_i\right)^{2}-\overline{x} x_i-\overline{x} x_i+(\overline{x})^{2}\right]}=\frac{\sum_{i=1}^{N}\left(x_i-\overline{x}\right)\left(y_i-\overline{y}\right)}{\sum_{i=1}^{N}\left(x_i-\overline{x}\right)^{2}} a=∑i=1N[(xi)2−xix]∑i=1N(xiyi−xiy)=∑i=1N[(xi)2−xxi−xxi+(x)2]∑i=1N(xiyi−xiy−xyi+x∗y)=∑i=1N(xi−x)2∑i=1N(xi−x)(yi−y)
可见这样可以极大地提升计算效率。
4. 答案
以下为答案:
{ a = ∑ i = 1 N ( x i − x ‾ ) ( y i − y ‾ ) ∑ i = 1 N ( x i − x ‾ ) 2 b = y ‾ − a x ‾ \left\{\begin{array}{l}{a=\frac{\sum_{i=1}^{N}\left(x_i-\overline{x}\right)\left(y_i-\overline{y}\right)}{\sum_{i=1}^{N}\left(x_i-\overline{x}\right)^{2}}}\\{b=\overline{y}-a \overline{x}}\end{array}\right. {a=∑i=1N(xi−x)2∑i=1N(xi−x)(yi−y)b=y−ax
代码实现
数据介绍
使用seaborn自带的tips数据集
import pandas as pd
import seaborn as sns
tips=sns.load_dataset('tips')
tips.head()

我们选取前两列,total_bill总消费作为自变量x,tip小费作为因变量y,画出两者的关系图如下:
sns.jointplot(x='total_bill',y='tip',data=tips,kind='reg')
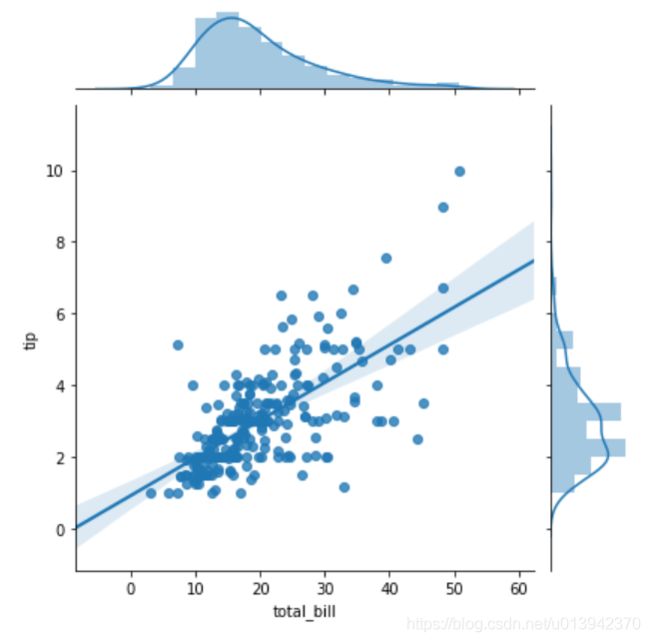
可见两者存在线性关系,且可以用一条直线大致拟合。
自制代码实现
def simpleRegression(x,y):
xMean=x.mean()
yMean=y.mean()
a=((x-xMean)*(y-yMean)).sum()/(x-xMean).pow(2).sum()
b=yMean-xMean*a
return a,b
simpleRegression(tips['total_bill'],tips['tip'])
![]()
前者是 a a a的值,后者是 b b b的值。
sklearn代码实现
from sklearn import linear_model
lr=linear_model.LinearRegression()
x=tips[['total_bill']]#注意这里必须要加两个方括号,xy都是
y=tips[['tip']]
res=lr.fit(x,y)
res.coef_[0][0],res.intercept_[0]
![]()
可见两组答案数字在小数点后10位都是一样的,可以说是基本一致。
参考资料
- https://blog.csdn.net/thfyshz/article/details/83589836
- https://zhuanlan.zhihu.com/p/76580358
- 《从零开始学Python数据分析与挖掘》,第7章