Selenium爬虫实践:深圳短租数据
项目目的:
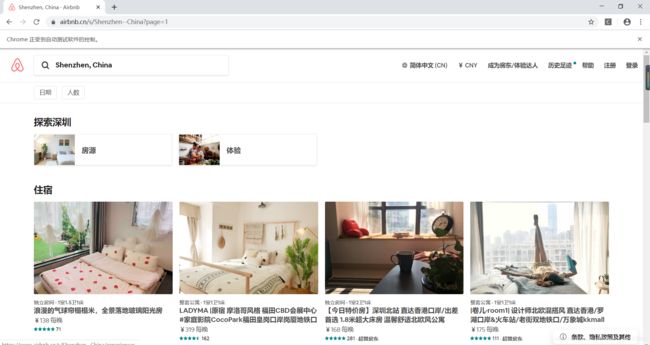
获取Airbnb深圳前20页的短租数据:
房源的名称、价格、评价数量、房屋类型、床数量和房客数量
网页地址:
https://www.airbnb.cn/s/Shenzhen–China?page=1
代码如下:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.airbnb.cn/s/Shenzhen--China?page=1')
rent_list = driver.find_elements_by_css_selector("div._z5ixr97")
i = 1
for eachhouse in rent_list:
# 获取名称
name = eachhouse.find_element_by_css_selector("div._qrfr9x5")
name = name.text
# 获取价格
price = eachhouse.find_element_by_css_selector("div._59f9ic")
price = price.text[2:]
# 获取房屋信息
detail = eachhouse.find_element_by_css_selector("div._1etkxf1")
detail = detail.text
# 获取评价数
comment = eachhouse.find_element_by_css_selector("span._69pvqtq")
comment = comment.text
# 最后打印信息
print('(' + str(i) + ')' + name + price + '\n'
+ detail + '\n' + comment)
i=i+1
爬取的数据:

当然,如果想获取更多页数的房屋信息,注意URL的offset值就可以了,用一个循环来自动地爬取