Docker部署Hadoop环境+Hive
文章目录
- 一、环境和应用准备
- 二、构建images
- 三、搭建Hadoop集群
- 四、配置Hadoop集群
- 五、安装Hive
一、环境和应用准备
环境:Mac OS
安装包版本:
jdk-8u181-linux-x64.tar.gz
hadoop-2.7.3.tar.gz
apache-hive-3.1.1-bin.tar.gz
mysql-connector-java-5.1.48.tar.gz
已安装:Docker
二、构建images
使用Docker来启动三台Centos7虚拟机,三台机器上安装Hadoop和Java。
1. 获取centos镜像
docker pull centos

查看镜像列表的命令
docker images

2. 安装SSH
以centos7镜像为基础,构建一个带有SSH功能的centos
mkdir ~/centos7-ssh
cd centos7-ssh
vi Dockerfile
内容:
FROM centos
MAINTAINER JanZ
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
RUN yum install -y openssh-clients
RUN echo "root:pass" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
- 大意:选择一个已有的os镜像作为基础;安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no;安装openssh-clients;添加测试用户root,密码pass,并且将此用户添加到sudoers里;ssh-keygen 这两句比较特殊,在centos6上必须要有,否则创建出来的容器sshd不能登录;启动sshd服务并且暴露22端口。
构建新镜像,命名为 centos7-ssh
docker build -t="centos7-ssh" .
执行完成后,可以在镜像列表中看到
docker images

3. 构建Hadoop镜像
基于centos7-ssh镜像构建有JDK和Hadoop的镜像
mkdir ~/hadoop
cd ~/hadoop
注:在hadoop文件夹中(即 Dockerfile 所在目录)提前准备好 jdk-8u181-linux-x64.tar.gz 与 hadoop-2.7.3.tar.gz
vi Dockerfile
内容:
FROM centos7-ssh
ADD jdk-8u181-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_181 /usr/local/jdk1.8
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATH
ADD hadoop-2.7.3.tar.gz /usr/local
RUN mv /usr/local/hadoop-2.7.3 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
RUN yum install -y which sudo
基于 centos7-ssh 这个镜像,把 Java 和 Hadoop 的环境都配置好了
构建新镜像,命名为 hadoop
docker build -t="hadoop" .
三、搭建Hadoop集群
搭建有三个节点的hadoop集群,一主两从
主节点:hadoop0 ip:172.18.0.2
从节点1:hadoop1 ip:172.18.0.3
从节点2:hadoop2 ip:172.18.0.4
但是由于docker容器重新启动之后ip会发生变化,所以需要我们给docker设置固定ip。
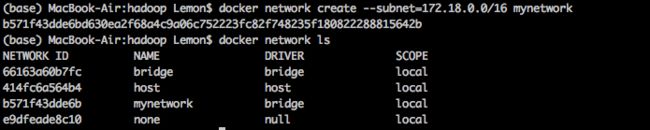
1. 创建自定义网络(设置固定IP)
查看网络列表
docker network ls

创建自定义网络 mynetwork,并且指定网段:172.18.0.0/16
docker network create --subnet=172.18.0.0/16 mynetwork
2. 创建docker容器
启动三个容器,分别为hadoop0, hadoop1, hadoop2
docker run --name hadoop0 --hostname hadoop0 --net mynetwork --ip 172.18.0.2 -d -P -p 50070:50070 -p 8088:8088 hadoop
docker run --name hadoop1 --hostname hadoop1 --net mynetwork --ip 172.18.0.3 -d -P hadoop
docker run --name hadoop2 --hostname hadoop2 --net mynetwork --ip 172.18.0.4 -d -P hadoop
查看容器列表
docker ps

四、配置Hadoop集群
新开启三个终端,分别进入容器 hadoop0, hadoop1, hadoop2
docker exec -it hadoop0 /bin/bash
docker exec -it hadoop1 /bin/bash
docker exec -it hadoop2 /bin/bash
1. 设置主机名与ip的映射,修改三台容器
# hadoop0中执行
vi /etc/hosts
添加以下配置:
172.18.0.2 hadoop0
172.18.0.3 hadoop1
172.18.0.4 hadoop2
2. 设置ssh免密码登录
# hadoop0中执行
cd ~
mkdir .ssh
cd .ssh
ssh-keygen -t rsa # (一直按回车即可)
ssh-copy-id -i localhost # 中途输入:yes,密码:pass,下同
ssh-copy-id -i hadoop0
ssh-copy-id -i hadoop1
ssh-copy-id -i hadoop2
# hadoop1中执行
cd ~
cd .ssh
ssh-keygen -t rsa # (一直按回车即可)
ssh-copy-id -i localhost
ssh-copy-id -i hadoop1
# hadoop2中执行
cd ~
cd .ssh
ssh-keygen -t rsa # (一直按回车即可)
ssh-copy-id -i localhost
ssh-copy-id -i hadoop2
3. 在hadoop0上修改hadoop的配置文件
cd /usr/local/hadoop/etc/hadoop
修改目录下的配置文件core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
(1) hadoop-env.sh
vi hadoop-env.sh # 以下vi命令省略
修改内容:
export JAVA_HOME=/usr/local/jdk1.8
(2) core-site.xml
添加:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
(3) hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(4) yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
(5) mapred-site.xml
# 修改文件名
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(6) 指定nodemanager的地址,修改文件yarn-site.xml
<property>
<description>The hostname of the RM.</description>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0</value>
</property>
(7) 修改配置文件slaves
cd /usr/local/hadoop/etc/hadoop
vi slaves
删除原来的所有内容,添加以下内容:
hadoop1
hadoop2
(8) 在hadoop0中执行命令
scp -rq /usr/local/hadoop hadoop1:/usr/local
scp -rq /usr/local/hadoop hadoop2:/usr/local
4. 格式化
cd /usr/local/hadoop
bin/hdfs namenode -format
# 注意:在执行的时候如果报错,是因为缺少which命令,执行下面命令安装
# yum install -y which
- 注:格式化操作不能重复执行。如果一定要重复格式化,带参数-force即可。
5. 启动伪分布hadoop
sbin/start-all.sh
6. 检查集群是否正常
(1) 查看进程
检查进程的命令:
jps
hadoop0 进程:
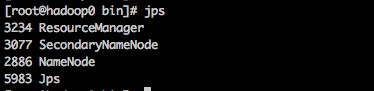
hadoop1 进程:
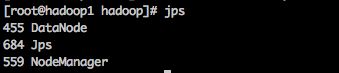
hadoop2 进程:
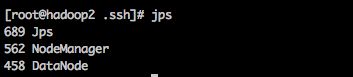
(2) 使用程序验证集群服务
创建一个文件
# hadoop0中执行,下同
cd /usr/local/hadoop
vi a.txt
内容:
hello you
hello me
上传a.txt到hdfs上
hdfs dfs -put a.txt /
执行wordcount程序
cd /usr/local/hadoop/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /a.txt /out
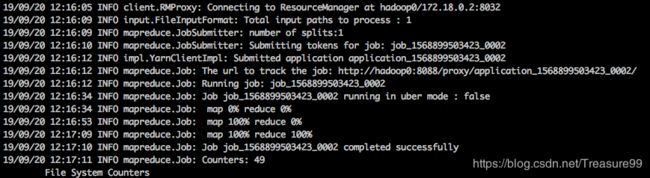
查看程序执行结果
hdfs dfs -text /out/part-r-00000

这样就说明集群正常了。
(3) 通过浏览器访问集群的服务
由于在启动hadoop0这个容器的时候把50070和8088映射到宿主机的对应端口上了,所以在这可以直接通过宿主机访问容器中hadoop集群的服务。
http://127.0.0.1:50070
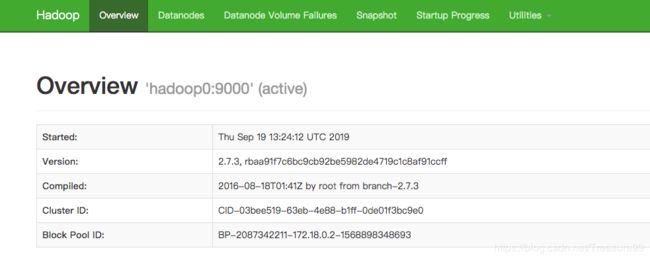
http://127.0.0.1:8088
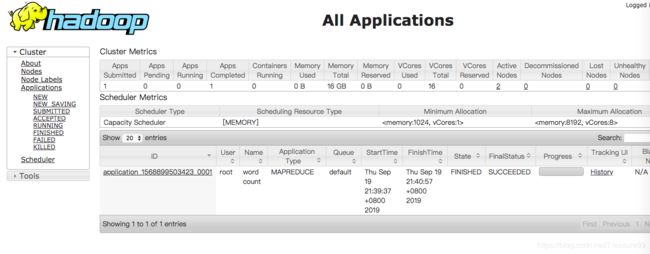
6. 停止伪分布hadoop的命令
cd /usr/local/hadoop
sbin/stop-all.sh
五、安装Hive
1. 本地下载hive,使用下面的命令传到hadoop0上
# 本地 bash中执行
docker cp ~/hadoop/apache-hive-3.1.1-bin.tar.gz 933358c86309:/usr/local/
# 933358c86309为 hadoop0的 Container Id,下同
2. 解压到指定目录
# hadoop0中执行
cd /usr/local
tar -zxvf apache-hive-3.1.1-bin.tar.gz
mv apache-hive-3.1.1-bin /hive
cd /hive
3. 配置 /etc/profile
# hadoop0中执行
vi /etc/profile
添加:
export HIVE_HOME=/usr/local/hive
export PATH=$HIVE_HOME/bin:$PATH
source /etc/profile
4. 安装并启用MySQL
使用docker容器来进行安装(本地bash中执行)
获取镜像
docker pull mysql/mysql-server:5.7
新建mysql容器
docker run --name mysql -p 5706:3306 -e MYSQL_ROOT_PASSWORD=pass --net mynetwork --ip 172.18.0.5 -d mysql/mysql-server:5.7 --character-set-server=utf8mb4 --collation-server=utf8mb4_general_ci
新建一个终端,进入mysql容器,运行mysql
docker exec -it mysql /bin/bash
mysql -uroot -p
创建metastore数据库
create database metastore;
在mysql中授权(以便本地 Navicat 可以连通)
grant all privileges on *.* to root@"%" identified by "pass" with grant option;
其他设定(非必需)
set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
show variables like "%time_zone%";
set global time_zone = '+8:00';
flush privileges;
本地Navicat设置连接
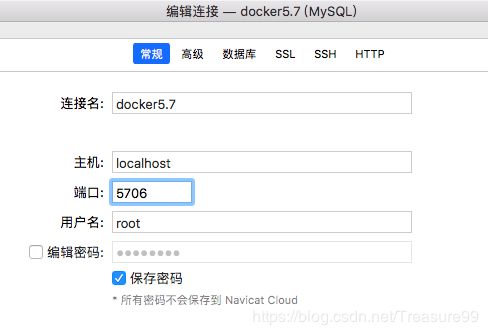
5. 下载jdbc connector
下载Connector/J 5.1.48
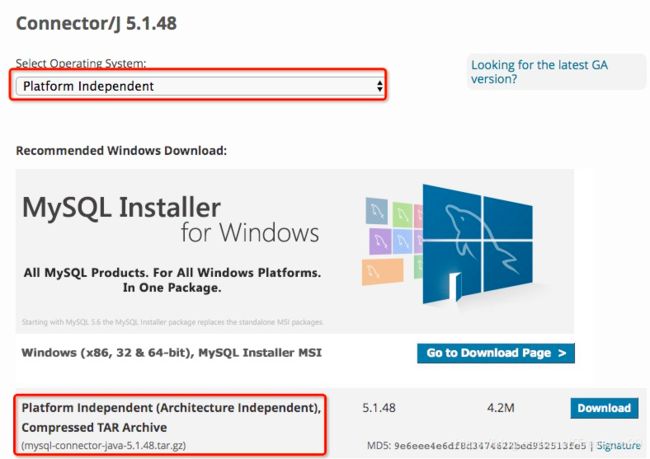
下载至本地hadoop文件夹中并解压,把其中的mysql-connector-java-5.1.41-bin.jar文件拷贝到$HIVE_HOME/lib目录
# 本地bash中执行
cd ~/hadoop/mysql-connector-java-5.1.48
docker cp mysql-connector-java-5.1.48-bin.jar 933358c86309:/hive/lib
6. 修改hive配置文件
# hadoop0中执行,下同
cd /hive/conf
(1) 复制初始化文件并重改名
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
(2) 修改hive-env.sh
vi hive-env.sh
export JAVA_HOME=/usr/local/jdk1.8 # Java路径
export HADOOP_HOME=/usr/local/hadoop # Hadoop安装路径
export HIVE_HOME=/hive # Hive安装路径
export HIVE_CONF_DIR=/hive/conf # Hive配置文件路径
(3) 在 hdfs 中创建下面的目录 ,并且授权
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /user/hive/tmp
hdfs dfs -mkdir -p /user/hive/log
hdfs dfs -chmod -R 777 /user/hive/warehouse
hdfs dfs -chmod -R 777 /user/hive/tmp
hdfs dfs -chmod -R 777 /user/hive/log
(4) 修改hive-site.xml (定位后修改覆盖)
<property>
<name>hive.exec.scratchdir</name>
<value>/user/hive/tmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/user/hive/log</value>
</property>
# 配置 MySQL 数据库连接信息
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.18.0.5:3306/metastore?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>111111</value>
</property>
(5) 创建tmp文件
mkdir /hive/tmp
在hive-site.xml中修改:
把{system:java.io.tmpdir} 改成 /home/hadoop/hive/tmp/
把 {system:user.name} 改成 {user.name}
(8) 初始化hive
cd /hive/bin
./schematool -dbType mysql -initSchema
(9) 启动hive
cd /hive/bin
./hive

- 注:如果启动中出现报错,参考:安装Hive过程中,出现Exception in thread “main” java.lang.IllegalArgumentException: java.net.URISyntaxException
- hive运行语句时报错,参考:hive启动报错 java.net.URISyntaxException: Relative path in absolute URI
本文参考了官方文档及很多博客,并在前辈攻略的基础上进行了更新与调整。
重点参考来源:
- Gitbook: Docker — 从入门到实践
- Docker+Hadoop+Hive+Presto 使用Docker部署Hadoop环境和Presto
- Docker部署Hadoop集群
- docker docs
- Linux vi/vim的使用
- Hadoop命令手册