几篇关于 Redis集群方面的知识学习
https://www.cnblogs.com/kaleidoscope/p/9630316.html
Redis集群方案总结
Redis回顾
Redis支持的数据结构
- 字符串(String)
- 哈希(Hash)
- 列表(List)
- 集合(Set)
- 有序集合(Sorted Set)位数组
- 支持针对score作范围查询
- HyperLogLog
- 做基数统计的算法
Redis支持的操作
- 基本操作发布/订阅
- Set get add push pop…
- Pipeline操作
- 事务
- 事务支持不完整。不提供回滚命令。
Redis适用场景
- KV存储
- 缓存(TTL LRU...)消息中间件
- LRU是redis达到maxmemory之后,可选的key删除策略。
- 分布式锁
Redis集群实现方式
实现基础——分区
- 分区是分割数据到多个Redis实例的处理过程,因此每个实例只保存key的一个子集。
- 通过利用多台计算机内存的和值,允许我们构造更大的数据库。
- 通过多核和多台计算机,允许我们扩展计算能力;通过多台计算机和网络适配器,允许我们扩展网络带宽。
集群的几种实现方式
- 客户端分片
- 基于代理的分片
- 路由查询
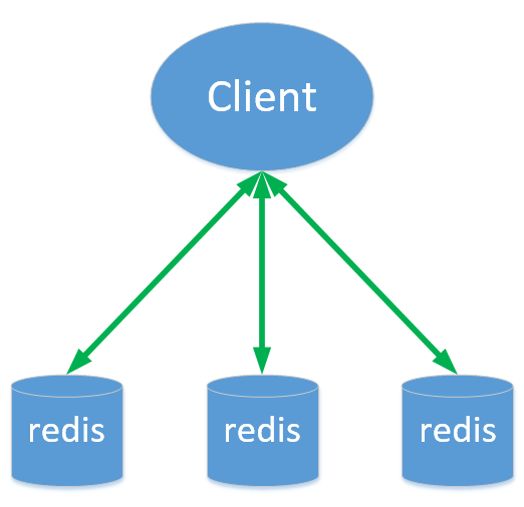
客户端分片
- 由客户端决定key写入或者读取的节点。
- 包括jedis在内的一些客户端,实现了客户端分片机制。
原理如下所示:
特性
- 优点
- 简单,性能高。
- 缺点
- 业务逻辑与数据存储逻辑耦合
- 可运维性差
- 多业务各自使用redis,集群资源难以管理
- 不支持动态增删节点
基于代理的分片
- 客户端发送请求到一个代理,代理解析客户端的数据,将请求转发至正确的节点,然后将结果回复给客户端。
- 开源方案
- Twemproxy
- codis
基本原理如下所示:
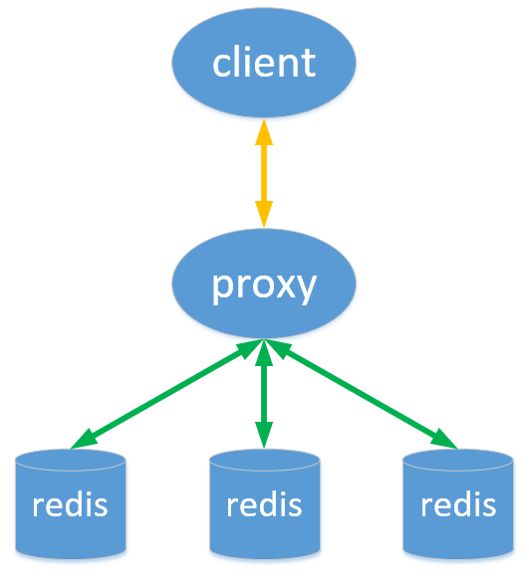
特性
- 透明接入Proxy 的逻辑和存储的逻辑是隔离的。
- 业务程序不用关心后端Redis实例,切换成本低。
- 代理层多了一次转发,性能有所损耗。
路由查询
- 将请求发送到任意节点,接收到请求的节点会将查询请求发送到正确的节点上执行。
- 开源方案
- Redis-cluster
基本原理如下所示:

集群的挑战
- 涉及多个key的操作通常是不被支持的。涉及多个key的redis事务不能使用。
- 举例来说,当两个set映射到不同的redis实例上时,你就不能对这两个set执行交集操作。
- 不能保证集群内的数据均衡。
- 分区的粒度是key,如果某个key的值是巨大的set、list,无法进行拆分。
- 增加或删除容量也比较复杂。
- redis集群需要支持在运行时增加、删除节点的透明数据平衡的能力。
Redis集群各种方案原理
Twemproxy
- Proxy-based
- twtter开源,C语言编写,单线程。
- 支持 Redis 或 Memcached 作为后端存储。
Twemproxy高可用部署架构

Twemproxy特性
- 支持失败节点自动删除
- 与redis的长连接,连接复用,连接数可配置
- 自动分片到后端多个redis实例上支持redis pipelining 操作
- 多种hash算法:能够使用不同的分片策略和散列函数
- 支持一致性hash,但是使用DHT之后,从集群中摘除节点时,不会进行rehash操作
- 可以设置后端实例的权重
- 支持状态监控
- 支持select切换数据库
redis的管道(Pipelining)操作是一种异步的访问模式,一次发送多个指令,不同步等待其返回结果。这样可以取得非常好的执行效率。调用方法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
@Test
publicvoidtestPipelined() {
Jedis jedis =newJedis("localhost");
Pipeline pipeline = jedis.pipelined();
longstart = System.currentTimeMillis();
for(inti =0; i <100000; i++) {
pipeline.set("p"+ i,"p"+ i);
}
List
longend = System.currentTimeMillis();
System.out.println("Pipelined SET: "+ ((end - start)/1000.0) +" seconds");
jedis.disconnect();
}
Twemproxy不足
- 性能低:代理层损耗 && 本身效率低下
- Redis功能支持不完善
- 不支持针对多个值的操作,比如取sets的子交并补等(MGET 和 DEL 除外)
- 不支持Redis的事务操作
- 出错提示还不够完善
- 集群功能不够完善
- 仅作为代理层使用
- 本身不提供动态扩容,透明数据迁移等功能
- 失去维护
- 最近一次提交在一年之前。Twitter内部已经不再使用。
Redis Cluster
- Redis官网推出,可线性扩展到1000个节点
- 无中心架构
- 一致性哈希思想
- 客户端直连redis服务,免去了proxy代理的损耗
Redis Cluster模型
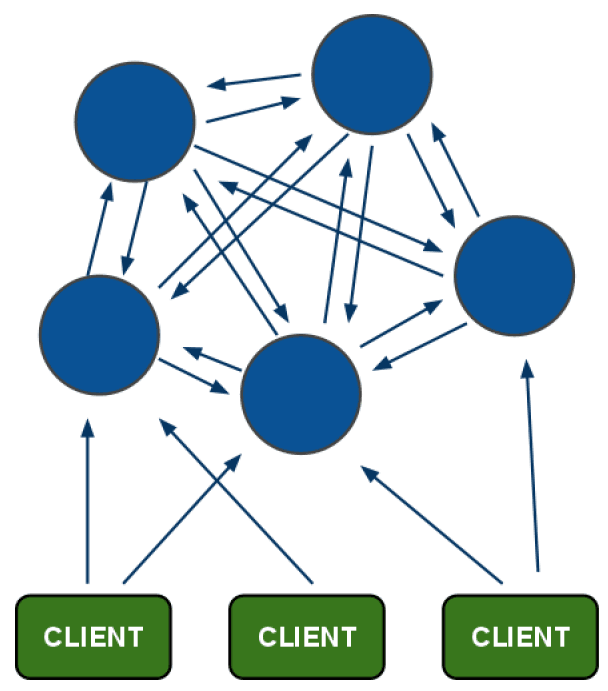
Redis-cluster原理
- Hash slot。集群内的每个redis实例监听两个tcp端口,6379(默认)用于服务客户端查询,16379(默认服务端口 + 10000)用于集群内部通信。
- key的空间被分到16384个hash slot里;
- 计算key属于哪个slot,CRC16(key) & 16384。
- 节点间状态同步:gossip协议,最终一致性。节点间通信使用轻量的二进制协议,减少带宽占用。
Gossip 算法又被称为反熵(Anti-Entropy),熵是物理学上的一个概念,代表杂乱无章,而反熵就是在杂乱无章中寻求一致,这充分说明了 Gossip 的特点:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的,当然这也是疫情传播的特点。
简单的描述下这个协议,首先要传播谣言就要有种子节点。种子节点每秒都会随机向其他节点发送自己所拥有的节点列表,以及需要传播的消息。任何新加入的节点,就在这种传播方式下很快地被全网所知道。这个协议的神奇就在于它从设计开始就没想到信息一定要传递给所有的节点,但是随着时间的增长,在最终的某一时刻,全网会得到相同的信息。当然这个时刻可能仅仅存在于理论,永远不可达。
Redis-cluster请求路由方式
- Redis-Cluster借助客户端实现了混合形式的路由查询
查询路由并非直接从一个redis节点到另外一个redis,而是借助客户端转发到正确的节点。根据客户端的实现方式,可以分为以下两种:包括Jedis在内的许多redis client,已经实现了对Redis Cluster的支持。- dummy client
- smart client
查询路由的流程如下所示:
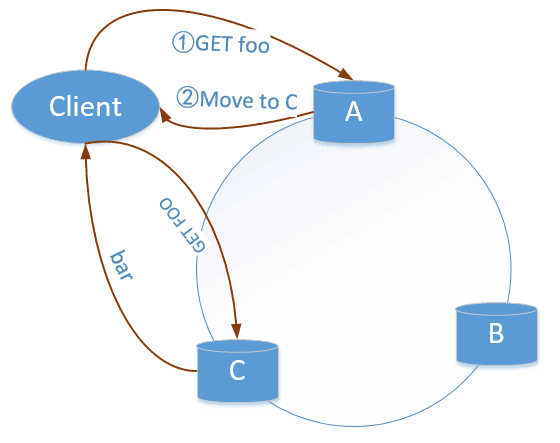
Redis cluster采用这种架构的考虑:
- 减少redis实现的复杂度
- 降低客户端等待的时间。Smart client可以在客户端缓存 slot 与 redis节点的映射关系,当接收到 MOVED 响应时,会修改缓存中的映射关系。请求时会直接发送到正确的节点上,减少一次交互。
Redis Cluster特性
- 高性能
- 支持动态扩容,对业务透明
- 具备Sentinel的监控和自动Failover能力
Redis Cluster不足
- 官方未提供图形管理工具,运维比较复杂要求客户端必须支持cluster协议
- 比如数据迁移,纯手动操作,先分配slot,再将slot中对应的key迁移至新的节点。
- Redis命令支持不完整
- 对于批量的指令,如mget支持不完整;不支持事务;不支持数据库切换,只能使用0号数据库……
- 集群管理与数据存储耦合
- 比如如果集群管理有bug,需要升级整个redis。
Codis
- 豌豆荚开源的proxy-based的redis集群方案
- 支持透明的扩/缩容
- 运维友好同类产品中最全面的redis命令支持
- GUI监控界面和管理工具
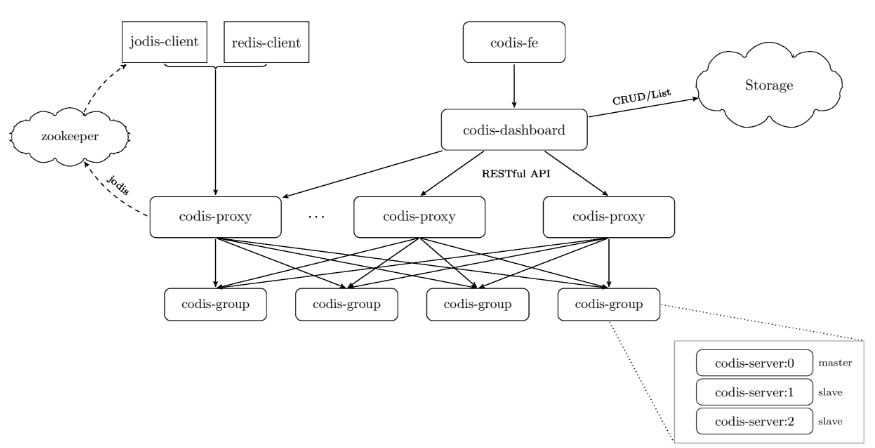
Codis部署拓扑
Codis数据存储
- 数据根据key分布到1024个slot内
- Key的slotid计算方法 crc32(key) % 1024
- 每个 codis-server 负责一部分数据
- 比如后端有3组codis-server,每个server负责的slot范围可以这样设置:
- group0 0-300
- group1 301-600
- group2 601-1023
Codis模块简介
- Codis Server
- 基于 redis-2.8.21 分支开发。增加了额外的数据结构,以支持 slot 有关的操作以及数据迁移指令。
- Codis Proxy
- 客户端连接的 Redis 代理服务, 实现了 Redis 协议。
- 对于同一个业务集群而言,可以同时部署多个 codis-proxy 实例
- 不同 codis-proxy 之间由 codis-dashboard 保证状态同步。
- Codis Dashboard
- 集群管理工具,支持 codis-proxy、codis-server 的添加、删除,以及据迁移等操作。
- 所有对集群的修改都必须通过 codis-dashboard 完成。
- Codis Admin
- 集群管理的命令行工具。
- 可用于控制 codis-proxy、codis-dashboard 状态以及访问外部存储。
- Codis FE
- 集群管理界面。
- Codis HA
- 为集群提供高可用。
- 依赖 codis-dashboard 实例,自动抓取集群各个组件的状态;
- 会根据当前集群状态自动生成主从切换策略,并在需要时通过 codis-dashboard 完成主从切换。
- Storage
- 为集群状态提供外部存储。
- 目前仅提供了 Zookeeper 和 Etcd 两种实现,但是提供了抽象的 interface 可自行扩展。
Codis主从切换
- Codis-HA:自动切换主从的工具。
- 通过RESTful API从 codis-dashboard 中拉取集群状态
- 默认以 5s 为周期
- 该工具会在检测到 master 挂掉的时候主动应用主从切换策略,向codis-dashboard发送主从切换命令。
- 对自动主从切换的支持比较弱
- 主从切换的限制较多,必须在系统其他组件状态健康,且距离上次主从同步数据在一定时间间隔内才可以执行。
- 多slave场景,提升其中的一个slave为master,其他的slave仍然会从旧的master同步数据,需要管理员手动操作。
Codis数据迁移流程
- 前提:Codis单条数据迁移是原子操作
- 单条数据迁移过程:
- 随机选取指定 slot 中的一个
- 将这个
- 传输成功后,把本地的这个
- 随机选取指定 slot 中的一个
迁移过程如下所示:
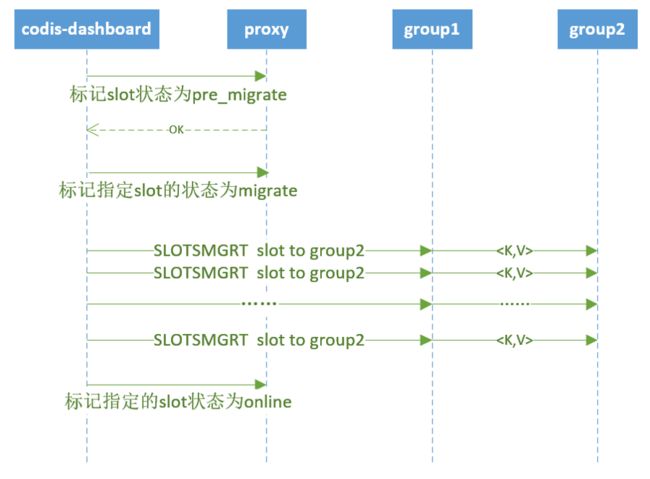
迁移过程中,Codis-dashboard与proxy通过zk通信,路由表信息全部存放在zk,保证所有proxy的视图一致。
Codis如何保证数据迁移过程的正确及透明?
- codis-config 在实际修改slot状态之前,会确保所有的 proxy 收到这个迁移请求。
- 迁移过程中, 如果客户端请求 slot 的 key 数据,proxy 会将请求转发到group2上。
- proxy会先在group1上强行执行一次 MIGRATE key 将这个键值提前迁移过来,
- 然后再到group2上正常读取
Codis VS Redis
| 对比参数 | Codis | Redis-cluster |
|---|---|---|
| Redis版本 | 基于2.8分支开发 | >= 3.0 |
| 部署 | 较复杂。 | 简单 |
| 运维 | Dashboard,运维方便。 | 运维人员手动通过命令操作。 |
| 监控 | 可在Dashboard里监控当前redis-server节点情况,较为便捷。 | 不提供监控功能。 |
| 组织架构 | Proxy-Based, 类中心化架构,集群管理层与存储层解耦。 | P2P模型,gossip协议负责集群内部通信。去中心化 |
| 伸缩性 | 支持动态伸缩。 | 支持动态伸缩 |
| 主节点失效处理 | 自动选主。 | 自动选主。 |
| 数据迁移 | 简单。支持透明迁移。 | 需要运维人员手动操作。支持透明迁移。 |
| 升级 | 基于redis 2.8分支开发,后续升级不能保证;Redis-server必须是此版本的codis,无法使用新版本redis的增强特性。 | Redis官方推出,后续升级可保证。 |
| 可靠性 | 经过线上服务验证,可靠性较高。 | 新推出,坑会比较多。遇到bug之后需要等官网升级。 |
- 理论上,redis-cluster的性能更高,单次请求的延时低。另外,经过实测,两种架构后端单台redis-server的条件下,TPS基本没有差别。
- Codis的高可用依赖jodis,或者使用LVS进行高可用部署。
我们公司选择Codis的原因
- Redis-cluster没有成熟的应用案例
- Codis支持的命令更加丰富
- 迁移至redis cluster需要修改现有实现;而迁移到codis没这么麻烦,只要使用的redis命令在codis支持的范围之内,只要修改一下配置即可接入。
- Codis提供的运维工具更加友好
Codis简单压测
单台Codis Server压测结果

三台Codis-Server的集群压测结果
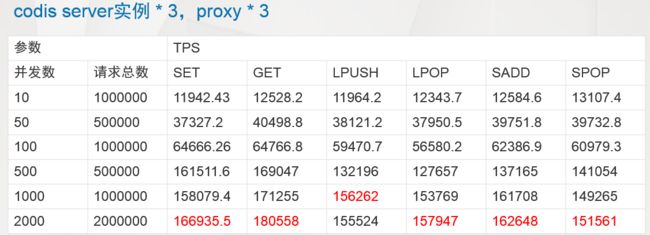
压测结论
- 针对codis集群压测过程中,后端codis server平均CPU占用约为70%~80%。
- 单台codis的TPS在6w~7w左右,集群的TPS在17w左右,可以达到近乎线性扩展的能力
- 测试期间后台codis-server的负载没有跑满,仍然具有继续压测的潜力。
- 测试期间proxy机器负载低,可以支撑更多后端codis server实例。
使用codis注意事项
- 不支持的命令
- 不支持的命令列表
- 防止key冲突
- 建议现有业务接入codis时,加入项目前缀以作区分。
- 使用spring data redis操作codis时,只能使用RedisTemplate系列接口,Cache系列接口不可用
- Cache系列的接口使用了redis的事务指令,事务在Codis以及Redis Cluster中均未提供支持。
- 避免key value巨大的数据
- 吞吐量提升不明显
- 可能造成各codis实例资源占用不均衡
https://www.cnblogs.com/me115/p/9043420.html
内容目录:
- 类 codis 架构
- 基于官方 redis cluster 的方案
redis 集群方案主要有两类,一是使用类 codis 的架构,按组划分,实例之间互相独立;
另一套是基于官方的 redis cluster 的方案;下面分别聊聊这两种方案;
类 codis 架构
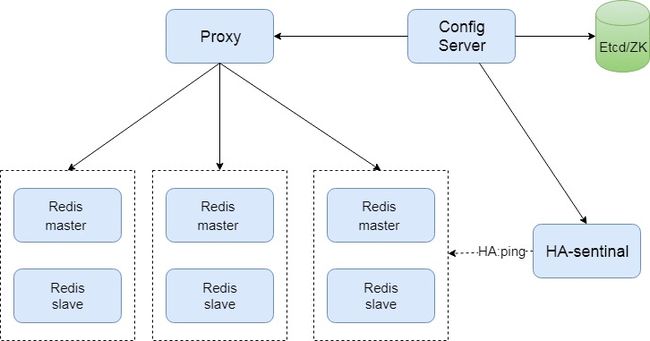
这套架构的特点:
- 分片算法:基于 slot hash桶;
- 分片实例之间相互独立,每组 一个master 实例和多个slave;
- 路由信息存放到第三方存储组件,如 zookeeper 或etcd
- 旁路组件探活
使用这套方案的公司:
阿里云: ApsaraCache, RedisLabs、京东、百度等
codis
slots 方案:划分了 1024个slot, slots 信息在 proxy层感知; redis 进程中维护本实例上的所有key的一个slot map;
迁移过程中的读写冲突处理:
最小迁移单位为key;
访问逻辑都是先访问 src 节点,再根据结果判断是否需要进一步访问 target 节点;
- 访问的 key 还未被迁移:读写请求访问 src 节点,处理后访问:
- 访问的 key 正在迁移:读请求访问 src 节点后直接返回;写请求无法处理,返回 retry
- 访问的 key 已被迁移(或不存在):读写请求访问 src 节点,收到 moved 回复,继续访问 target 节点处理
阿里云
AparaCache 的单机版已开源(开源版本中不包含slot等实现),集群方案细节未知;ApsaraCache
百度 BDRP 2.0
主要组件:
proxy,基于twemproxy 改造,实现了动态路由表;
redis内核: 基于2.x 实现的slots 方案;
metaserver:基于redis实现,包含的功能:拓扑信息的存储 & 探活;
最多支持1000个节点;
slot 方案:
redis 内核中对db划分,做了16384个db; 每个请求到来,首先做db选择;
数据迁移实现:
数据迁移的时候,最小迁移单位是slot,迁移中整个slot 处于阻塞状态,只支持读请求,不支持写请求;
对比 官方 redis cluster/ codis 的按key粒度进行迁移的方案:按key迁移对用户请求更为友好,但迁移速度较慢;这个按slot进行迁移的方案速度更快;
京东
主要组件:
proxy: 自主实现,基于 golang 开发;
redis内核:基于 redis 2.8
configServer(cfs)组件:配置信息存放;
scala组件:用于触发部署、新建、扩容等请求;
mysql:最终所有的元信息及配置的存储;
sentinal(golang实现):哨兵,用于监控proxy和redis实例,redis实例失败后触发切换;
slot 方案实现:
在内存中维护了slots的map映射表;
数据迁移:
基于 slots 粒度进行迁移;
scala组件向dst实例发送命令告知会接受某个slot;
dst 向 src 发送命令请求迁移,src开启一个线程来做数据的dump,将这个slot的数据整块dump发送到dst(未加锁,只读操作)
写请求会开辟一块缓冲区,所有的写请求除了写原有数据区域,同时双写到缓冲区中。
当一个slot迁移完成后,把这个缓冲区的数据都传到dst,当缓冲区为空时,更改本分片slot规则,不再拥有该slot,后续再请求这个slot的key返回moved;
上层proxy会保存两份路由表,当该slot 请求目标实例得到 move 结果后,更新拓扑;
跨机房:跨机房使用主从部署结构;没有多活,异地机房作为slave;
基于官方 redis cluster 的方案

和上一套方案比,所有功能都集成在 redis cluster 中,路由分片、拓扑信息的存储、探活都在redis cluster中实现;各实例间通过 gossip 通信;这样的好处是简单,依赖的组件少,应对400个节点以内的场景没有问题(按单实例8w read qps来计算,能够支持 200 * 8 = 1600w 的读多写少的场景);但当需要支持更大的规模时,由于使用 gossip协议导致协议之间的通信消耗太大,redis cluster 不再合适;
使用这套方案的有:AWS, 百度贴吧
官方 redis cluster
数据迁移过程:
基于 key粒度的数据迁移;
迁移过程的读写冲突处理:
从A 迁移到 B;
- 访问的 key 所属slot 不在节点 A 上时,返回 MOVED 转向,client 再次请求B;
- 访问的 key 所属 slot 在节点 A 上,但 key 不在 A上, 返回 ASK 转向,client再次请求B;
- 访问的 key 所属slot 在A上,且key在 A上,直接处理;(同步迁移场景:该 key正在迁移,则阻塞)
AWS ElasticCache
ElasticCache 支持主从和集群版、支持读写分离;
集群版用的是开源的Redis Cluster,未做深度定制;
百度贴吧的ksarch-saas:
基于redis cluster + twemproxy 实现;后被 BDRP 吞并;
twemproxy 实现了 smart client 功能;使用 redis cluster后还加一层 proxy的好处:
- 对client友好,不需要client都升级为smart client;(否则,所有语言client 都需要支持一遍)
- 加一层proxy可以做更多平台策略;比如在proxy可做 大key、热key的监控、慢查询的请求监控、以及接入控制、请求过滤等;
即将发布的 redis 5.0 中有个 feature,作者计划给 redis cluster加一个proxy。
ksarch-saas 对 twemproxy的改造已开源:
https://github.com/ksarch-saas/r3proxy
https://www.cnblogs.com/xckk/p/6134655.html
Redis集群方案应该怎么做
方案1:Redis官方集群方案 Redis Cluster
Redis Cluster是一种服务器sharding分片技术。Redis Cluster集群如何搭建请参考我的另一篇博文:http://www.cnblogs.com/xckk/p/6144447.html
Redis3.0版本开始正式提供,解决了多Redis实例协同服务问题,时间较晚,目前能证明在大规模生产环境下成功的案例还不是很多,需要时间检验。
Redis Cluster中,Sharding采用slot(槽)的概念,一共分成16384个槽。对于每个进入Redis的键值对,根据key进行散列,分配到这16384个slot中的某一个中。使用的hash算法也比较简单,CRC16后16384取模。
Redis Cluster中的每个node负责分摊这16384个slot中的一部分,也就是说,每个slot都对应一个node负责处理。例如三台node组成的cluster,分配的slot分别是0-5460,5461-10922,10923-16383,

M: 434e5ee5cf198626e32d71a4aee27bc4058b4e45 127.0.0.1:7000 slots:0-5460 (5461 slots) master M: 048a0c9631c87e5ecc97a4ce5834d935f2f938b6 127.0.0.1:7001 slots:5461-10922 (5462 slots) master M: 04ae4184b2853afb8122d15b5b2efa471d4ca251 127.0.0.1:7002 slots:10923-16383 (5461 slots) master
添加或减少节点时?
当动态添加或减少node节点时,需要将16384个slot重新分配,因此槽中的键值也要迁移。这一过程,目前处于半自动状态,需要人工介入。
节点发生故障时
如果某个node发生故障,那它负责的slots也就失效,整个Redis Cluster将不能工作。因此官方推荐的方案是将node都配置成主从结构,即一个master主节点,挂n个slave从节点。
这非常类似Redis Sharding场景下服务器节点通过Sentinel(哨兵)监控架构主从结构,只是Redis Cluster本身提供了故障转移容错的能力。
通信端口
Redis Cluster的新节点识别能力、故障判断及故障转移能力是通过集群中的每个node和其它的nodes进行通信,这被称为集群总线(cluster bus)。
通信端口号一般是该node端口号加10000。如某node节点端口号是6379,那么它开放的通信端口是16379。nodes之间的通信采用特殊的二进制协议。
对客户端来说,整个cluster被看重是一个整体,客户端可以连接任意一个node进行操作,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node。
如下。在127.0.0.1上部署了三台Redis实例,组成Redis cluster,端口号分别是7000,7001,7002。在端口号为7000的Redis node上设置
[root@centos1 create-cluster]# redis-cli -c -p 7000 127.0.0.1:7000> set foo hello -> Redirected to slot [12182] located at 127.0.0.1:7002 OK 127.0.0.1:7000> get foo -> Redirected to slot [12182] located at 127.0.0.1:7002 "hello"
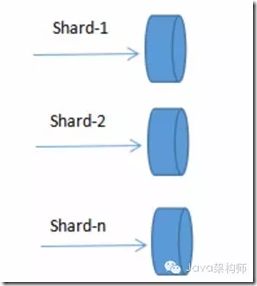
方案2:Redis Sharding集群
Redis Sharding是一种客户端Sharding分片技术。
Redis Sharding可以说是Redis Cluster出来之前,业界普遍使用的多Redis实例集群方法。主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。
这样,客户端就知道该向哪个Redis节点操作数据,需要说明的是,这是在客户端完成的。Sharding架构如图所示:
java redis客户端jedis,已支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool。Jedis的Redis Sharding实现具有如下特点:
1、采用一致性哈希算法(consistent hashing)
将key和节点name同时哈希,然后进行映射匹配,采用的算法是MURMUR_HASH。一致性哈希主要原因是当增加或减少节点时,不会产生由于重新匹配造成的rehashing。一致性哈希只影响相邻节点key分配,影响量小。更多一致性哈希算法介绍,可以参考:http://blog.csdn.net/cywosp/article/details/23397179/
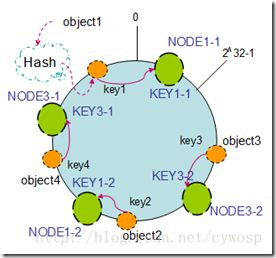
2、虚拟节点
ShardedJedis会对每个Redis节点,根据名字虚拟化出160个虚拟节点进行散列。用虚拟节点做映射匹配,可以在增加或减少Redis节点时,key在各Redis节点移动更分配更均匀,而不是只有相邻节点受影响。如图,Redis节点1虚拟化成NODE1-1和NODE1-2,散列中哈希环上。这样当object1、object2散列时,选取最近节点NODE1-1和NODE1-2,而NODE1-1和NODE1-2又是NODE节点的虚拟节点,即实际存储在NODE节点上。
增加虚拟节点,可以保证平衡性,即每台Redis机器,存储的数据都差不多,而不是一台机器存储的数据较多,其它的少。
3、ShardedJedis支持keyTagPattern模式
抽取key的一部分keyTag做sharding,这样通过合理命名key,可以将一组相关联的key放入同一Redis节点,避免跨节点访问。即客户端将相同规则的key值,指定存储在同一Redis节点上。
添加或减少节点时?
Redis Sharding采用客户端Sharding方式,服务端的Redis还是一个个相对独立的Redis实例节点。同时,我们也不需要增加额外的中间处理组件,这是一种非常轻量、灵活的Redis多实例集群方案。
当然,这种轻量灵活方式必然在集群其它能力方面做出妥协。比如扩容,当想要增加Redis节点时,尽管采用一致性哈希,那么不同的key分布到不同的Redis节点上。
当我们需要扩容时,增加机器到分片列表中。这时候客户端根据key算出来落到跟原来不同的机器上,这样如果要取某一个值,会出现取不到的情况。
对于这一种情况,一般的作法是取不到后,直接从后端数据库重新加载数据,但有些时候,击穿缓存层,直接访问数据库层,会对系统访问造成很大压力。
Redis作者给出了一个办法--presharding。
是一种在线扩容的方法,原理是将每一台物理机上,运行多个不同端口的Redis实例,假如三个物理机,每个物理机运行三个Redis实例,那么我们的分片列表中实际有9个Redis实例,当我们需要扩容时,增加一台物理机,步骤如下:
1、在新的物理机上运行Redis-server
2、该Redis-server从属于(slaveof)分片列表中的某一Redis-Server(假设叫RedisA)。
3、主从复制(Replication)完成后,将客户端分片列表中RedisA的IP和端口改为新物理机上Redis-Server的IP和端口。
4、停止RedisA
这样相当于将某一Redis-Server转移到了一台新机器上。但还是很依赖Redis本身的复制功能,如果主库快照数据文件过大,这个复制的过程也会很久,同时也会给主Redis带来压力,所以做这个拆分的过程最好选择业务访问低峰时段进行。
节点发生故障时
并不是只有增删Redis节点引起键值丢失问题,更大的障碍来自Redis节点突然宕机。
为不影响Redis性能,尽量不开启AOF和RDB文件保存功能,因此需架构Redis主备模式,主Redis宕机,备Redis留有备份,数据不会丢失。
Sharding演变成如下:
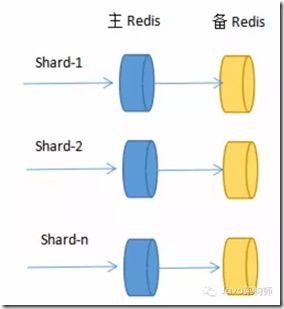
这样,我们的架构模式变成一个Redis节点切片包含一个主Redis和一个备Redis,主备共同组成一个Redis节点,通过自动故障转移,保证了节点的高可用性.
Redis Sentinel哨兵
提供了主备模式下Redis监控、故障转移等功能,达到系统的高可用性。
读写分离
高访问时量下,即使采用Sharding分片,一个单独节点还是承担了很大的访问压力,这时我们还需要进一步分解。
通常情况下,读常常是写的数倍,这时我们可以将读写分离,读提供更多的实例数。利用主从模式实现读写分离,主负责写,从负责只读,同时一主挂多个从。在Redis Sentinel监控下,还可以保障节点故障的自动监测。
方案3:利用代理中间件实现大规模Redis集群
上面分别介绍了基于客户端Sharding的Redis Sharding和基于服务端sharding的Redis Cluster。
客户端Sharding技术
优势:服务端的Redis实例彼此独立,相互无关联,非常容易线性扩展,系统灵活性很强。
不足:1、由于sharding处理放到客户端,规模扩大时给运维带来挑战。
2、服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整。
3、连接不能共享,当应用规模增大时,资源浪费制约优化。
服务端Sharding技术
优势:服务端Redis集群拓扑结构变化时,客户端不需要感知,客户端像使用单Redis服务器一样使用Redis Cluster,运维管理也比较方便。
不足:Redis Cluster正式版推出时间不长,系统稳定性、性能等需要时间检验,尤其中大规模使用场景。
能不能结合二者优势?既能使服务端各实例彼此独立,支持线性可伸缩,同时sharding又能集中处理,方便统一管理?
中间件sharding分片技术
twemproxy就是一种中间件sharding分片的技术,处于客户端和服务器的中间,将客户端发来的请求,进行一定的处理后(如sharding),再转发给后端真正的Redis服务器。
也就是说,客户端不直接访问Redis服务器,而是通过twemproxy代理中间件间接访问。
tweproxy中间件的内部处理是无状态的,起源于twitter,不仅支持redis,同时支持memcached。
使用了中间件,twemproxy可以通过共享与后端系统的连接,降低客户端直接连接后端服务器的连接数量。同时,它也提供sharding功能,支持后端服务器集群水平扩展。统一运维管理也带来了方便。
当然,由于使用了中间件,相比客户端直辖服务器方式,性能上肯定会有损耗,大约降低20%左右。
另一个知名度较高的实现是 Codis,由豌豆荚的团队开发。感兴趣的读者可以搜索相关资料。
总结:几种方案如何选择。
上面大致讲了三种集群方案,主要根据sharding在哪个环节进行区分
1、服务端实现分片
官方的 Redis Cluster 实现就是采用这种方式,在这种方案下,客户端请求到达错误节点后不会被错误节点代理执行,而是被错误节点重定向至正确的节点。
2、客户端实现分片
分区的逻辑在客户端实现,由客户端自己选择请求到哪个节点。方案可参考一致性哈希,基于 Memcached 的 cache 集群一般是这么做,而这种方案通常适用于用户对客户端的行为有完全控制能力的场景。
3、中间件实现分片
有名的例子是 Twitter 的 Twemproxy,Redis 作者对其评价较高。一篇较旧的博客如下:Twemproxy, a Redis proxy from Twitter
另一个知名度较高的实现是 Codis,由豌豆荚的团队开发,作者 @go routine 刘老师已经在前面的答案中推荐过了。
那么,如何选择呢?
显然在客户端做分片是自定义能力最高的。
优势在于,在不需要客户端服务端协作,以及没有中间层的条件下,每个请求的 roundtrip 时间是相对更小的,搭配良好的客户端分片策略,可以让整个集群获得很好的扩展性。
当然劣势也很明显,用户需要自己对付 Redis 节点宕机的情况,需要采用更复杂的策略来做 replica,以及需要保证每个客户端看到的集群“视图”是一致的。
中间件的方案对客户端实现的要求是最低的,客户端只要支持基本的 Redis 通信协议即可,至于扩容、多副本、主从切换等机制客户端都不必操心,因此这种方案也很适合用来做“缓存服务”。
官方推出的协作方案也完整地支持了分片和多副本,相对于各种 proxy,这种方案假设了客户端实现是可以与服务端“协作”的,事实上主流语言的 SDK 都已经支持了。
所以,对于大部分使用场景来说,官方方案和代理方案都够用了,其实没必要太纠结谁更胜一筹,每种方案都有很多靠谱的公司在用。
此文主要参考了以下文章:
https://www.zhihu.com/question/21419897
http://blog.csdn.net/freebird_lb/article/details/7778999