Python爬虫初体验之赶集网租房信息获取
初学Python,刚接触了BeautifulSoup模块,就拿爬取赶集网租房信息小试身手,以此彰显Python的威猛强大。
一、环境配置:
1、Python 3.6.1 (windows 10 64位系统)
2. Pycharm 编译器
二、相关模块的安装:
1、bs4 :可通过在shell中pip install bs4 进行安装。

2. urllib.parse: python自带
3. requests :python 自带
4. csv:Python 自带
5. html5lib:通过pip install html5lib进行安装
三、开始编代码:
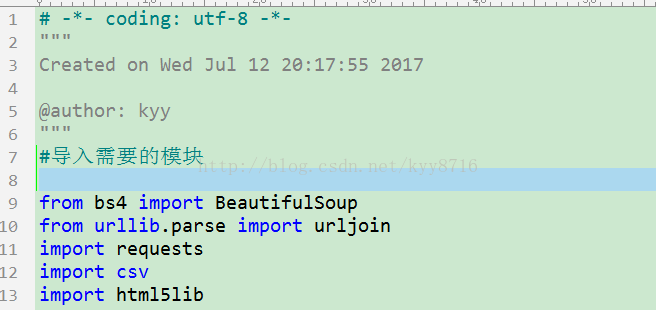
1、导入需要的模块
2. 指定要爬取的网页地址:
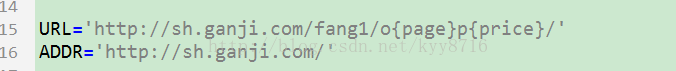
line 15:上海赶集网的网址(url).{page}和{price}为下文中需要用到的format方法内的参数。page为页数,price为租金价格区间。
3. 开始爬取前10页,价格区间为800-1500,即price为2的房源信息.

line19-line21:指定变量初始值
line22:在当前工作目录下新建一个ganji.csv文件,特别注意参数encoding='gb18030'指定汉字编码,(此处查阅了大量文献,花了半天时间才解决)。newline='' 指定 行与 行之间的分隔符为空,若没有此参数,会默认行与行之间有一个空行。
line23:指定分隔符为逗号。
line28:URL.format(page=start_page,price=price),此处使用的是str的format方法。打印出每次循环时爬取的网页地址。
line29:使用requests模块的get方法获取当前url源码。
line30:使用bs4模块中的BeautifulSoup方法解析网页。解析的方法为“html.parser”.(应该共有好几种方法可以用,此方法为标准方法,速度适中,解析准确率较高).
4.获取想要的信息:
打开赶集网租房信息的网页,选项-开发者工具-Inspector。如下图所示:
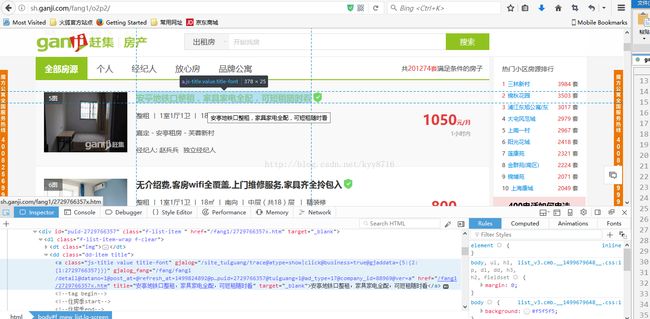
可以查看到每个ITEM对应的class 为:f-list------------f-list-item---------------f-list-item-wrap.
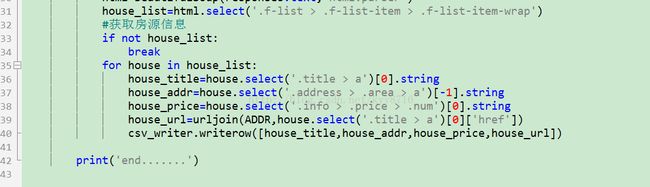
标题、地址、价格分别可以得到,然后进行撸代码,如下图:
5. 开始运行代码:结果如下图所示:

这样就得到了,租房信息的标题,房子所在位置,及相对应的url链接。大功告成!