最通俗易懂的 Windows10 下配置 pyspark + jupyterlab 讲解(超级详细)
最通俗易懂的 Windows10 下配置 pyspark + jupyterlab 讲解(超级详细)
一、所需组件版本说明
- Java JDK:1.8.0.242(这里我使用的是openjdk解压缩版本,oracle jdk只有exe的安装版本)
- spark-2.4.5-bin-hadoop2.7
- hadoop-2.7.7
- scala-2.13.1
- hadooponwindows-master(适合Hadoop 2.7.*版本的)
- Anaconda(Python3.7)
注意事项
- 配置的过程中所有路径不要有空格
- 修改过的环境变量记得一路点击确定进行保存,不然不会生效
- Spark运行在Java 8+,Python 2.7+/3.4+和R 3.1+上,这里我使用的是Scala
API,Spark 2.4.5使用的Scala 2.12.您需要使用兼容的Scala版本(2.13.*)
1、JDK安装(openJDK)
不需要进行编译打包,解压到C盘,配置环境变量即用
https://developers.redhat.com/products/openjdk/download
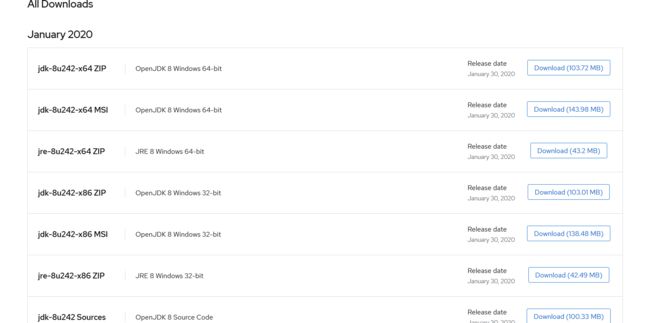
选择对应的操作位数进行下载
下载后配置环境变量
配置环境变量的方法为:电脑[右键]—>属性—>高级系统设置—>环境变量,编辑环境变量的方法见下图


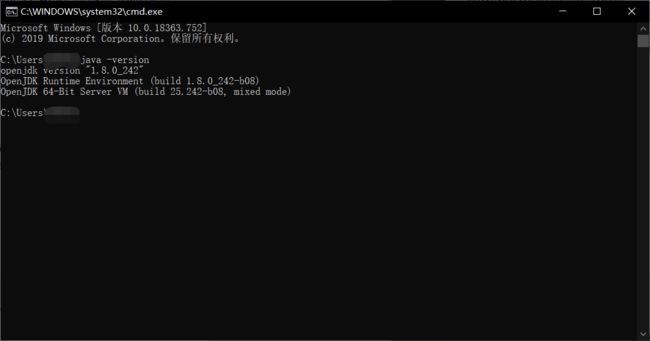
配置完成后,打开命令行测试一下
2、配置Scala
下载地址
https://www.scala-lang.org/download/2.13.1.html
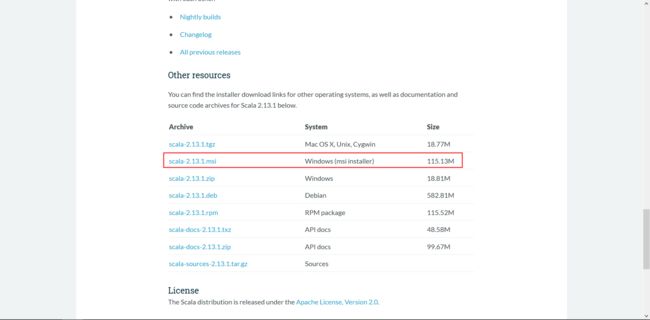
下载完一直点下一步即可完成安装(可以修改默认的安装路径,需要自己修改,配置环境变量的时候与安装路径保持一致)
安装完成后配置环境变量



3、安装Spark
下载地址
http://spark.apache.org/downloads.html

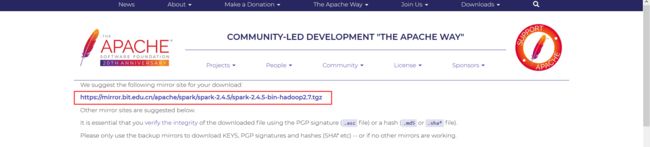
解压后配置环境变量
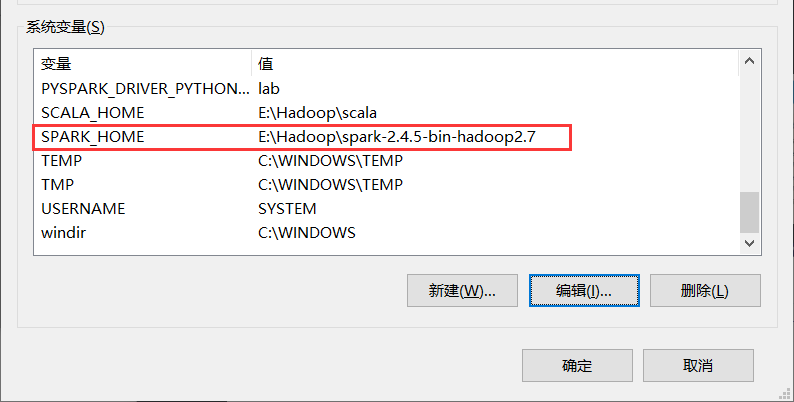
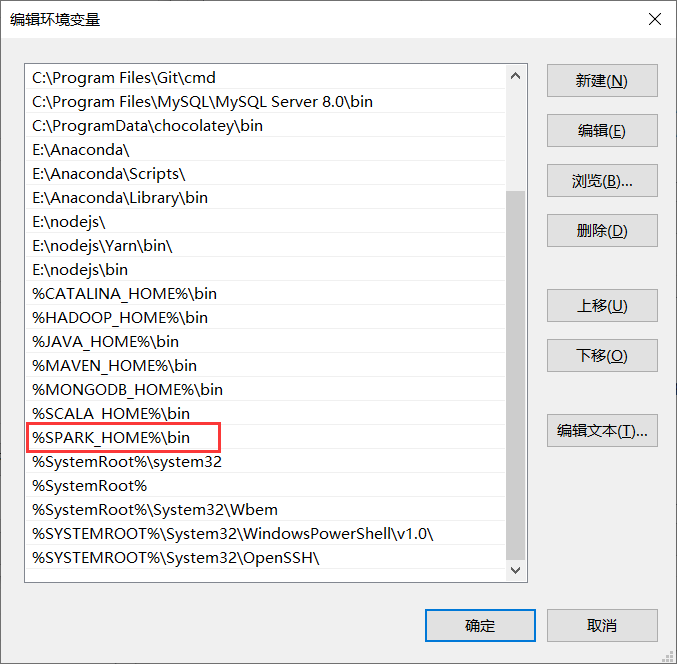
4、安装hadoop
下载地址(这里给的直接是镜像下载目录,官网已经不把Hadoop2.7.7放在首页了)
https://mirror.bit.edu.cn/apache/hadoop/common/

解压后配置环境变量
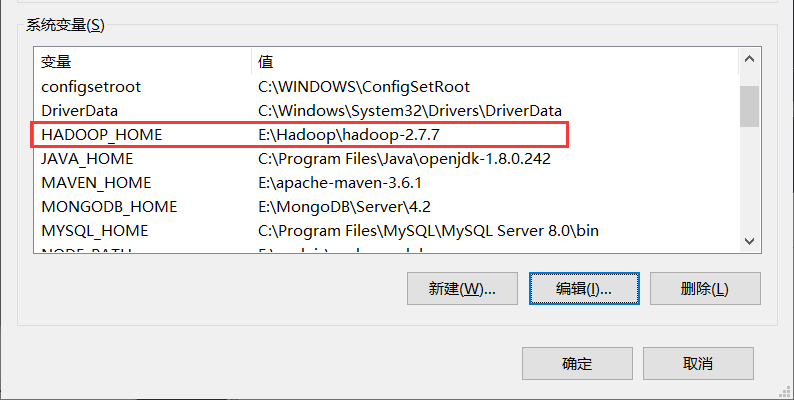

5、安装Anaconda(Python3.7)
下载地址
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/

选择合适的操作位数的版本下载
安装的时候一直点下一步,注意修改安装路径,anaconda安装完有点大,剩下的看着介绍进行安装即可
添加环境变量(如果安装的过程中选择添加了可不必理会下面的内容)

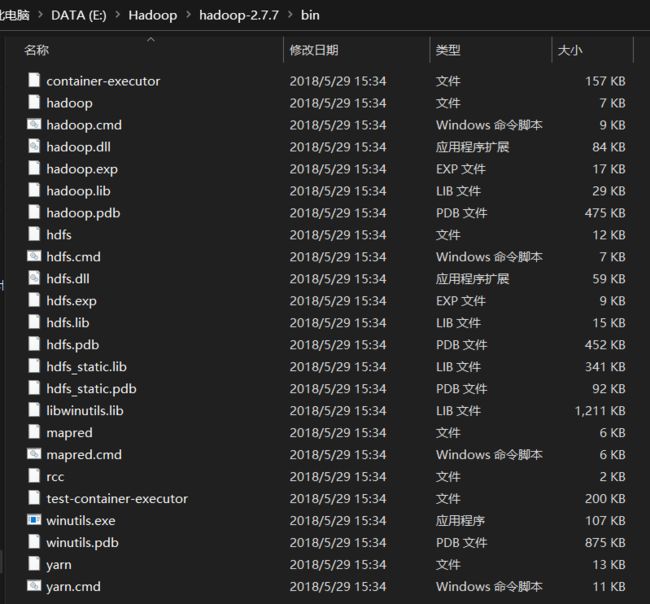
6、使用hadooponwindows-master的bin覆盖hadoop-2.7.7的bin
下载地址
https://github.com/sardetushar/hadooponwindows/
原地址下载慢的可以直接使用我上传的hadooponwindows-master压缩包
上传地址:https://download.csdn.net/download/one_a_xiaobai/12326177
7、处理Python相关
-
将spark所在目录下(例如:E:\Hadoop\spark-2.4.5-bin-hadoop2.7\python)下的pyspark文件拷贝到anaconda所管理的python目录下(例如:E:\Anaconda\Lib\site-packages)
-
安装py4j库
- 运行cmd,激活pyspark所使用的python(activate 你的python环境名称)
- 使用conda install py4j进行下载(速度慢的配置国内镜像:https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/)
-
修改权限
-
将winutils.exe文件放到hadoop的bin目录下(例如:E:\Hadoop\hadoop-2.7.7\bin),注意:如果全程按照我的版本进行的配置,那么winutils.exe已经在你的hadoop安装目录下的bin目录里面了。
-
以管理员的身份运行cmd
-
通过cd命令移动的hadoop的bin目录下
-
执行如下命令(提前创建好一个Hive文件夹,例如:E:\Hadoop\tmp\Hive)
winutils.exe chmod 777 E:\Hadoop\tmp\Hive
-
8、配置在Jupyter Lab中运行PySpark
配置之前保证已经安装了jupyter lab,不确定的可以使用conda list查看一下
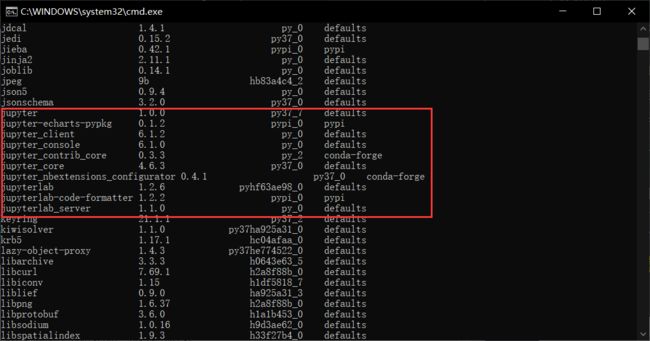
没有安装的话使用conda install jupyterlab进行安装
在Windows下配置的话直接修改环境变量即可
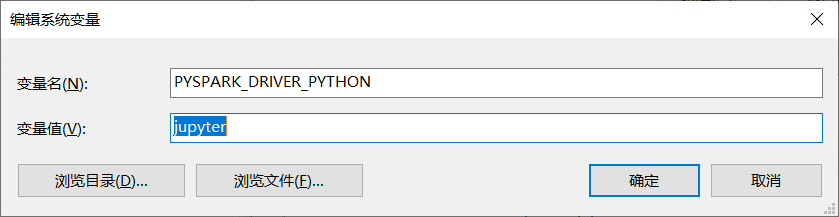
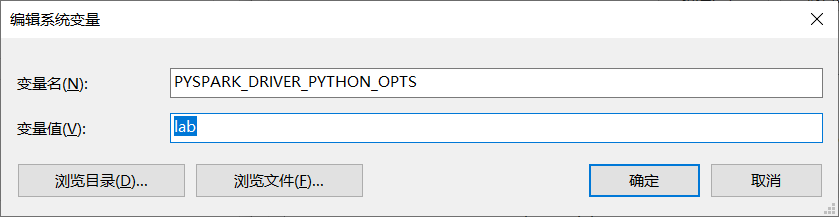

9、启动pyspark
运行cmd,输入pyspark
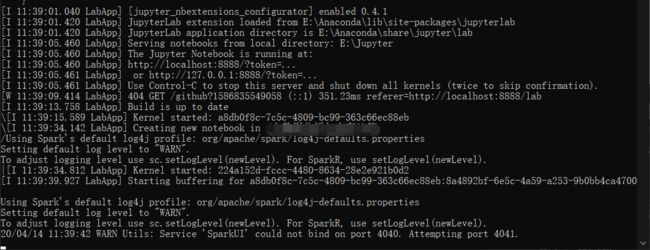
出现以上界面的话恭喜你圆满配置成功
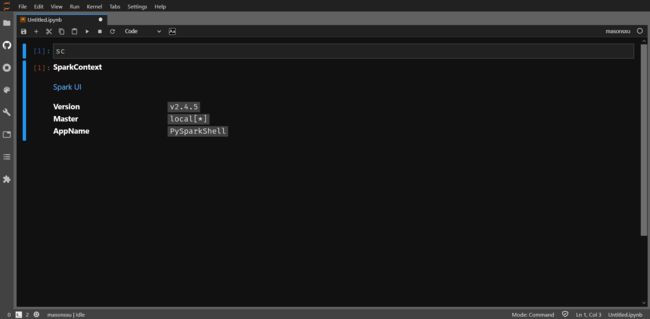
接下来新建一个文件输入sc运行一下,出现如下结果则代表以及能够正常使用pyspark的功能了
总结
spark之前我是在虚拟机安装的Ubuntu上面配置的,无奈,电脑不行,虚拟机使用起来非常的不流畅,不能全功率运行Ubuntu,安装和调试的时候也不方便,总是要用很长时间去捣鼓配置,有时候还会碰到内存不足的情况。虚拟机的强大之处我到现在也体会不到,真是太遗憾了。
pyspark的代码只能在命令行里面输入让我非常的不舒服,敲代码还容易敲错(看来还是敲代码的时间太短了),就想着在ipython上面进行,但是ubuntu本身是python2.7,配置起来很麻烦(主要是虚拟机内存太小了,不能再安装anaconda进行版本控制),就想把pyspark安装到Windows上面来进行操作了。用了一下午的时间查资料,终于是搞好了。
根本原因还是不习惯使用Linux系统,需要多熟悉熟悉。
参考文章
https://www.jianshu.com/p/a65565e325c7
https://www.cnblogs.com/yfb918/p/10978856.html
https://www.cnblogs.com/chenxiangzhen/p/10706258.html