【目标检测】用自己的数据集训练Faster RCNN的详细全过程(步骤很详细很直观,小白可入)
一、写在前面
最近和小伙伴一起参加了服务外包比赛,选择的题目是对于图像中的安全帽的检测。对YOLOv3,Faster RCNN这些常见的目标检测算法都进行了实验。本文就介绍Faster RNN的整个实验过程。
二、电脑相关配置
win10,python3.6
三、训练过程
实验选用的源码是较为常用的Faster RCNN源码。对于该源码的使用网上也有很多的博客文章,但是正是因为文章很多,所以也容易造成一些误导,所以也踩过一些坑。以下是我测试过的可以正确训练的步骤:
1 安装支持包
首先要安装源码运行需要的支持包。下载的Faster RCNN源码中有一个requirement.txt文件,其中记录了需要安装的包的名字。可以在cmd中输入pip install -r requirements.txt安装需要的所有依赖包。也可以自己手动一个个安装,需要的python依赖包有,cython,opencv-python,easydict,Pillow,matplotlib,scipy。
2 修改config.py文件
在lib/config下的config.py文件,是专门的配置文件,其中定义了模型的诸多参数,大家可以根据自己的需要修改相关参数,下面介绍较为重要的需要修改的参数。
(1)network参数
定义预训练使用的模型,我见到的最多的是使用vgg16模型(源码默认也是使用vgg16),也可以使用resnet模型。我采用的是vgg16模型。
(2) learning_rate参数
这个就是我们熟知的学习率,学习率定义的太小收敛速度会很慢,学习率定义的太大可能会导致不收敛。这个参数可以多次调整,分别训练,取一个最优的学习率。
(3) batch_size参数
这个也是很熟知的一个参数,定义的是每一个梯度的大小。一般用的比较多的是32,64,128,256这些batch_size。batch_size太大,内存容量可能撑不住,但是下降方向更准确,震荡更小,而且训练相同量的数据集速度更快;batch_size太小,内存利用率就变小了,但是容易陷入局部最优。个人理解是,如果内存够大,硬件允许的话,batch_size设置的大一些会更容易收敛,效果也会更好。
(4)max_iters参数
这个参数定义的是最大的迭代次数。
(5) snap_iterations参数
这个参数定义的是迭代多少次保存一次模型。个人觉得snap_iterations和max_iters要比较匹配,修改的话需要一起修改。因为如果max_iters参数定义的较小,但是snap_iterations很大的话,就看不到自己生成的模型了。模型保存的路径是default/voc_2007_trainval/default。每次保存模型都是保存4个文件。
(6) roi_bg_threshold_low
这个参数定义的是background(背景)认定的ROI的最小阈值。这里我没有深入研究,但是在运行train.py文件进行训练的时候如果产生Exception:image invalid,skipping。此时修改此处的值为0.0,会解决问题。
3 添加预训练模型
由于我们训练的时候是基于一个预训练模型进行训练的,所以需要下载vgg16模型,并且保存在data/imagenet_weights中。下载的模型命名一般是vgg_16.ckpt,但是我们要修改为vgg16.ckpt。原因是要和源码中调用部分代码一致,源码中调用的名称就是vgg16.ckpt。如果此处不修改,在源码中全部采用vgg_16.ckpt应该也是可以的,但是何必要这么麻烦呢。附上vgg16的百度网盘链接,提取码为45ef。vgg16模型的百度链接
4 制作数据集
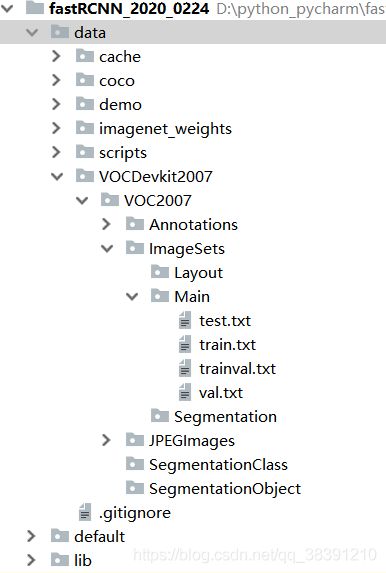
为了可以清楚的显示数据集的制作过程,我将项目中的文件目录截下来。VOCDevkit2007中存放的就是数据集。JPEGImages中放的是图片,Annotations中放的是图片对应的xml文件。test.txt,train.txt,trainval.txt,val.txt中存放的是测试集,训练集,训练验证集,验证集对应的图片名称。至于划分数据集是按照我们自己的意愿进行划分就好,源码并未提供划分代码。划分源码如下,修改name_path(图片所在路径),四个txt文档的的路径,就可以在自己电脑上运行并生成对应txt的内容。
from sklearn.model_selection import train_test_split
import os
name_path = r'.\data\VOCdevkit2007\VOC2007\JPEGImages'
name_list = os.listdir(name_path)
names = []
for i in name_list:
# 获取图像名
names.append(i.split('.')[0])
trainval,test = train_test_split(names,test_size=0.5,shuffle=10)
val,train = train_test_split(trainval,test_size=0.5,shuffle=10)
with open('./data/VOCdevkit2007/VOC2007/ImageSets/Main/trainval.txt','w') as fw:
for i in trainval:
fw.write(i+'\n')
with open('./data/VOCdevkit2007/VOC2007/ImageSets/Main/test.txt','w') as fw:
for i in test:
fw.write(i+'\n')
with open('./data/VOCdevkit2007/VOC2007/ImageSets/Main/val.txt','w') as fw:
for i in val:
fw.write(i+'\n')
with open('./data/VOCdevkit2007/VOC2007/ImageSets/Main/train.txt','w') as fw:
for i in train:
fw.write(i+'\n')
print('done!')
5 运行setup.py生成相应文件
首先进入data/coco/PythonAPI目录的cmd中,先运行python setup.py build_ext --inplace,再运行python setup.py build_ext install;再进入 lib/utils 目录的cmd中,运行python setup.py build_ext --inplace。此时两个目录下都已经生成了需要的文件。
6 删除两个目录下的两个文件
在cache目录下有一个后缀为pkl的文件,default/voc_2007_trainval/default下有上次训练生成的诸多模型。在新的训练之前要把这两个目录下的文件删除(其实就是删除之前训练得到的文件)。
7 修改pascal_voc文件
将pascal_voc文件中line 34中的self._classes进行修改,修改成我们自己数据集对应的类别,其中"background"代表背景这个类别,这是不能修改的,将其他类别换成自己数据集的类别。我的修改如下:

8 运行train.py文件
做好上面的所有修改后,就可以运行train.py文件进行模型训练了。正如上面所说,每次生成的模型都保存在default/voc_2007_trainval/default中。
四、测试过程
1 修改demo.py文件
(1)修改类别
在demo.py文件的line 32行中进行修改,CLASSES为我们自己的数据集对应的所有类别,和上面pascal_voc的修改一样,同时注意不要修改"background"背景类别。

(2)修改预训练模型
修改demo.py中line 104行,修改预训练模型为vgg16,所做的修改如下:
 (3)修改测试图片
(3)修改测试图片
将我们需要测试的图片名称存入im_names中,data/demo中的图片换成我们需要的测试图片,要注意这里的图片名称要和data/demo中的图片保持一致。如下所示:
 (4)修改训练网络和数据集,修改后的line 35,line 36如下:
(4)修改训练网络和数据集,修改后的line 35,line 36如下:
 (5)在相应目录下保存模型
(5)在相应目录下保存模型
default/voc_2007_trainval/default中保存的是每一个模型,我们将我们某一次保存的模型作为demo.py中测试用的模型。新建Faster-RCNN-TensorFlow-Python3-master\output\vgg16\voc_2007_trainval\default目录,将相应的四个文件复制到该目录下。并且修改名字,对应的目录及修改后的模型名称如下所示:
2 运行demo.py文件
运行demo.py文件。可以输出对于测试文件的识别。我的一张图片的识别结果如下:

五、 计算mAP
demo.py文件只是看一下大概的效果,但是衡量一个目标检测模型的好坏的一个重要指标是mAP。计算mAP的步骤如下:
1 修改pascal_voc.py
修改pascal_voc.py文件中line 190,也就是修改filename。修改过程如下:

2 修改demo.py
首先在line 32,line 33添加两个import,如下:

再在demo.py文件后面添加两行代码,如下:
 再新建data\VOCDevkit2007\results\VOC2007\Main目录。
再新建data\VOCDevkit2007\results\VOC2007\Main目录。
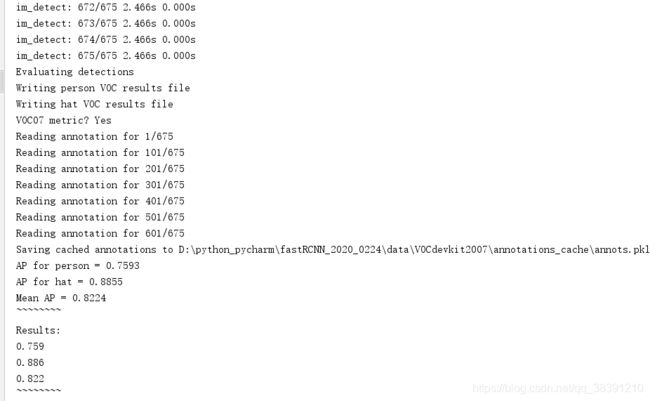
最后运行demo.py文件,等待文件运行结束,可以看到mAP指标的计算结果。我自己运行的得到的结果如下:
六、参考链接
https://blog.csdn.net/huaweiran1993/article/details/102848826
https://blog.csdn.net/qq872890060/article/details/102830836