Python 的一些tricks
1. numpy 拼接
有的时候需要动态numpy的一些array拼接在一起,例如:
从本地磁盘读入txt或者npy文件,解析出array,然后把所有本地txt中的array拼接成一个大的numpy格式的array。
这个时候有2种思路:
(1)先把每一个array都读入,然后一起拼接
(2)一边读入一边拼接
1.1
(推荐此方法)
先把每一个array都读入,然后一起拼接
这里用到2个工具:
- 列表表达式
- np.concatenate
列表表达式代替for循环,可以加快读取的速度,并且把读入的所有array组成一个list;
np.concatenate把list合并成一个大的array。
如下示例中的:
features = np.concatenate([np.load(f) for f in files], axis=0)其中np.load(f)是把本地的npy文件读入到内存,axis=0表示拼接行,列不变。
完整示例:
def get_features(path):
features = []
files = sh.find(path, '-type', 'f', '-name', '*.npy')
files = [f.strip() for f in files]
features = np.concatenate([np.load(f) for f in files], axis=0)
return features1.2
一边读入一边拼接
这种方法的本质是进行多次2个array的拼接。一般可以使用np.append。
由于不能一次拼接多个,所以不可以使用列表表达式,需要通过for循环实现。
这个方法的难点在第一次循环时,只有一个array无法append。所以解决办法有2个(虽然都不优雅):
(1)先读入一个array,然后循环从下一个开始
(2)在循环之前先造一个空的array
1.2.1
方法(1):
def get_features(path):
features = []
files = sh.find(path, '-type', 'f', '-name', '*.npy')
files = [f.strip() for f in files]
features = np.load(files[0])
for i in range(1, len(files )):
features = np.append(features, np.load(files[i]), axis=0)
return features1.2.2
方法(2):
def get_features(path):
features = []
files = sh.find(path, '-type', 'f', '-name', '*.npy')
files = [f.strip() for f in files]
features = np.array([])
for f in files:
arr = np.load(f)
features = np.append(features.reshape(-1, arr.shape[1]), array), axis=0)
return features不论从优雅度、效率还是代码行数,1.1方法都比1.2方法好。所以推荐使用1.1方法。
1+ 求均值、中值、众数
均值和中值:
import numpy as np
#均值
np.mean(nums)
#中位数
np.median(nums)求众数:
from scipy import stats
stats.mode(nums)[0][0]2. 切片操作
这里分为两个,python的切片和numpy的切片。
操作符: [start:end:step]
有点类似于c++ 里面的三目运算符。
其中start,end,step以及第二个冒号:都可以省略。
2.1 python和numpy都有的切片操作
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 前6个
>>> a[:6]
[0,1,2,3,4,5]
# 后3个
>>> a[-3:]
[7,8,9]
# 取偶数
>>> a[::2]
[0,2,4,6,8]
# 取奇数
>>> a[1::2]
[1,3,5,7,9]
# 逆序
>>>a[::-1]
[9,8,7,6,5,4,3,2,1,0]2.2 python独有的切片操作
# 插入操作
>>> a[:0] = ['a', 'b'] # 开始前插入
['a','b',0,1,2,3,4,5,6,7,8,9]
>>> a[len(a):] = ['c', 'd'] # 最后插入
[0,1,2,3,4,5,6,7,8,9,'c', 'd']
>>> a[3:3] = ['m','n'] #中间某个位置插入
[0,1,2,'m','n',3,4,5,6,7,8,9]
# 替换
>>> a[:3] = ['p','q']
['p','q',3,4,5,6,7,8,9]
# 删除
>>> del a[2:5]
[0,1,5,6,7,8,9]2.3 numpy 独有的切片操作
2.3.1 numpy中的索引
numpy中的索引有两种,(1)索引数组 (2)布尔数组
索引数组:
# 一维数组索引
>>> a = np.array([0,1,2,3,4,5,6,7,8,9])
[0 1 2 3 4 5 6 7 8 9]
>>> i = np.array([1,3,5,4,2])
>>> a[i]
array([1, 3, 5, 4, 2])
>>> i2 = np.array([[1,3,5],[2,4,6]])
>>> a[i2]
array([[1, 3, 5],
[2, 4, 6]])
# 二维数组索引
按第一个维度索引
>>> a = np.array([[1,2,3],[4,5,6]])
[[1 2 3]
[4 5 6]]
>>> a[[0,0,1]]
array([[1, 2, 3],
[1, 2, 3],
[4, 5, 6]])
>>> i = np.array([1,0,1])
>>> a[i]
array([[4, 5, 6],
[1, 2, 3],
[4, 5, 6]])
# 用True False list代替切片表达式
>>> arr1 = np.arange(10)
[0 1 2 3 4 5 6 7 8 9]
>>> arr1[[True, False, True, False, True, False, True, False, True, False]]
[0,2,4,6,8]
#
>>> arr2 = np.array([[1,2,3,4,5,6,7,8],[2,3,4,5,6,7,8,9], [3,4,5,6,7,8,9,0]])
[[1 2 3 4 5 6 7 8]
[2 3 4 5 6 7 8 9]
[3 4 5 6 7 8 9 0]]
>>> arr2[[True, True, False], ::-2]
[[8 6 4 2]
[9 7 5 3]]布尔数组:
>>> a = np.arange(12).reshape(3,4)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
>>> b = a>4
>>> print(b)
[[False False False False]
[False True True True]
[ True True True True]]
>>> a[b]
array([ 5, 6, 7, 8, 9, 10, 11])
>>> a[[True, True, False], :]
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
>>> a[:, [True, False, True, False]]
array([[ 0, 2],
[ 4, 6],
[ 8, 10]])
2.3.2 索引和切片相结合
主要在多维切片的时候比较好用,不容易混淆。
比方说我有一个3行4列的数组,需要其中的1 2行和1 3列组成一个新的数组
>>> a = a = np.arange(12).reshape(3,4)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
>>> a[:2][:, [True, False, True, False]]
array([[0, 2],
[4, 6]])其中a[:2] 先得到数组array([[0, 1, 2, 3],[4, 5, 6, 7]]), 然后后面的[:, [True, False, True, False]]把1 3列提取出来了。
其中布尔数组还可以和np.where结合
>>> a = np.arange(12)
>>> print(a)
[ 0 1 2 3 4 5 6 7 8 9 10 11]
>>> b = np.where((a>3)&(a<9))
>>> print(b)
(array([4, 5, 6, 7, 8]),)
>>> a[b]
array([4, 5, 6, 7, 8])
>>> c = (a>3)&(a<9)
>>> print(c)
[False False False False True True True True True False False False]
>>> a[c]
array([4, 5, 6, 7, 8])
注意 (a>3) & (a<9) 中的两个括号不能省略。
另外, (a>3) & (a<9)得到的是一个布尔数据,np.where((a>3)&(a<9))得到的是索引数组。这两种方式都可以对a进行索引/切片操作。
3. 列表表达式
列表解析总共有两种形式:
1. [i for i in range(k) if condition]:此时if起条件判断作用,满足条件的,将被返回成为最终生成的列表的一员。
2. [i if condition else exp for exp]:此时if...else被用来赋值,满足条件的i以及else被用来生成最终的列表。
#
a = [i for i in range(15) if i < 10]
print(a)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
b = [i if i%2==0 else i*i for i in range(10)]
print(b)
# [0, 1, 4, 3, 16, 5, 36, 7, 64, 9]
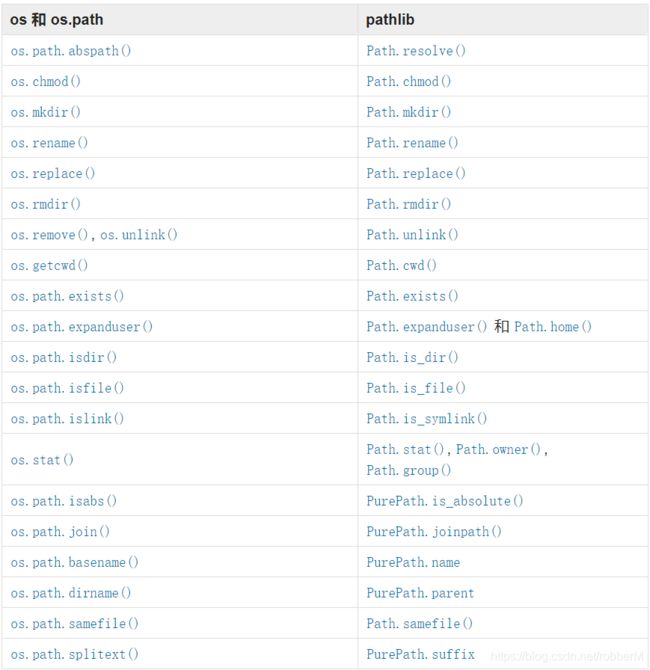
4. Path的使用
推荐使用pathlib
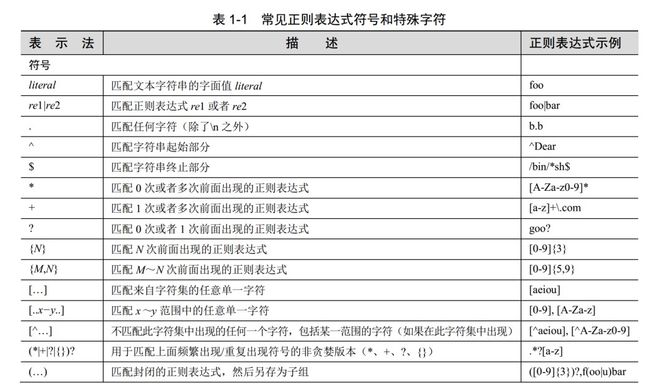
5. 正则表达式
模块:re
函数:compile, match, search, findall
- compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。
- match 从第一个字符(默认)或者指定位置开始匹配
- serarch 返回匹配到的第一个pattern
- findall 匹配所有,并返回一个list。
5.0 基本
-
pattern : 一个字符串形式的正则表达式
-
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I 忽略大小写
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和 # 后面的注释
5.1 re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() , search() , findall() 函数使用。
语法格式为:
re.compile(pattern[, flags])example:
>>>import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
5.2 re.findall 函数
from itertools import chain
import numpy as np
data = '[0.2, 0.3, 0.1, 0.2, 0.5], [0.6, 0.8, 0.4, 0.2, 0.5]'
p = re.compile(r'[[](.*?)[]]', re.S) #
data = re.findall(p,data)
print(data)
data = [s.split(',') for s in data]
data = list(chain(*data)) #
print(data)
data = np.array(data, dtype = np.float64)
print(data)
>>> ['0.2, 0.3, 0.1, 0.2, 0.5', '0.6, 0.8, 0.4, 0.2, 0.5']
>>> ['0.2', ' 0.3', ' 0.1', ' 0.2', ' 0.5', '0.6', ' 0.8', ' 0.4', ' 0.2', ' 0.5']
>>> [0.2 0.3 0.1 0.2 0.5 0.6 0.8 0.4 0.2 0.5]