ElasticSearch单机多实例伪集群部署
1. 前言
es集群生产环境中,一般不建议单机部署多实例,如果使用的是一台高配(高内存)物理机,内存≥512GB,单实例部署就有点浪费资源了(单实例安装参考),此时应考虑单机多实例伪集群部署。
系统环境:Centos 7.6
运行环境:jdk1.8
Elasticsearch版本:6.7.0
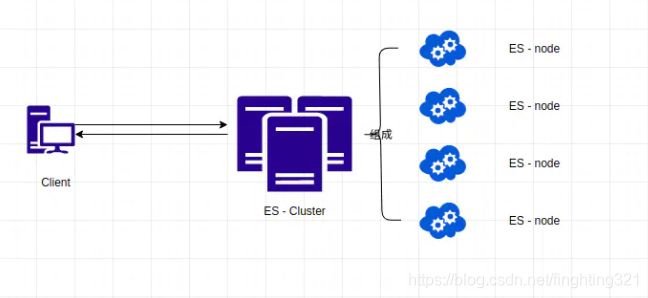
2. 单机多节点(伪集群)
es 伪集群:es服务在同一台机器上根据不同的端口启动服务,构成在本机上的一个集群模式
2.1 解压,复制三份
# tar -zxvf elasticsearch-6.7.0.tar.gz -C /opt/elk
# cp -rf elasticsearch-6.7.0 elasticsearch-6.7.0-node1
# cp -rf elasticsearch-6.7.0 elasticsearch-6.7.0-node2
# cp -rf elasticsearch-6.7.0 elasticsearch-6.7.0-node3

注意:elasticsearch-6.7.0-node*文件夹必须拥有es用户组权限 chown -R es:es elasticsearch-6.7.0-node*
2.2 配置主节点node1
#集群名称
cluster.name: elasticsearch
#节点名称
node.name: node-1
#数据、日志存储目录
path.data: /home/elasticsearch/data/node-1
path.logs: /home/elasticsearch/logs/node-1
#设置为true来锁住内存,因为当jvm开始swapping时es的效率会降低,所以要保证它不swap
bootstrap.memory_lock: true
#将绑定到所有网络接口
network.host: 0.0.0.0
#监听端口,不配的话,es会从9200-9299当中找一个未用过的
http.port: 9200
#禁用系统调用过滤器
bootstrap.system_call_filter: false
#保障head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
#设置角色,是否让这个节点作为默认的master,若不是,默认会选择集群里面的第一个作为master
node.master: true
node.data: true
#es集群节点之间的通信端口号。默认9300
transport.tcp.port: 9300
#设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
discovery.zen.ping.unicast.hosts: ["172.20.32.220:9300","172.20.32.220:9301","172.20.32.220:9302"]
#最小主节点个数。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 2
#设置集群中N个节点启动时进行数据恢复,默认为1
gateway.recover_after_nodes: 1
#自动创建索引,默认true
action.auto_create_index: true
2.3 配置子节点node2
#集群名称
cluster.name: elasticsearch
#节点名称
node.name: node-2
#数据、日志存储目录
path.data: /home/elasticsearch/data/node-2
path.logs: /home/elasticsearch/logs/node-2
#设置为true来锁住内存,因为当jvm开始swapping时es的效率会降低,所以要保证它不swap
bootstrap.memory_lock: true
#将绑定到所有网络接口
network.host: 0.0.0.0
#监听端口,不配的话,es会从9200-9299当中找一个未用过的
http.port: 9201
#禁用系统调用过滤器
bootstrap.system_call_filter: false
#保障head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
#设置角色,是否让这个节点作为默认的master,若不是,默认会选择集群里面的第一个作为master
node.master: true
node.data: true
#es集群节点之间的通信端口号。默认9300
transport.tcp.port: 9301
#设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
discovery.zen.ping.unicast.hosts: ["172.20.32.220:9300","172.20.32.220:9301","172.20.32.220:9302"]
#最小主节点个数。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 2
#设置集群中N个节点启动时进行数据恢复,默认为1
gateway.recover_after_nodes: 1
#自动创建索引,默认true
action.auto_create_index: true
2.4 配置子节点node3
#集群名称
cluster.name: elasticsearch
#节点名称
node.name: node-3
#数据、日志存储目录
path.data: /home/elasticsearch/data/node-3
path.logs: /home/elasticsearch/logs/node-3
#设置为true来锁住内存,因为当jvm开始swapping时es的效率会降低,所以要保证它不swap
bootstrap.memory_lock: true
#将绑定到所有网络接口
network.host: 0.0.0.0
#监听端口,不配的话,es会从9200-9299当中找一个未用过的
http.port: 9202
#禁用系统调用过滤器
bootstrap.system_call_filter: false
#保障head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
#设置角色,是否让这个节点作为默认的master,若不是,默认会选择集群里面的第一个作为master
node.master: true
node.data: true
#es集群节点之间的通信端口号。默认9300
transport.tcp.port: 9302
#设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
discovery.zen.ping.unicast.hosts: ["172.20.32.220:9300","172.20.32.220:9301","172.20.32.220:9302"]
#最小主节点个数。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 2
#设置集群中N个节点启动时进行数据恢复,默认为1
gateway.recover_after_nodes: 1
#自动创建索引,默认true
action.auto_create_index: true注意:以上节点配置,根据个人实际环境修改IP地址。以及node.master和node.data是否设为主节点根据现场环境配置做适当调整。
2.5 修改储存数据和日志目录权限
mkdir -p /home/elasticsearch/logs/node-1
mkdir -p /home/elasticsearch/logs/node-2
mkdir -p /home/elasticsearch/logs/node-3
mkdir -p /home/elasticsearch/data/node-1
mkdir -p /home/elasticsearch/data/node-2
mkdir -p /home/elasticsearch/data/node-3
chown -R es:es /home/elasticsearch3. 启动
es用户下,分别进入elasticsearch-6.7.0-node1、node2、node3目录下启动:
# ./bin/elasticsearch //前台启动
# ./bin/elasticsearch -d //后台启动
查看实例状态
# curl -s -XGET "http://127.0.0.1:9200/_cat/nodes?v"

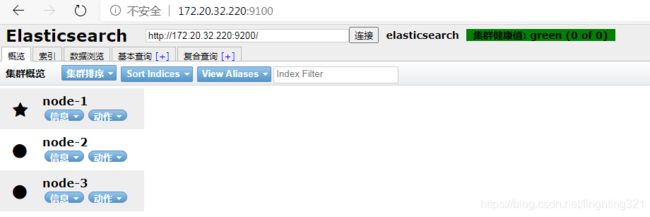
4. head插件访问
head插件安装参考
浏览器访问: http://172.20.32.220:9100/