二 Flink入门之wordcount
1.1 导入Maven依赖
pom.xml
4.0.0
org.example
flink
1.0-SNAPSHOT
1.8
1.8
UTF-8
2.11.8
2.11
1.9.1
2.7.6
org.scala-lang
scala-library
${scala.version}
junit
junit
4.8.1
test
org.apache.hadoop
hadoop-common
${hadoop.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
org.apache.flink
flink-scala_${scala.main.version}
${flink.version}
org.apache.flink
flink-streaming-scala_${scala.main.version}
${flink.version}
org.apache.flink
flink-connector-kafka_${scala.main.version}
${flink.version}
org.apache.flink
flink-table-api-scala-bridge_${scala.main.version}
${flink.version}
org.apache.flink
flink-table-planner_${scala.main.version}
${flink.version}
src/main/scala
src/test/scala
org.scala-tools
maven-scala-plugin
2.15.0
compile
testCompile
-dependencyfile
${project.build.directory}/.scala_dependencies
org.apache.maven.plugins
maven-surefire-plugin
2.6
false
true
**/*Test.*
**/*Suite.*
1.2 a.txt(输入源文件)
hello word! flink demo,
hello$ flink flink
1.3 wordcount简单实列
package bounded
import org.apache.flink.api.scala.ExecutionEnvironment
object Demo_01 {
def main(args: Array[String]): Unit = {
//执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//导入单例类Scala中隐式成员
import org.apache.flink.api.scala._
//WordCount计算步骤
env.readTextFile("input/a.txt")
.map(_.replaceAll("\\pP|\\pS",""))//去除标点以及符号
.flatMap(_.split("\\s+"))//按空格换行把单词分离出来
.filter(_.nonEmpty)//去控
.map((_,1))//把每个单词组装成一个元组(单词,1)
.groupBy(0)//按单词进行分组
.sum(1)//对每个单词出现的数量进行聚合统计
.print()
}
}
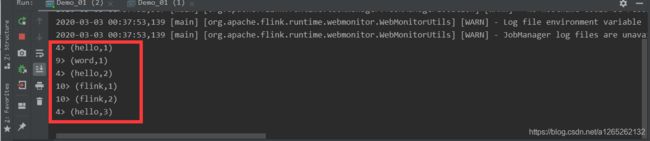
1.4 输出
(demo,1)
(flink,3)
(word,1)
(hello,2)
2.1 wordcount输入输出源都在hdfs(常用)
package com.yuanhanhan.buounded
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.api.scala.ExecutionEnvironment
object Demo_02 {
def main(args: Array[String]): Unit = {
//拦截非法参数 提醒输入参数格式
if(args == null || args.length != 4){
println(
"""
|Warning: Please enter parameters!
|Example: --input inputPath --output outputPath
""".stripMargin)
sys.exit(-1)
}
//获得输入参数并解析得到输入输出路径
val tool: ParameterTool = ParameterTool.fromArgs(args)
val inputPath = tool.get("input")
val outputPath = tool.get("output")
//执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//导入隐式成员
import org.apache.flink.api.scala._
//wordcount计算
env.readTextFile(inputPath)
.map(_.replaceAll("\\pP||\\pS", ""))
.flatMap(_.split("\\s"))
.map((_,1))
.groupBy(0)
.sum(1)
.writeAsText(outputPath)
.setParallelism(1)//设置并行度为1 产生一个文件
//触发执行(不写这句只是懒加载,不会产生结果)
env.execute(this.getClass.getSimpleName)
}
}
2.2 把代码打成jar包上传集群,创建hdfs输入输出文件目录
用idea将项目打包

模拟在hdfs上传输入输出路径,把输入文件上传hdfs
[root@master ~]# hdfs dfs -mkdir -p /flink/input
[root@master ~]# hdfs dfs -put /root/input/a.txt /flink/input/
[root@master ~]# hdfs dfs -mkdir -p /flink/output
用flink-run方式提交job
flink run -m yarn-cluster -yn 2 -c com.yuanhanhan.buounded.Demo_02 -d /root/jar/flink-1.0-SNAPSHOT.jar --input hdfs://cluster/flink/input/a.txt --output hdfs://cluster/flink/output/a_output
//目录中的cluster这里是高可用hdfs的入口 不是目录
验证:
master:8088

[root@master jar]# hdfs dfs -cat /flink/output/a_output
(demo,1)
(flink,3)
(hello,2)
(word,1)
注意:提交任务到集群上运行每个必须添加一个jar包,否则报错
积分下载地址:download
3.1 端口监听输入数据 wordcount实时处理数据
代码
package com.yuanhanhan.unbounded
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object Demo_03 {
def main(args: Array[String]): Unit = {
if(args == null || args.length !=4){
println(
"""
|Warning: Please enter parameters!
|Example: --host 192.168.170.152 --port 6666
""".stripMargin)
}
//获得输入参数
val tool = ParameterTool.fromArgs(args)
val hostname = tool.get("hostname")
val port = tool.getInt("port")
//执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//导入隐式成员
import org.apache.flink.api.scala._
//计算
env.socketTextStream(hostname, port)
.map(_.replaceAll("\\pP|\\pS", ""))
.flatMap(_.split("\\s+"))
.map((_,1))
.keyBy(0)
.sum(1)
.print()
//执行
env.execute(this.getClass.getSimpleName)
}
}
让程序执行的时候携带参数

创建端口并往端口输入数据
[root@master ~]# nc -lk 6666
hello word hello flink
hello flink
验证结果