SQL语句进阶学习一(where、通配符、正则表达式、计算字段、数据处理函数、分组数据)
SQL语句进阶学习一
- MYSQL的基本概念
- 主键(primary key):其值能够区分表中的每一行
- sql(strutured query language)
- 过滤数据
- 搜索模式:由字面值、通配符或两者组合构成的搜索条件
- 变量名:所有MySQL的变量必须以@开始。
- where子句操作符
- 1.检查单个值
- 2.不匹配检查
- 3.范围值检查:只能从小到大的顺序编写。
- 4.or和and同时存在的情况
- 注意事项:计算次序,当and和or同时在场时,先执行and的语句再执行or的语句
- 5.in操作符
- 两者的差别
- not语句
- 不等于的语句
- 通配符进行过滤,子句中使用通配符,必须使用like操作符,代表不是精确匹配而是模糊匹配
- 百分号(%)通配符:%代表搜索模式中给定位置的0个,1个或者多个字符。
- 通配符%在字符串的后面
- 通配符%在字符两侧,构成模糊查询
- 通配符%在字符中间
- 尾空格问题:如果它后面有一个或者多个空格,则不会被匹配成功。如:product_name like '%联想' ,将不能匹配‘联想 ’成功。
- 下划线(_)通配符:下划线通配符表示只能匹配单个字符
- 注意事项
- 正则表达式的使用
- 1.正则表达式的概念:匹配文本中一些特殊的字符,文本。
- 2.like操作符和正则表达式的区别:like匹配的是整列值,而正则表达式匹配的是整列值内进行匹配。当然正则表达式也可以匹配整列。
- 3.使用BINARY关键字,对其搜索进行大小写区分。而regexp是对搜索不进行大小写区分的。
- 4.基本字符匹配
- 5.进行or匹配
- 6.匹配几个字符之一
- 7.范围匹配
- 8.匹配特殊字符
- 9.匹配字符类
- 10.匹配对个实例
- 11.匹配定位符
- 计算字段
- 1.拼接字段
- 2.执行算术计算
- 使用数据处理函数
- 1.文本处理函数
- 2.日期和时间使用函数(对时间区间的筛选)
- 3.数值处理函数
- 汇总数据
- 1.聚集函数
- 2.聚集不同值
- 分组数据
- 1.创建分组
- 2.过滤分组
- 3.分组排序
- select * from table order by price desc/asc;
- select sort,output,price from book where price between 10 and 20 order by price , output;
- 4.select子句顺序
MYSQL的基本概念
主键(primary key):其值能够区分表中的每一行
sql(strutured query language)
过滤数据
搜索模式:由字面值、通配符或两者组合构成的搜索条件
变量名:所有MySQL的变量必须以@开始。
where子句操作符
1.检查单个值
select * from table where username = ‘张三’;(查找名字叫做张三的用户信息)
select * from table where price >= 10;(查找价格大于或等于10元的商品信息)
2.不匹配检查
select * from table where price <>13;(查找价格不等于13元的商品信息)
3.范围值检查:只能从小到大的顺序编写。
select * from table where price between 13 and 17;(查找价格为13到17的商品)
4.or和and同时存在的情况
注意事项:计算次序,当and和or同时在场时,先执行and的语句再执行or的语句
1)select * from table where id = 1 or id = 2 and price >=13;(当or和and同时存在时,sql会先执行and的语句。即查找出id为2且价格大于等于13或者id=1的商品信息)
2)select * from table where (id = 1 or id = 2) and price >=13;(查找商品id为1或者2且他们的价格小于等于13的商品)
5.in操作符
select * from tabel where price in (1,3,13);(查找商品价格为1,3,13的商品信息)
本条语句也可以 select * from tabel price = 1 or price = 3 or price = 13;
两者的差别
1.使用in的语法更清晰
2.使用in的次序更清楚,而or还要考虑次序的规则
3.in的操作速度会比or的操作速度更快
4.in的最大优点是可以包含其他的where语句
not语句
select * from table where price not in (1,3);(查找价格不为1和3的商品信息)
不等于的语句
select * from reader where name != ‘赵正义’;
通配符进行过滤,子句中使用通配符,必须使用like操作符,代表不是精确匹配而是模糊匹配
百分号(%)通配符:%代表搜索模式中给定位置的0个,1个或者多个字符。
通配符%在字符串的后面
select * from table where username like ‘ZW%’;(查找出用户名以ZW开头的信息,%告诉MySQL接受ZW之后的任意字符,不管它有多少字符,这个搜索是区分大小写的)
通配符%在字符两侧,构成模糊查询
select * from table where username like ‘%ZW%(查找出用户名包含ZW的信息的用户信息)’
通配符%在字符中间
select * from table where username like ‘e%s’(查找出用用户名以e开头,以s结尾的信息)
尾空格问题:如果它后面有一个或者多个空格,则不会被匹配成功。如:product_name like ‘%联想’ ,将不能匹配‘联想 ’成功。
解决办法:1.后面再增加通配符%
2.使用函数去掉首尾空格
下划线(_)通配符:下划线通配符表示只能匹配单个字符
select * from table where username like ‘_ZW’;
注意事项
1.通配符的查询效率很低,尽量使用其他的操作符
2.不要将通配符放在搜索模式的开始处,像like ‘%ZW’,造成索引失效;
3.注意通配符的位置。
4.通配符%不能匹配到NULL值
正则表达式的使用
1.正则表达式的概念:匹配文本中一些特殊的字符,文本。
2.like操作符和正则表达式的区别:like匹配的是整列值,而正则表达式匹配的是整列值内进行匹配。当然正则表达式也可以匹配整列。
如:select * from table where username like ‘zhangsan’;
select * from table where username regexp ‘zhangsan’;
第一个不能查出叫做zhangsanfeng的信息,而第二个可以查出叫做zhangsanfeng的信息。
3.使用BINARY关键字,对其搜索进行大小写区分。而regexp是对搜索不进行大小写区分的。
4.基本字符匹配
select username from table where username regexp ‘ZW’;(查找含有用户名含有zw的信息)
select username from table where username regexp ‘.000’;(.是正则表达式语言中一个特殊的字符。它表示可以匹配任意一个字符。因此,1000和2000都可以匹配)
5.进行or匹配
select * from table where username regexp ‘Z|W’;(查找出用户名含有Z或者W的用户信息)
|是正则表达式当中or操作符。
6.匹配几个字符之一
select * from table where username regexp ‘[123]TON’;(查找开头为1,2,3中之一后接TON的用户名信息);
【123】(等价于【1|2|3】)是正则表达式当中的匹配指定的单一字符,指定的字符中取一,是另一种形式的or语言。【^123】排除指定的字符,匹配其余的任意字符。
7.范围匹配
select * from table where phone regexp ‘[1-7]ZW’;(查找口头为1到7这个范围的数字且含有ZW的信息)
8.匹配特殊字符
select * from table where username regexp ‘.’;(在正则表达式中,.代表可以匹配任意字符,因此需要增加\来进行转义,使其表达可以匹配带有.的字符)
MySQL使用两个转义字符对其进行编译,MySQL自己解释一个,正则表达式库解释另一个。
9.匹配字符类
[:alnum:] 任意字母和数字(同[a-zA-Z0-9])
[:alpha:] 任意字符(同[a-zA-Z])
[:blank:] 空格和制表(同[\\t])
[:cntrl:] ASCII控制字符(ASCII 0到31和127)
[:digit:] 任意数字(同[0-9])
[:graph:] 与[:print:]相同,但不包括空格
[:lower:] 任意小写字母(同[a-z])
[:print:] 任意可打印字符
[:punct:] 既不在[:alnum:]又不在[:cntrl:]中的任意字符
[:space:] 包括空格在内的任意空白字符(同[\\f\\n\\r\\t\\v])
[:upper:] 任意大写字母(同[A-Z])
[:xdigit:] 任意十六进制数字(同[a-fA-F0-9])
10.匹配对个实例
select product from table where regexp ‘\\([0-9] sticks?\\)’(\\是对()是对其转义,正则表达式中,?代表?前的字符可以出现一次或者零次。如:s可以出现一次或者零次。查询的结果为(1 sticks) 或(1 stick)).
正则表达式
*0个或多个匹配
+1个或多个匹配(等于{1,})
? 0个或1个匹配(等于{0,1})
{n} 指定数目的匹配
{n,} 不少于指定数目的匹配
{n,m} 匹配数目的范围(m不超过255)
11.匹配定位符
定位元字符
^ 文本的开始
$ 文本的结尾
[[:<:]] 词的开始
[[:>:]] 词的结尾
select * from table where regexp ‘^[0-9\\.]’;
(查出表格中以数字或者.开头的用户信息)
计算字段
1.拼接字段
1)拼接
a)含义:将值连接在一起拼接成单个值。MySQL使用concat()函数。多数DBMS使用+或||实现拼接。
b)实例:

concat()连接每一个串,每一个串必须用,号隔开。上条语句包含四个串,vend_name,(左圆括号,)右圆括号,vend_country.
2)去除空格
a)含义:将串的空格删除去掉。去除串两端的空格使用trim()函数,去掉串左边的空格使用Ltrim()函数,去掉右边的空格使用Rtrim()函数。
b)实例:

3)使用别名
a)含义:为新的拼接字段赋予一个新的名字。使用关键字as.
b)实例:
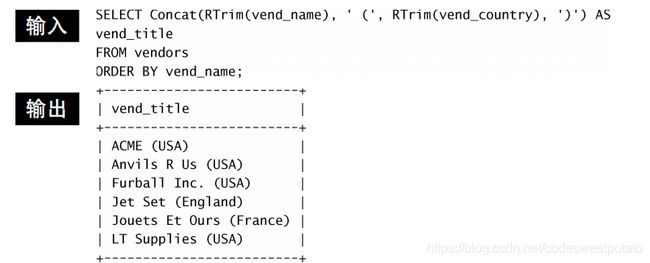
2.执行算术计算
a)含义:对检索的字段进行算术计算。
b)实例:
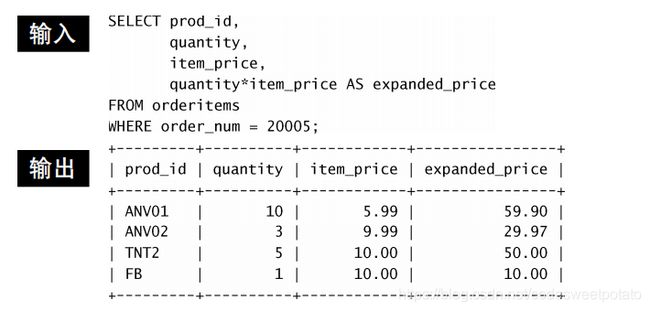
计算检索出来的数据quantity*item_price作为expanded_price新字段。
使用数据处理函数
1.文本处理函数
a)常用的文本处理函数
函 数 说 明
Left() 返回串左边的字符
Length() 返回串的长度
Locate() 找出串的一个子串
Lower() 将串转换为小写
LTrim() 去掉串左边的空格
Right() 返回串右边的字符
RTrim() 去掉串右边的空格
Soundex() 返回串的SOUNDEX值
SubString() 返回子串的字符
Upper() 将串转换为大写
b)实例

2.日期和时间使用函数(对时间区间的筛选)
a)常见日期和时间函数
函 数 说 明
AddDate() 增加一个日期(天、周等)
AddTime() 增加一个时间(时、分等)
CurDate() 返回当前日期
CurTime() 返回当前时间
Date() 返回日期时间的日期部分
DateDiff() 计算两个日期之差
Date_Add() 高度灵活的日期运算函数
Date_Format() 返回一个格式化的日期或时间串
Day() 返回一个日期的天数部分
DayOfWeek() 对于一个日期,返回对应的星期几
Hour() 返回一个时间的小时部分
Minute() 返回一个时间的分钟部分
Month() 返回一个日期的月份部分
Now() 返回当前日期和时间
Second() 返回一个时间的秒部分
Time() 返回一个日期时间的时间部分
Year() 返回一个日期的年份部分
b)实例

order_date是个dateTime的类型数据时,其不单单有日期还有具体的时间,使用Date()的函数就可以只筛选出日期,而且时间的范围应该用beteen and的关键字进行连接。

此方法无需记住该月份有多少天。
3.数值处理函数
函 数 说 明
Abs() 返回一个数的绝对值
Cos() 返回一个角度的余弦
Exp() 返回一个数的指数值
Mod() 返回除操作的余数
Pi() 返回圆周率
Rand() 返回一个随机数
Sin() 返回一个角度的正弦
Sqrt() 返回一个数的平方根
Tan() 返回一个角度的正切
汇总数据
1.聚集函数
a)常见的聚集函数
函 数 说 明
AVG() 返回某列的平均值
COUNT() 返回某列的行数
MAX() 返回某列的最大值
MIN() 返回某列的最小值
SUM() 返回某列值之和
b)一些注意事项
1.count(*)是计算当前表格的列数,包含null值的列数。而count(column)则不包含null值的函数。
2.max()也可以找出文本数据的最大值,如select max(name) from t_student;同理min()亦是如此。
2.聚集不同值
1)使用distinct()函数。对于只包含不同值的计算。
2)实例:

distinct()函数可以将相同的商品的价格去除。
分组数据
1.创建分组
1)group by关键字。对指定的列进行分组。
2)实例:
注意事项:
group by语句必须在order by语句之前。
2.过滤分组
1)使用关键字having进行分组。
2)having和where的区别。having是对分组进行过滤,而where是对表格行进行过滤。having是对分组后的数据进行过滤,而where是对分组前的数据进行操作。
3)实例
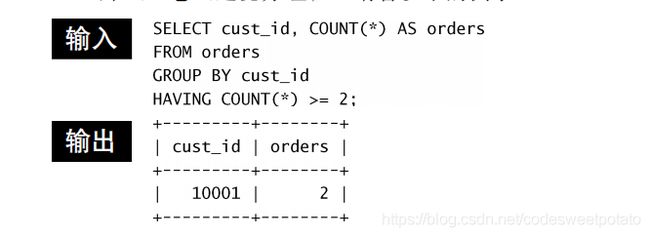
3.分组排序
1)使用关键字。order by关键字。
2)实例

注意事项:
1.order by默认以升序排列,acs是按升序排列,decs是按降序排列。
select * from table order by price desc/asc;
2.order by接多个字段列排序时,字段与字段之间用,号连接。
select sort,output,price from book where price between 10 and 20 order by price , output;
先按price升序进行排序,当价格相同时再按output(出版社)进行排序。
4.select子句顺序
| 子句 | 说明 |
|---|---|
| select | 要返回的列或表达式 |
| from | 从中检索数据的表 |
| where | 仅在从表选择数据时使用 |
| group by | 分组说明 |
| having | 对分组后的数据进行过滤 |
| order by | 进行牌序 |
| limit | 要检索的行数 |