【文献阅读03】Deep Reinforcement Learning Based Resource Allocation for V2V Communications
Deep Reinforcement Learning Based Resource Allocation for V2V Communications(点击可见原文)
p.s.此文19年发表,到20年8月被引199次
论文要解决的问题
单播和广播场景下,考虑V2V通信的资源分配,使用分布式方案,在无 global information 的前提下为 V2V链路 or 车辆 找到最优的子带和功率等级,该算法能满足V2V链路的延迟约束并最小化对 V2I 的干扰。
使用深度强化学习解决,已开源并有哥们写了double DQN的版本。
通信场景 // for unicast communication
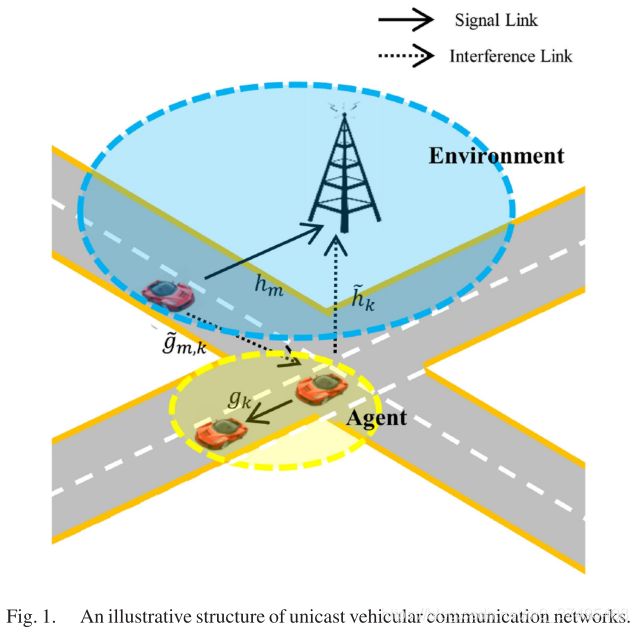
存在 M 个 V2I 链路,K 对 V2V 链路。为提高频谱效率,假设V2V共享V2I的上行链路频谱,这是因为基站处的干扰更易控制且上行链路使用较少。
m号V2I 的 SINR 为:
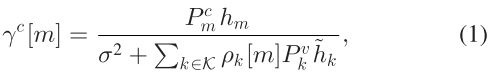
其中 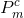 和
和 ![]() 分别表示 m号CUE和 k号VUE 的发射功率,h是与 m号CUE相关的信道的增益,
分别表示 m号CUE和 k号VUE 的发射功率,h是与 m号CUE相关的信道的增益,![]() 是 k号VUE的干扰增益,
是 k号VUE的干扰增益,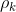 为频谱分配的 indicator
为频谱分配的 indicator
m号V2I 的容量为:
![]()
k号VUE的SINR为:
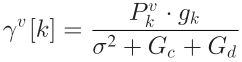
其中,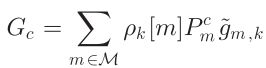 ,
,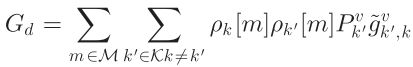 分别表示 与V2I共享频谱引入的干扰功率、与其他V2V共享频谱引入的干扰功率,
分别表示 与V2I共享频谱引入的干扰功率、与其他V2V共享频谱引入的干扰功率,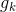 表示k号VUE的功率增益,
表示k号VUE的功率增益,![]() 是m号CUE的干扰功率增益,
是m号CUE的干扰功率增益,![]() 是 k' 号VUE的干扰功率增益
是 k' 号VUE的干扰功率增益
k号VUE的容量为:
![]()
考虑V2V在交通安全中的作用,其延迟和可靠性要求较高,而对数据速率的要求较低。V2V链路的等待时间和可靠性要求在系统设计中转换为中断概率。
对蜂窝用户,其等候时间没有那么严格,而应在一定的公平下考虑基于最大化吞吐量的传统资源分配策略。
因为BS不知道V2V链路的相关信息,因此V2I的资源分配应独立于V2V的资源分配。在V2I资源分配方案确定的前提下,本文目标是通过V2V的资源管理满足 V2V的时延约束 并 尽可能减少V2V对V2I的干扰。分布式的RRM方案中,V2V链路将基于局部观察选择RB和传输功率。
单播场景V2V资源分配的DRL解法
每个V2V链路作为agent,V2V链路以外的全部信息作为环境。对于每个agent来说,其他V2V链路的行为不可控,因此每个独立的V2V链路的动作基于整体的环境条件,例如频谱、传输功率等。
- 动作:子带的选择和传输功率控制
- 可以用一个二维数组表示
- 奖励:V2I容量+V2V容量+V2V时延限制:
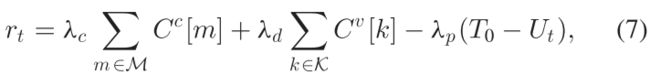
- V2I和V2V的容量作为衡量此分配方案导致的对V2I和V2V的干扰的指标
- 时延作为penalty
- 累计奖励:
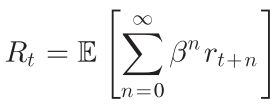
- 状态:s_t = {I_{t-1}, H_t, N_{t-1}, G_t, U_t, L_t}
- V2V链路的瞬时信道信息 G_t[m] = (G_t[1], ..., G_t[M]) # 多播时无此项
- 前一时刻的链路干扰功率 I_{t-1} = (I_{t-1}[1], ..., I_{t-1}[M])
- V2V到BS的功率 H_t = (H_t[1], ..., H_t[M]) 就属于干扰
- 前一时刻的邻居的子带选择 N_{t-1} = (N_{t-1}[1], ..., N_{t-1}[M])
- 车辆的剩余负载 L_t # 多播时无此项
- 传输完成后的的剩余时间 U_t
为了应对状态空间过大引发收敛困难的问题,所以使用DQN。
单agent强化学习会导致:V2V链路的观测值无法表征整个环境,因此设置不同的agent异步上传其动作,即每个time slot只有一个或一小部分V2V链路上传他们的动作,这样,其他agent的动作对环境的影响就可以被当前agent观察到。
文献[28]提出的 co-ordinations 通过允许agent分享各自的动作到邻居,进而为动作决策提供辅助。这招尤其在分布式的资源管理中很实用,还可以避免同时选择同一RB带来的冲突。

多播场景V2V资源分配的DRL解法
系统模型
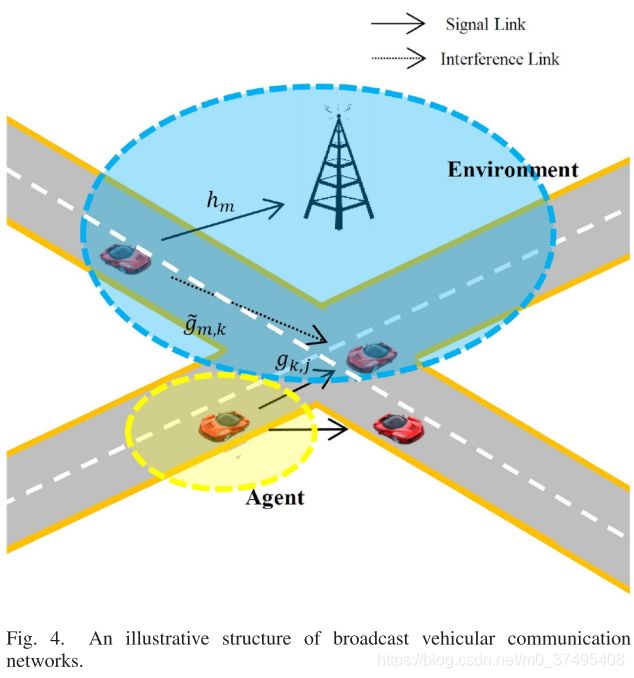
CUE用户集(CUE主体为车,连接到BS,其实就是V2I用户集)为 ![]() ,V2V用户集为
,V2V用户集为 ![]() ,其中每个成员均使用广播发信。V2I的上行频谱被V2V重用,因为上行资源的使用没有那么紧张。
,其中每个成员均使用广播发信。V2I的上行频谱被V2V重用,因为上行资源的使用没有那么紧张。
广播机制:每辆车转播接收到的信息,但不是收到啥转发啥,为避免车多时转播过多的冗余信息,车辆需要选择接收到的信息的一部分来进行转播。
m号V2I链路受到的干扰与单播情况一致: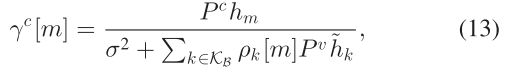
m号CUE用户的容量为:![]()
对于 k 号车辆的第 j 个接收者,其SINR为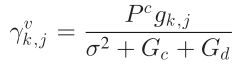
其中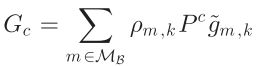 、
、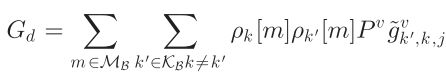
k 号车辆的第 j 个接收者的信道容量为:![]()
- 动作:选择V2V用于广播的信息、选择传输子带。#V2V的动作选择发生在V2I资源分配之后,所以目标是减少对V2I的干扰
- 奖励:VUE的延迟约束 + 最小化VUE对CUE的干扰
- V2I和V2V的容量 + 相应V2V信息的延迟约束
- 为了抑制多余的二次广播,仅考虑没有接收到信息的接收器的容量
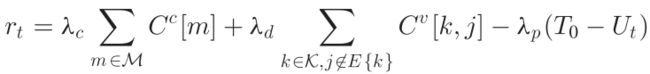
- 状态:在单播的基础上,添加
- 车辆已经接收到的指定信息的次数 O_t;
- 从多个车收到了同一个消息,到最近的车的距离D_t;#通常,如果车辆多次接收该消息或该车靠近之前已广播过该消息的另一辆车辆,则重新广播该消息的可能性会降低
- 瞬时信道干扰功率:I_(t-1)=(I_{t-1}[1], ..., I_{t-1}[M])
- V2I链路在各个子带上的信道信息:H_t = (H_t[1] ,..., H_t[M])
- 上一时刻邻车的子信道选择:N_{t-1} = (N_{t-1}[1], ..., N_{t-1}[M])
- 剩余时间U_t
实验
【单播情况】
单小区系统,载波2GHz,按照3GPP TR36.885的曼哈顿网格模型设置,存在LOS和NLOS两种传输模型。车辆在路上的部署服从空域泊松过程,每辆车和最近的三辆车进行V2V通信。所以V2V链路的数量是车辆数量的三倍。
使用的DQN有五层全连接层,三层隐藏层。每个隐藏层的神经元数量分别为500 250 120,激活函数为ReLU。
起始学习率设置为0.01,指数下降
对照组设置如下:
- 随机选择频谱子带以传输信息
- 车辆首先根据相似性分组,然后迭代式地为每组分配子带
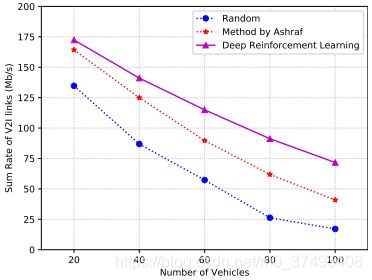
左图:车多导致V2V多,导致对V2I造成的干扰增大,导致V2I速率下降
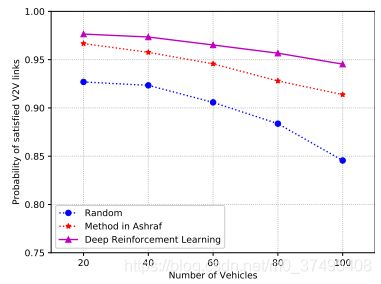
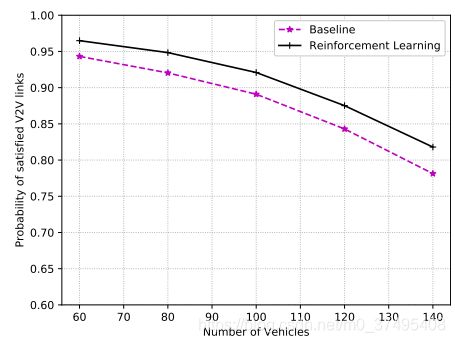
右图:纵坐标为满足延迟约束的车辆的占比
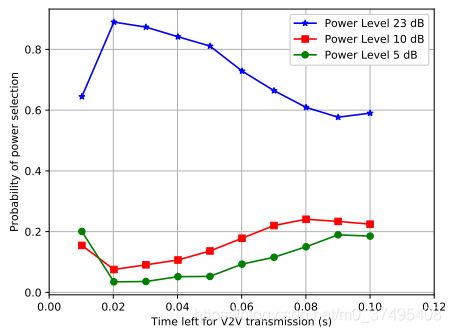
上图:需要一列一列看,在剩余时限不同的时候,V2V链路集中 各链路是倾向于大功率传输还是小功率传输。讲道理当剩余时限小的情况下,链路应该选择大功率(23dB)来尽快把信息传完,但是当剩余时限为0.01时,选择以大功率传输的链路数量反而减少,这是因为此时剩余时间太小,加大功率也无法完成传输,所以通过节约能耗来获取更大的奖励。->>这说明了DQN可以学习到一些隐藏的信息。
【广播情况】
传输成功的判决条件:
- k号车辆的信息被j号接收器成功接受:该链路的信噪比大于 SINR阈值
- V2V传输成功:所有的目标接收器全部成功接收
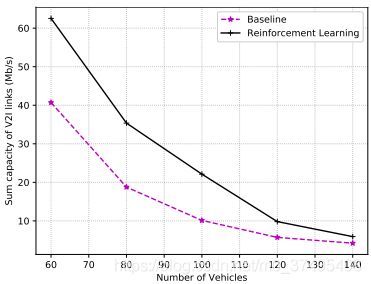
左图:本文方案可以有效降低V2V对V2I的干扰
右图:本文方案以大概率控制车辆满足时延约束因为其可以更有效地选择发送的消息和子带。