【论文笔记】Unsupervised Learning of Video Representations using LSTMs
这篇文章是深度学习应用在视频分析领域的经典文章,也是Encoder-Decoder模型的经典文章,作者是多伦多大学深度学习开山鼻祖Hinton教授的徒子徒孙们,引用量非常高,是视频分析领域的必读文章。
摘要翻译
我们使用长短时记忆(Long Short Term Memory, LSTM)网络来学习视频序列的表征。我们的模型使用LSTM编码器将输入序列映射到一个固定长度的表征向量。之后我们用一个或多个LSTM解码器解码这个表征向量来实现不同的任务,比如重建输入序列、预测未来序列。我们对两种输入序列——原始的图像小块和预训练卷积网络提取的高层表征向量——都做了实验。我们探索不同的设计选择,例如解码器的LSTM是否应该取决于生产的输出。我们定量地分析模型的输出来探讨学习模型对过去和未来视频序列的表征能力。我们通过监督学习任务——UCF101和HMDB-51数据集动作识别——微调学习的表征向量来进一步评估表征能力。我们发现这些表征提高了分类准确度,尤其是当只有少量训练样本的情况下。即使模型通过不相关的数据集(300 hours of YouTube videos)预训练,也能够提高动作识别的性能。
模型描述
LSTM Autoencoder Model
模型中有两个递归神经网络,编码器LSTM和解码器LSTM,如下图。模型的输入是向量序列(图像小块或者特征向量)。当最后一个输入被读入之后,编码器的内部状态和输出状态将会被直接给入decoder。Decoder输入目标序列或者预测序列,目标序列是和输入序列一样的,只不过在顺序上是反向,把顺序反向可以使得优化更简单因为LSTM的输出就是反过来的嘛。解码器decoder既可以是有条件约束的也可以是无条件约束的。有条件约束的decoder就是decoder接受生成的最后一帧作为输入,即下图中的虚线框。无条件约束的decoder就不接受这个输入。
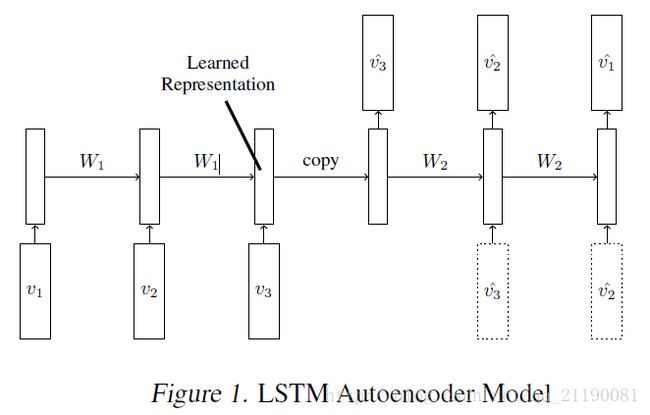
在encoder读入最后视频最后一帧之后LSTM的状态就是输入视频的表征。因为decoder就是需要用到这个表征向量来重建序列,所以这个表征向量需要包含目标、背景以及运动等信息。但是所有自编码器结构的模型都面临着一个问题,就是直接把输入和输出进行对比来实现无监督学习,很难学习到表征能力特别强的简单映射关系。主要两个原因,一个是空间上神经元的数量固定,所以不可能学习到无限长度输入序列的映射;另一个原因是动态单元的数目必须递归地用在表征向量上,这也使得模型很难学习一个通用统一的映射。
LSTM Future Predictor Model
预测模型和自编码器几乎是一样的,差别就在于最后训练的输出,预测模型用的是未来几帧的图像,只不过输出是正序,而不是倒序的,这里作者没有解释,但其实也很好理解,预测的正序和自编码器的倒序是统一的,因为encoder-decoder模型都是从最近的时刻想最远的时刻逐渐解码。自编码器从1,2,3到3,2,1是从近到远,预测的1,2,3到4,5,6也是从近到远。和自编码器类似,预测模型也有条件约束和非条件约束两种,所以最后的预测模型如下图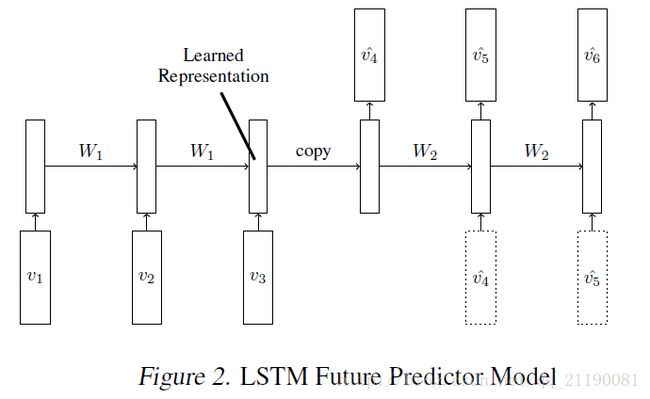
A Composite Model
作者把上面两种模型组合成一个模型,这个模型可以同时实现重建输入和预测输出的功能。上面的两种模型都有各自的缺点,自编码器倾向记住输入序列的信息,而预测模型倾向记住未来几帧的信息。而组合模型把两部分的损失用来训练网络,所以最后得到的表征向量既有过去的记忆也有预测未来的能力,其模型如下图。
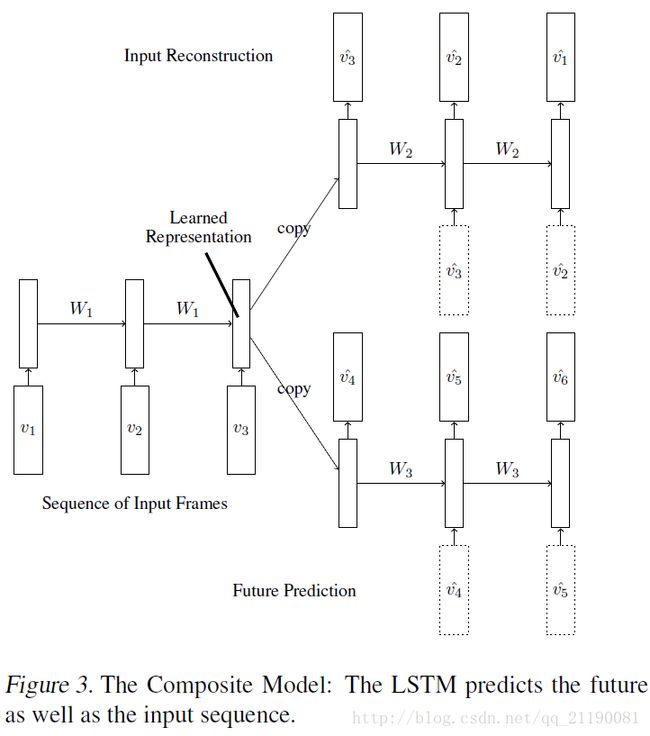
模型描述
作者设计实验来实现以下目的:
- 定性的了解LSTM到底学会了什么
- 用无监督学习训练的参数去初始化有监督学习的参数,尤其是小样本训练的无监督网络,测试下这样做是否对有监督学习有益
- 比较提出的不同模型——自编码器、预测模型和融合模型以及它们是否有条件约束的情况
- 和最领先动作识别的基准进行比较
训练
训练使用RMSProp+monentum基友组合方式。(PS:通常Adam系的训练函数能够更快的收敛,而RMSProp+monentum这个组合通常能得到更好的全局最优解)
数据集
数据集使用的是UCF-101和HMDB-51的监督学习数据集。为了训练无监督的模型,作者还使用Sports-1M中的Youtube视频子集。作者发现和仅仅使用Youtube数据集做无监督训练相比,使用Youtube和UCF-101以及HMDB-51三个数据集做无监督训练并没有提高性能(从侧面验证了上面四个目标中的第二个)。原始的RGB图像使用的网络是Simonyan & Zisserman (2014b),而提取的运动光流使用网络是Simonyan & Zisserman (2014a).另外作者发现fc6全连接层的性能比fc7全连接层要好,所以最后选择了fc6的4096维输出作为视频的表征向量。另外作者提到论文只用了图像中一个小patch做实验,也许用多个patches并且做些畸变加些噪声的预处理或者去除水平偏移等能提高性能。
可视化和定量分析
为了可视化分析三种模型的性能,作者首先利用移动的Mnist数据集训练模型,每个视频含有20帧图像,包含了2个在移动的数字,图像块大小为64×64像素。这些数字及其出现的位置都是随机的,每个数字的运动方向也是在均匀分割的单位圆内随机选一个。如果数字碰到了边缘就反弹,就和打砖块差不多,如果重合了就叠加。
作者首先训练了融合模型,LSTM拥有2048个神经元,编码器输入10帧序列,解码器重建10帧输入序列和预测未来10帧序列。输出使用sigmoid激活函数,损失使用交叉熵损失函数。下图是结果,通过一层模型和两层模型来验证增加深度是否能提高性能,通过增加条件约束来验证条件约束是否能提高性能。

之后对于实际的视频也做了实验,作者从UCF-101数据集的视频中提取了32×32像素的小块,输出用identity激活函数,损失用最小二乘损失函数,输入是16帧,输出重建输入的16帧序列和预测未来的13帧。实验用了2048个神经网络和4096个神经元做对比,结果显示重建序列的图像更加清晰,预测的图像很快就变得模糊。

UCF-101/hmdb-51动作识别
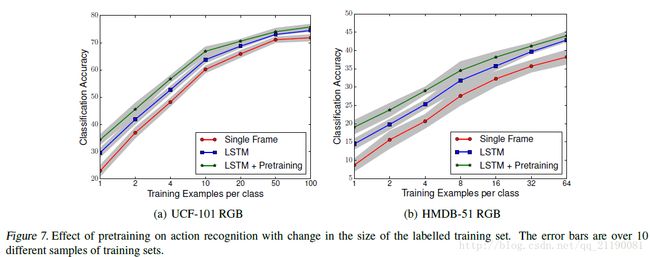
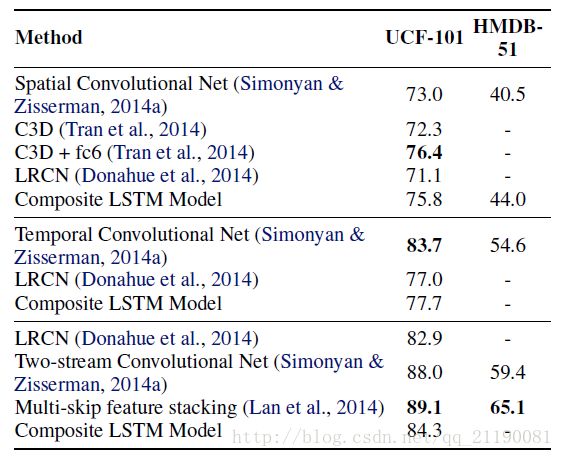
这一部分主要是探讨无监督学习的特征是否有助于提高监督学习任务。大致思路是用Youtube的视频训练融合模型,网络输入是16帧视频,网络输出是重建16帧和预测未来的13帧。之后用这个网络的encoder部分的参数去初始化有监督学习任务的网络,并在最后一次加一层softmax分类层。测试时用的是所有时间step输出的平均,因为LSTM每个时间step都会有一次预测。最后和几个主流的baseline网络进行对比,结果显示本文的方法在各种情况下都提高了准确度,包括利用光流信息的情况。具体数字就不重复了,可以看图表。

不同模型的比较
作者提到,虽然本文的方法有效的降低了重建序列的损失,但是这并不能用来衡量方法的好坏,真正能够衡量方法好坏的应该是动作识别的性能以及预测未来序列的性能。于是作者就用Mnist数据集的交叉熵损失和视频图像的最小二乘损失来衡量未来序列预测的好坏(为什么Mnist可以用交叉熵而视频序列要用最小二乘呢,我猜测是因为Mnist数据集是二值图像,所以等效为分类问题会更好一点,所以用交叉熵,而实际的视频图像是连续的像素值,所以用最小二乘误差)。Table2显示用条件约束的融合模型是最好的。
和动作识别基准的对比
实在不想写了,要不就看下最后的结果图吧,反正就是还不错啦。
总结
其实这篇论文要说很华丽倒也没有很华丽,实验放到现在来看也是比较简单,甚至比较粗糙的,论文的篇幅虽然有好几页其实最后都是在重复的表述着同一些东西,或者叙述图表的数字。但是这篇文章的贡献意义非常大,虽然不敢完全肯定是否是第一篇,但至少这是我看到的最早的一篇把LSTM引入视频分析的论文,并且文中作者提到,为了提高监督学习任务的准确度,可以引入卷积网络,并且堆叠多层本文的方法。于是这一句话开创了视频分析任务的新天地,成功预测出(或者说是指明)了CNN+LSTM网络在视频分析领域的王者地位。毕竟是带着Hinton血脉的文章,所以引用量也是非常高的。