DRL学习第一课: 结构梳理和理清概念
近期在忙一个比较重要的项目, 做到机器人快速避障,正在努力学习和更新中.
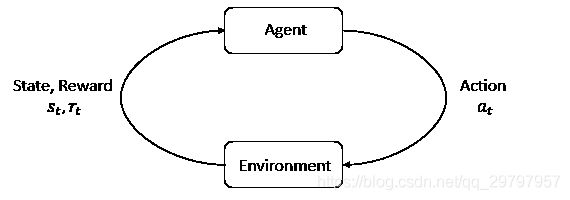
深度强化学习(Deep Reinforcement Learning)
强化学习是机器学习的一个分支, 相较于机器学习经典的有监督学习, 无监督学习问题, 强化学习的最大的特点是在交互中学习(Learning from Interaction).
Agent在与环境的交互中根据获得奖励或惩罚不断的学习知识, 更加适应环境.
RL学习的范式非常类似于我们人类学习知识的过程, 也正因此, RL被视为实现通用AI重要途径.
-
强化学习具体做什么
1. states and observations, 状态和数据观测. 2. action spaces, 执行空间. 3. policies, 执行策略(方法), Deterministic Policies: Stochastic Policies: categorical policies(离散执行空间), diagonal Gaussian policies(连续执行空间). 4. trajectories, 一系列状态和执行空间的组合. 5. different formulations of return, 不同的返回函数公式 6. the RL optimization problem, RL的优化策略 7. and value functions. 优化变量函数 -
强化学习方法简略图
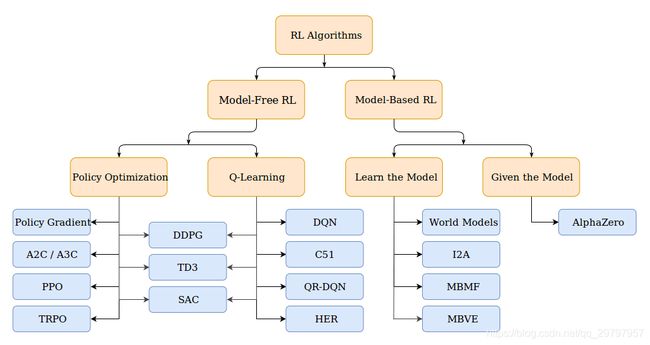
2. 强化学习的要素
"名词解释"
奖励: 单次执行行为的好坏评价标量;
价值函数: 评价一段时间内行为"好坏", 用来预测未来积累的奖励预测;
环境(Model): 用来模拟环境的行为;
智能体(Agent):
"智能体分类1"
基于模型的强化学习.
模型无关的强化学习.
"智能体分类2"
基于价值函数, 无策略
基于策略函数, 无价值
基于Actor-Critic(策略+价值函数).
" 概念扫盲和知识点梳理"
"1. 基本概念"
强化学习:通过从交互中学习来实现目标的计算方法。
交互过程:在每一步t,智能体:获得观察O_t,获得奖励R_t,执行行动A_t,环境:获得行动A_t,给出观察O_{t+1},给出奖励R_{t+1}
历史(History): 是观察、奖励、行动的序列,即一直到时间t为止的所有可观测变量。
状态(State): 是一种用于确定接下来会发生的事情(A,R,O),状态是关于历史的函数。
状态通常是整个环境的, 观察可以理解为是状态的一部分,仅仅是agent可以观察到的那一部分。
策略(Policy): 是学习智能体在特定时间的行为方式。是从状态到行为的映射。
确定性策略: 函数表示,随机策略:条件概率表示
奖励(Reward): 立即感知到什么是好的,一般情况下就是一个标量
价值函数(Value function): 长期而言什么是好的
价值函数是对于未来累计奖励的预测,用于评估给定策略下,状态的好坏
环境的模型(Model):用于模拟环境的行为,预测下一个状态,预测下一个立即奖励(reward)
"2. 强化学习智能体的分类"
model-based RL:模型可以被环境所知道,agent可以直接利用模型执行下一步的动作,而无需与实际环境进行交互学习。
比如:围棋、迷宫
model_free RL:真正意义上的强化学习,环境是黑箱
比如Atari游戏,需要大量的采样
基于价值:没有策略(隐含)、价值函数
基于策略:策略、没有价值函数
Actor-Critic:策略、价值函数
3.强化学习策略paper学习文献
[2] A2C / A3C (Asynchronous Advantage Actor-Critic): Mnih et al, 2016
[3] PPO (Proximal Policy Optimization): Schulman et al, 2017
[4] TRPO (Trust Region Policy Optimization): Schulman et al, 2015
[5] DDPG DDPG (Deep Deterministic Policy Gradient): Lillicrap et al, 2015
[6] TD3 (Twin Delayed DDPG): Fujimoto et al, 2018
[7] SAC (Soft Actor-Critic): Haarnoja et al, 2018
[8] DQN (Deep Q-Networks): Mnih et al, 2013
[9] C51 (Categorical 51-Atom DQN): Bellemare et al, 2017
[10] QR-DQN (Quantile Regression DQN): Dabney et al, 2017
[11] HER (Hindsight Experience Replay): Andrychowicz et al, 2017
[12] World Models : Ha and Schmidhuber, 2018
[13] I2A (Imagination-Augmented Agents): Weber et al, 2017
[14] MBMF (Model-Based RL with Model-Free Fine-Tuning): Nagabandi et al, 2017
[15] MBVE (Model-Based Value Expansion): Feinberg et al, 2018
[16] AlphaZero AlphaZero: Silver et al, 2017