大数据开发之Hadoop篇----hadoop和lzo结合使用
hadoop-lzo
经过我上一篇博文的介绍,大家都知道在我们大数据开发的过程中,其实我们都会对数据进行压缩的,但不同的压缩方式会有不同的效果,今天我来介绍一下lzo这种hadoop原生并不支持的压缩方式的配置和使用,最后我们将跑一次基于lzo的压缩的文件的wordcount。
hadoop支持lzo
由于hadoop原生并不支持lzo,所以即使我们使用了编译版的hadoop好像也不能使用lzo这中压缩方式的。
安装lzop native library
yum -y install lzo-devel zlib-devel gcc autoconf automake libtool
wget www.oberhumer.com/opensource/lzo/download/lzo-2.06.tar.gz
tar -zxf lzo-2.06.tar.gz
cd lzo-2.06
export CFLAGS=-m64
./configure //如果你想指定具体的安装目录的话,可以添加参数–prefix==your_path
make && make install //这个过程要注意权限问题,所以我建议你还是使用root用户来操作
安装maven
这里我就不对maven进行介绍了,这个我们后面要用来编译的
wget mirrors.hust.edu.cn/apache/maven/maven-3/3.5.2/binaries/apache-maven-3.5.2-bin.tar.gz
tar -zxf apache-maven-3.5.2-bin.tar.gz
将maven配置到环境变量当中去,vi ~/.bash_profile 然后进入到编辑模式,输入:
export MAVEN_HOME=your_maven_path
export PATH= M A V E N H O M E / b i n : MAVEN_HOME/bin: MAVENHOME/bin:PATH
然后退出~/.bash_profile,source ~/.bash_profile使其生效
试着在控制台输入mvn -v看看有没有maven的信息输出,输出就对了。
安装hadoop-lzo
wget https://github.com/twitter/hadoop-lzo/archive/master.zip
unzip master
vi hadoop-lzo-master/pom.xml
UTF-8
2.7.4 #这里修改成对应的hadoop版本号
1.0.4
cd hadoop-lzo-master/
export CFLAGS=-m64
export CXXFLAGS=-m64
export C_INCLUDE_PATH=lzo-2.06/include //这里是指定你lzo-2.06的地址里面的include目录,这就是为什么我们要安装配置lzo-2.06的原因了
export LIBRARY_PATH=lzo-2.06/lib //同上
mvn clean package -Dmaven.test.skip=true //使用maven编译
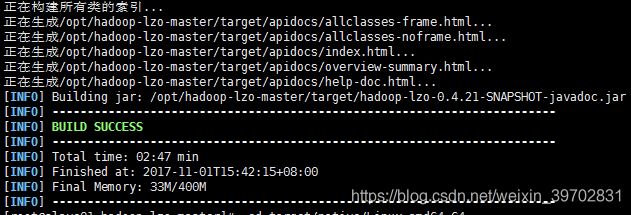
出现这个界面就是对的了
cd target/native/Linux-amd64-64
tar -cBf - -C lib . | tar -xBvf - -C ~
cp ~/libgplcompression* $HADOOP_HOME/lib/native/ //将这个包里面的所有东西都cp到hadoop目录下的lib下的native里面,最好你是编译过的hadoop,否则你的native里面是空的
cp target/hadoop-lzo-0.4.21-SNAPSHOT.jar $HADOOP_HOME/share/hadoop/common/ //这个非常重要,你能否正常使用lzo就看这个了
ls -l /root/libgplcompression.*

修改一下hadoop的配置文件
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh 添加下面的配置参数
export LD_LIBRARY_PATH=lzo-2.06/lib
vi $HADOOP_HOME/etc/hadoop/core-site.xml
io.compression.codecs
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
io.compression.codec.lzo.class
com.hadoop.compression.lzo.LzoCodec
//注意io.compression.codecs的value里面不要有空格,我之前就是因为这个搞得我hive的输出都出错了
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
mapred.child.env
LD_LIBRARY_PATH=/usr/local/lzo-2.06/lib
mapreduce.map.output.compress
true
mapreduce.map.output.compress.codec
com.hadoop.compression.lzo.LzoCodec
重启你hadoop集群
lzop的安装
这个就是lzo压缩解压的工具,你可以使用lzop file 来压缩文件成lzo文件,也可以使用lzop -d file.lzo来解压lzo文件
wget www.lzop.org/download/lzop-1.04.tar.gz
tar zxf lzop-1.04.tar.gz
cd lzop-1.04
/configure
make && make install
配置环境变量
lzop -V

输出这个就够了
测试hadoop上是否支持lzo文件了
上传你的lzo文件到hdfs上面
hdfs dfs -put file.lzo /… //后面那个指的是你HDFS上面的地址
然后text一下,如果能输出内容就是Hadoop支持lzo了
如果还是显示没有找到com.hadoop.compression.lzo.LzoCodec这个东西的话,就是你上面的步骤应该出错了
###来跑一波wc
我上一篇博文说过,lzo一般情况下是不支持分片的,不支持分片就没有了分布式的意义了,所以我们先来看下不支持分片下的lzo的怎么跑的
cd $HADOOP_HOME/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /file.lzo /output_file //最后两个一个是你HDFS上面的lzo文件的放置地址,后面一个是你想将跑完的结果放到HDFS上的那个目录文件夹下,注意这个文件夹不用事先创建的,否则会报错的
仔细看控制台的输出,你会发现无论你文件多大
mapreduce.JobSubmitter: number of splits:1
这里都是1的
建立索引
要建立索引就要用到我们之前的那个jar包了
hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/lib/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.LzoIndexer /your_lzofile_path
hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/lib/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.DistributedLzoIndexer /your_lzofile_path
上面两种方法都可以,第二种快一点,所以会在lzo文件相同的目录下,所以你最好文件你这个要跑的lzo文件单独建一个目录,这个时候目录下有两个文件了,如果再跑一次wc的话,以这个目录为输入那么你将会看到
mapreduce.JobSubmitter: number of splits:2 这个输出了,但不要惊喜,这个时候还是没成功,hadoop只是把lzo和索引文件单独看成两个文件而已,我们还需要一个参数。
完成一次lzo的带索引的wc
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount
-Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTestInputFormat /input /output
就是添加这个参数了:-Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTestInputFormat
好了,这个时候你就会看到你的mapreduce.JobSubmitter: number of splits:是多个了,说明你成果了
####很多小伙伴说你要不使用markdown来写吧,那写在就满足一下你们吧。