数据结构算法面试全解析
你有没有遇到过以下的几种情况:在面试中对于面试官给出的算法题不知道如何下手进行分析;在实际的工作中,不知道如何去选择和使用合适的数据结构,比如说,在查询操作更多的程序中,应该用顺序表还是链表;多个网络下载任务,我该怎么去调度它们去获得网络资源呢?你可能会想到了队列,那针对这个问题用队列怎么实现?如果不用队列,而是使用堆这种数据结构,能否解决这个问题呢?
上面这些问题,在你学好了数据结构之后都可以迎刃而解!
数据结构是计算机中存储以及组织数据的方式,它告诉我们如何把现实问题转化为计算机语言。
在非常多的程序设计过程中,数据结构的选择都是一个最基本的设计考虑因素。许多系统的构造经验表明,系统实现的困难程度和系统构造的质量都严重的依赖于是否选择了最优的数据结构。许多时候,确定了数据结构后,算法就容易得到了。熟练的掌握数据结构可以让你的编程能力有一个质的提升;并且,不管是校招还是社招,数据结构都是面试中必定会重点考察的部分。
数据结构如此重要。因为其本身比较抽象,所以想要系统地掌握还是有难度的。
本专栏系统总结了所有的最常用的数据结构的知识,从这些数据结构的定义、设计方法和操作算法入手带领大家去吃透几个最经典的数据结构。
此外,本专栏为每个数据结构都提供了实际应用案例以及近几年的数据结构相关的笔试面试题目,方便大家从直观上了解这些数据结构的设计理念,从而更好的解决实际工作中的问题以及顺利通过数据结构相关的校招和社招的笔试和面试。
专栏亮点
- 6 大核心数据结构讲解
- 整理了近年来的笔试面试真题,通过对面试中频繁考察的数据结构知识的解析,让你无惧数据结构方面的考察
- 从基础定义到底层原理的解析,让你更能深入理解数据结构
专栏内容
为了帮助大家更好的准备数据结构相关的面试或者更好的掌握数据结构,我们四个计算机行业的开发工程师,在咨询了很多同事和行业同行的基础上,付出了很多心血,最终总结出了这个专栏,来帮助那些正在准备面试或者想系统掌握数据结构知识的朋友们。
针对数据结构设计的知识点广且很多知识点深的特点,我们最终制定了4大模块,基本涵盖了最核心的数据结构知识,跟随我们讲解,让你可以从原理到实战,真正学好数据结构。
专栏主要分为 6 大模块
第一模块:这一模块包含四篇文章,分别对数组内存及数组面试常问算法,单向链表、双向链表和循环链表进行了讲解。并且还有两篇文章专门讲解了面试中常问的链表问题以及如何用双向链表实现LRU淘汰机制算法高阶案例。
第二模块:这一模块包含三篇文章,将带领大家走进栈和队列栈这两个出现频率极高的数据结构。分别讲解了栈和队列的定义以及栈与队列的存储结构与实现,最后讲解了实际工作以及面试考察中中栈与队列的应用。
第三模块:这一模块包含四篇文章,主要聚焦的是排序算法。排序算法千变万化,其很好的体现了数据结构的优美和力量。我们将带领大家分别去了解算法性能衡量的好坏,带大家走进一些基础排序算法,然后会有排序算法进阶,最后带来的是排序算法性能比较与实际应用。
第四模块:这一模块总共包含8篇文章。主要内容是树这一数据结构以及我们自己对整个数据结构专栏的总结。首先我们会带来的是树的基础知识部分,包括二叉树的实现以及存储结构以及二叉树的四大遍历方法;然后,我们会讲述查找树这一经典的树结构,包括二叉查找树以及平衡查找树的介绍,而后,会有一篇文章专门去总结二叉树算法的实战案例。接下来,我们会深入红黑树这一树结构,包括红黑树的实现和性质,同样的,我们也会带来B+,B-树的实现和性质以及B+,B-树的自平衡和使用场景。最后我们会回顾整个专栏,然后做出一个总结以及经验分享。
图例讲解
平衡操作示例:
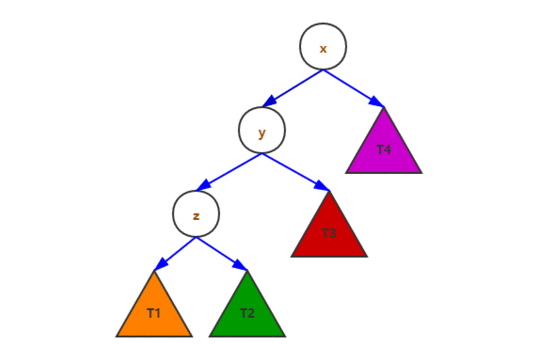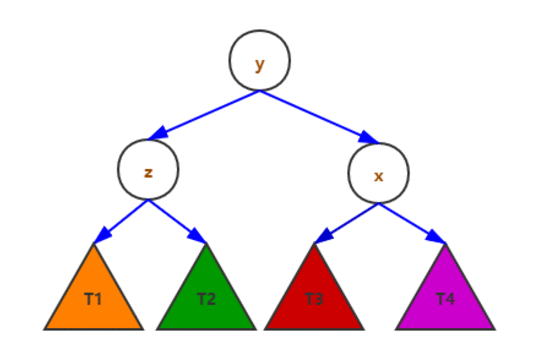
二叉树的查找操作图示:

你将获得什么?
数据结构对于在校学生还是已经工作的职场老司机都非常重要,坊间流传一个经典的加法题:程序 = 数据结构 + 算法。
拥有扎实的数据结构功底才能让你在更加自信地应对找工作时面试官的提问;才能更加自如地解决工作上的问题;才能更加迅速地让你在编程能力上提升一个台阶。
我们相信,对于准备进入计算机这个行业的同学来说,学习本专栏可以让你从一个很好的角度入手,一窥计算机世界的奥妙。
对于正在或者准备找工作的同学来说,学习本专栏可以让你快速且全面的掌握数据结构的重要知识,助力你的笔试和面试。
对于那些有较丰富工作经验的工程师来说,学习本专栏也可以让你回顾并巩固数据结构的知识,提升工作的效率。
适合人群
- 正在准备互联网行业校招或社招面试的的同学
- 想系统了解和掌握数据结构的开发者
作者介绍
我们是四个来自同一家互联网公司的从事不同领域的高级软件工程师以及算法工程师。其中我们从事的工作内容包括不限于消息推送、视频、微服务、安卓音视频算法开发等。
购买须知
- 本专栏为图文内容,共计 18 篇。每周更新 2 篇,预计 8 月中旬更新完结。
- 付费用户可享受文章永久阅读权限。
- 本专栏为虚拟产品,一经付费概不退款,敬请谅解。
- 本专栏可在 GitChat 服务号、App 及网页端 gitbook.cn 上购买,一端购买,多端阅读。
订阅福利
订购本专栏可获得专属海报(在 GitChat 服务号领取),分享专属海报每成功邀请一位好友购买,即可获得 25% 的返现奖励,多邀多得,上不封顶,立即提现。
提现流程:在 GitChat 服务号中点击「我-我的邀请-提现」。
①点击这里跳转至》第 3 篇《翻阅至文末获得入群口令。
②购买本专栏后,服务号会自动弹出入群二维码和暗号。如果你没有收到那就先关注微信服务号「GitChat」,或者加我们的小助手「xiangcode」咨询。
课程内容
崇台九层,起于累土:数组内存及数组面试常问算法全面解析
本章将以 Java 语言为列,深入浅出介绍数组。
此部分主要介绍所有编程语言中基本都会涉及到的数据结构:数组。数组相信大家都会使用,但是当面试过程中闻到涉及到内存分析、数据结构对应的算法时,总会有让你猝不及防的地方,比如数组的内存模型分析?本章主要以 Java 语言为列,以阿里巴巴的面试题为主,围绕以下话题深入浅出进行讲解:
1. 数组结构
首先,什么是数组?数组好比一个“储物空间”,可以有顺序的储存同种类型的“物品”。您可以设定它的大小,也可以设定它存储“物品”的类型。
数组有一维数组,二维数组。实际上数组有点类似于我们数学中的矩阵。
如图:
 图中有两个数组,数组 1 和数组 2。数组的下标从 0 开始,我们可以通过下标来获取数组中存储的元素。例如通过 TCoolNum1[0],可以获取 111,通过 TCoolNum2[2]得到字符串“cool”。
图中有两个数组,数组 1 和数组 2。数组的下标从 0 开始,我们可以通过下标来获取数组中存储的元素。例如通过 TCoolNum1[0],可以获取 111,通过 TCoolNum2[2]得到字符串“cool”。
num1 存储的即为类型为整数的“物品”,其长度为 10,数组 2 存储的类型为字符串的“物品”,数组的长度为 7,虽然该数组只存储了 3 个字符串,但是该数组在声明的时候申请长度为 7 的内存空间,尽管没有全部存储,但是占用的内存空间并不改变。
2. 数组常用方法
2.1 数组的声明和初始化
2.1.1 数组的声明
在程序中必须先声明数组,方可使用数组。
声明方法如下
int[] TCoolNum1;String[] TCoolNum2; //这里定义一个空数组# orint TCoolNum3[];int[] TCoolNum14 = new int[];//同样也是一个空数组注意,这里初始化的数组存储的都是 Java 中的基本数据类型。你也可以申明存储对象的数组,例如:
String[] num2# orString[] num2 = new String[];如果你有一个对象名为 SomeObject,你也可以这样申明:
SomeObject num1[];# orSomeObject[] num2 = new SomeObject[];2.1.2 静态初始化和动态初始化
静态初始化:
int[] TCoolNum5=new int[]{0,1,2,3,4};#orint[] TCoolNum6={1,2,3,4};同学们肯定好奇为什么叫静态的,因为上面的两种方式都是程序员在初始化数组时已经为数组进行了赋值,此时 JVM 会自动识别去数组的长度,并为其分配相应的内存。
既然有静态初始化,那一定有动态初始化:
int[] TCoolNum7 = new int[7]; #向内存空间申请长度为 7 的数组空间如果事先知道你想要存储的数据有多长,可以直接在申明时加上长度,中括号中的 7 即代表数组的长度为 7,而此时我们并未给数组赋值,但是由于数组的类型为 int 型,属于 Java 中的基本类型,故 JVM 会给其赋初始值 0。
**(面试常问)那么我们来计算一下这样一个数组在内存中究竟占了多少内存空间:一个 int 类型占用 4 个字节,我们这里申请了 7 个,即 TcoolNum7 在内存中占用了 47=28 字节的内存。
定义完数组,除了静态初始化时赋值,还可以用这种方式进行赋值:
int[] TCoolNum8=new int[3];TCoolNum8[0]=0;TCoolNum8[1]=1;TCoolNum8[2]=2;2.1.3 多维数组的声明和初始化(以二维数组为例)
多维数组的声明和初始化和一维数组大同小异。代码如下:
int num[][] = new int[3][3];二维数组 a 可以看成一个三行三列的数组。如果面试官问你这样一个数组在内存中占用多少字节,你就可以举一反三了:334(字节)=36 字节,一共占用了 36 个字节。与一维数组类似,也可以以对象进行申明:
SomeObject num[][] = new SomeObject[3][3];这里就不重复表述了。
2.2 数组常用的属性和方法
最常用的自然是 数组名称.length 来获取数组的长度,这个就不多做介绍了。
2.2.1 数组的遍历
除了获取数组的长度,在实际工作中我们经常需要对数组进行的操作就是遍历,给大家介绍两种常用的遍历方式:
int[] TCoolNum9=new int[]{0,1,2,3,4};for (int i :TCoolNum9){ System.out.println(i);}这里我们通过 for 循环,循环的是 TCoolNum9 数组中的每一个值,然后在循环中将每个值打印出来,当然我们也可以根据数组的下标进行循环:
int[] TCoolNum10=new int[]{0,1,2,3,4};for (int i =0;i由于数组的下标永远都是从 0 开始,所以我们定义 i 初始值为 0,通过 TCoolNum10.length 获取数组的长度,得到该数组的下标最大值,进行循环,继而再根据 TCoolNum10[i]的方式打印。这里的打印只是一种操作,你可以在循环里进行增删改查等等操作。
2.2.2 Java.util.Arrays 类
Java.util.Arrays 是 Java 中针对数组操作封装的类,在类中封装了一系列对数组操作的方法,如:
int[] num2 = new int[7]; java.util.Arrays.fill(num2,3); #将数组 num2 填充 int 类型元素 3 int[] num2 = new int[7]; java.util.Arrays.sort(num2); #对数组 num2 进行升序排序 int[] num2 = new int[7]; int[] num1 = new int[7]; java.util.Arrays.equals(num2,num1); # 判断数组中元素是否相等 java.util.Arrays.binarySearch(num2,2); # 采用二分法对排序好的数组 num2 进行查找还有很多,需要大家在实践中学会使用。
2.3 数组的实践
数据结构的创建最终都归于应用。那么数组在编程中有哪些实际的应用呢?
2.3.1 获取数组中的最大值
假设我们有一个数组 TCoolSalary,里面存储的公司所有员工的工资,老板想知道现在公司里谁的工资最高(当然不包括老板哈),如果同学们有一定的基础,就一定知道通过 for 循环依次比较就能获得最大值。
暴力循环代码如下:
public static void main(String[] args){ int[] TCoolSalary ={10,20,3,4,2,6,54,5,45,32,87,92,6,7,5,343,5,45,45,543,365}; int max=0; for (int i=0;i运行结果:

3. 数组的内存解析
Java 中的数组是用来存储同一种数据类型的数据结构,一旦初始化完成,即所占的空间就已固定下来,初始化的过程就是分配对应内存空间的过程。即使某个元素被清空,但其所在空间仍然保留,因此数组长度将不能被改变。
那么数组在内存中如何存储呢?看下图:

4.小试牛刀
4.1 数组实战题:移除元素
题目:
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示列:给定 nums = [3,2,2,3], val = 3,函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。解题思路:
现在考虑数组包含很少的要删除的元素的情况。例如,num=[1,2,3,5,4],Val=4num=[1,2,3,5,4],Val=4。之前的算法会对前四个元素做不必要的复制操作。另一个例子是 num=[4,1,2,3,5],Val=4num=[4,1,2,3,5],Val=4。似乎没有必要将 [1,2,3,5][1,2,3,5] 这几个元素左移一步,因为问题描述中提到元素的顺序可以更改。
算法
当我们遇到 nums[i] = valnums[i]=val 时,我们可以将当前元素与最后一个元素进行交换,并释放最后一个元素。这实际上使数组的大小减少了 1。
请注意,被交换的最后一个元素可能是您想要移除的值。但是不要担心,在下一次迭代中,我们仍然会检查这个元素。
解题代码:
public int removeElement(int[] nums, int val) { int i = 0; int n = nums.length; while (i < n) { if (nums[i] == val) { nums[i] = nums[n - 1]; // reduce array size by one n--; } else { i++; } } return n;}复杂度分析
时间复杂度:$$O(n)$$,$$i$$ 和 $$n$$ 最多遍历 $$n$$ 步。在这个方法中,赋值操作的次数等于要删除的元素的数量。因此,如果要移除的元素很少,效率会更高。
空间复杂度:$$O(1)$$。
4.2 2019 年饿了么秋招真题:搜索插入位置
题目:
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
你可以假设数组中无重复元素。
示例 1:输入: [1,3,5,6], 5输出: 2解题思路:
如果该题目暴力解决的话需要 $$O(n)$$ 的时间复杂度,但是如果二分的话则可以降低到 $$O(logn)$$ 的时间复杂度
- 整体思路和普通的二分查找几乎没有区别,先设定左侧下标 left 和右侧下标 right,再计算中间下标 mid
- 每次根据 nums[mid] 和 target 之间的大小进行判断,相等则直接返回下标,nums[mid] < target 则 left 右移,nums[mid] > target 则 right 左移
- 查找结束如果没有相等值则返回 left,该值为插入位置
时间复杂度:O(logn)O(logn)
- 二分查找的思路不难理解,但是边界条件容易出错,比如 循环结束条件中 left 和 right 的关系,更新 left 和 right 位置时要不要加 1 减 1。
算法
当我们遇到 nums[i] = valnums[i]=val 时,我们可以将当前元素与最后一个元素进行交换,并释放最后一个元素。这实际上使数组的大小减少了 1。
请注意,被交换的最后一个元素可能是您想要移除的值。但是不要担心,在下一次迭代中,我们仍然会检查这个元素。
解题代码:
public int removeElement(int[] nums, int val) { int i = 0; int n = nums.length; while (i < n) { if (nums[i] == val) { nums[i] = nums[n - 1]; // reduce array size by one n--; } else { i++; } } return n;}复杂度分析
时间复杂度:$$O(n)$$,$$i$$ 和 $$n$$ 最多遍历 $$n$$ 步。在这个方法中,赋值操作的次数等于要删除的元素的数量。因此,如果要移除的元素很少,效率会更高。
空间复杂度:$$O(1)$$。
4.3 2019 年今日头条秋招真题:盛最多的水
题目:给定 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
说明:你不能倾斜容器,且 n 的值至少为 2。

解题思路:
首先做题之前我们需要找到每一题存在的规律,本题通过图片不难发现,我们要获得最大区域是由两限度和 X 轴香乘获得,但是受限于两边较短的那个长度,故我们可以总结以下:两线段距离越远,得到的面积就越大,同时线段较短的那个长度越大面积越大。
我们在由线段长度构成的数组中使用两个指针,一个初始化指向数组的下标 0,另一个指向数组的末尾。 每一次我们都会通过计算数组之间下标的长度与两侧线段较短的相乘得到区域面积,通过变量 maxarea 来持续存储到目前为止所获得的最大面积。 并将较短的指针往另一侧移动一步。为什么要移动较短的那个指针呢?因为在循环时,往另一端移动则 x 轴上的距离变短了,如果移动的是较长的指针,则区域面积一定会变小,但是移动较短的指针有可能会使 maxarea 变大,这也是不用遍历所有可能的原因。
解题代码:
public class Solution { public int maxArea(int[] height) { int maxarea = 0, l = 0, r = height.length - 1; while (l < r) { maxarea = Math.max(maxarea, Math.min(height[l], height[r]) * (r - l)); if (height[l] < height[r]) l++; else r--; } return maxarea; }}复杂度分析
时间复杂度:$$O(n)$$,一次扫描。
空间复杂度:$$O(1)$$,使用恒定的空间。
4.4 2019 年百度搜索部秋招真题:两数之和
题目:
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例:
给定 nums = [2, 7, 11, 15], target = 9因为 nums[0] + nums[1] = 2 + 7 = 9所以返回 [0, 1]解题思路:
为了对运行时间复杂度进行优化,我们需要一种更有效的方法来检查数组中是否存在目标元素。如果存在,我们需要找出它的索引。保持数组中的每个元素与其索引相互对应的最好方法是什么?哈希表。
通过以空间换取速度的方式,我们可以将查找时间从 O(n)O(n) 降低到 O(1)O(1)。哈希表正是为此目的而构建的,它支持以 近似 恒定的时间进行快速查找。我用“近似”来描述,是因为一旦出现冲突,查找用时可能会退化到 O(n)O(n)。但只要你仔细地挑选哈希函数,在哈希表中进行查找的用时应当被摊销为 O(1)O(1)。
一个简单的实现使用了两次迭代。在第一次迭代中,我们将每个元素的值和它的索引添加到表中。然后,在第二次迭代中,我们将检查每个元素所对应的目标元素(target - nums[i]target−nums[i])是否存在于表中。注意,该目标元素不能是 nums[i]nums[i] 本身!
解题代码:
class Solution { public int[] twoSum(int[] nums, int target) { Map map = new HashMap<>(); for (int i = 0; i < nums.length; i++) { map.put(nums[i], i); } for (int i = 0; i < nums.length; i++) { int complement = target - nums[i]; if (map.containsKey(complement) && map.get(complement) != i) { return new int[] { i, map.get(complement) }; } } throw new IllegalArgumentException("No two sum solution"); }} 4.5 2019 年百度搜索部秋招真题:三数之和(二数之和进阶版)
题目:
给定一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 $a + b + c = 0 $?找出所有满足条件且不重复的三元组。注意:答案中不可以包含重复的三元组。
示例:
给定数组 nums = [-1, 0, 1, 2, -1, -4],满足要求的三元组集合为:[ [-1, 0, 1], [-1, -1, 2]]解题思路:
首先我们的思路依旧是简化,对于一个无顺序的数组进行升序排序,从小到大排列。我们定义 i,l,r 分别指向数组的第一个值,i 值后面的值和数组最后一个值。以 i++循环遍历,相当于先确定三个数中的一个数 num[i],再加上 num[l],num[r],如果 sum 小于 0,则将 l 向右移动一格;相反,如果 sum>0,则将 r 向左移动一格;如果等于 0,则放入结果集中。最后注意去重就可以了。
解题代码:
class Solution { public static List> threeSum(int[] nums) { List> ans = new ArrayList(); int len = nums.length; if(nums == null || len < 3) return ans; Arrays.sort(nums); // 排序 for (int i = 0; i < len ; i++) { if(nums[i] > 0) break; // 如果当前数字大于 0,则三数之和一定大于 0,所以结束循环 if(i > 0 && nums[i] == nums[i-1]) continue; // 去重 int L = i+1; int R = len-1; while(L < R){ int sum = nums[i] + nums[L] + nums[R]; if(sum == 0){ ans.add(Arrays.asList(nums[i],nums[L],nums[R])); while (L 0) R--; } } return ans; }} 复杂度分析
时间复杂度:$$O(n^2)$$,$$n$$ 为数组长度
5. 小结:
- 数组结构
- 数组常用方法
- 数组的内存解析
- 面试常问数组算法题
6.课后思考:
本章主要介绍了通过程序来实现一个数组的增删改查,那么大家能否根据以上知识通过程序实现找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:输入: [-2,1,-3,4,-1,2,1,-5,4],输出: 6解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。欢迎留言和我分享,我会第一时间给你反馈。
[help me with MathJax]
长风破浪会有时:单向链表、双向链表和循环链表图文解析
链表的种类有很多。我们常常会用到的链表有:单向链表、双向链表和循环链表。
链表不同于数组的地方在于:它的物理存储结构是非连续的,也就是说链表在内存中不是连续的,并且无序。它是通过数据节点的互相指向实现,当前节点除了存储数据,还会存储下一个节点的地址。我们不必在创建时指定链表的长度,因为链表可以无限的插入节点延伸,且插入和删除数据时,其时间复杂度都是 O(1)。
1. 单向链表
1.1 单向链表结构原理
单向链表在结构上有点向火车,你可以从“车厢 1”走至”车厢 2“,看看“车厢 2”里面都装了什么货品,但是如果你已经在“车厢 2”,想看“车厢 1”里的货品,单向链表是不能做到的,咱们继续看图说明:
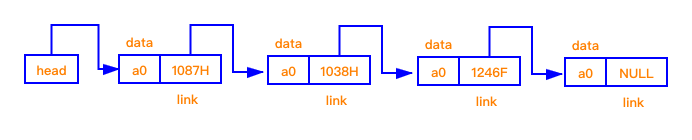
1.2 单向链表 Java 实现
上面介绍了单向链表的结构,接下来用 Java 语言实现单向链表,因为这在面试中常常会让你手写一个链表出来,语言不受限制,理解了就能通用了。
首先我们需要先定义一个 Node 类,该对象代表链表中的一个节点。该对象包含了我们上述所说的 data,data 的类型我们定义成范型,这样定义的好处就是我们往该链表结构中存储任意对象,具有通用性。那么如何让这个 Node1 节点可以指向另一个 Node2 节点呢,很简单,在该 Node1 节点中存储下一个 Node2 节点对象。这样我们就可以通过 Node1 节点获取到 Node2 节点,如此嵌套,就形成了我们所要的链表结构。代码如下:
class Node { //包可见性 Node next; T data; /** * 构造函数 * @auther T-Cool * @description 构造一个新节点 * 新元素与链表结合节点 */ public Node(T data) { this.data = data; } @Override public String toString() { return data.toString(); } } 定义完 Node 节点,让我们再定义一个链表类 LinkedList:
public class LinkedList { class Node { Node next; T data; /** * 构造函数 * @auther T-Cool * @description 构造一个新节点 * 新元素与链表结合节点 */ public Node(T data) { this.data = data; } @Override public String toString() { return data.toString(); } } private Node head; // 链表表头 private int size; // 链表大小 public LinkedList() { head = new Node(null); } public Node getHead() { return head; }} 上述代码链表类 LinkedList 中定义了两个属性:head 是表头,size 代表链表的大小。
两个方法:构造函数和获取头节点的方法。以上就是一个完整的链表结构。说到数据结构那一定会涉及到对其增删改查。
整体的代码如下,方法功能介绍:
- add(E data, int index):向链表中指定位置的元素(0 - size),返回新节点
- add(E data):向链表末尾添加元素,返回新节点
- add(Node node):向链表尾部添加新节点
- remove(int index) :删除链表中指定位置的元素(0 ~ size-1)
- removeDuplicateNodes() :删除链表中的重复元素(外循环 + 内循环)
- getEndK(int k):找出单链表中倒数第 K 个元素(双指针法,相差 K-1 步)
/** * @auther T-Cool * @date 2020/2/12 下午 8:13 * @param */public class LinkedList { class Node { //包可见性 Node next; T data; /** * 构造函数 * * @auther T-Cool * @description 构造一个新节点 * 新元素与链表结合节点 */ public Node(T data) { this.data = data; } @Override public String toString() { return data.toString(); } } private Node head; // 链表表头 private int size; // 链表大小 public LinkedList() { head = new Node(null); } public Node getHead() { return head; } /** * @description 向链表中指定位置的元素(0 - size),返回新节点 * @param data * @param index * @throws Exception */ public Node add(E data, int index) throws Exception { if (index > size) { throw new Exception("超出范围..."); } Node cur = head; for (int i = 0; i < index; i++) { cur = cur.next; } Node node = new Node(data); // 将新元素链入链表 cur.next = node; size++; return node; } /** * @description 向链表末尾添加元素,返回新节点 * @param data * @throws Exception */ public Node add(E data) throws Exception { return add(data, size); } /** * @description 向链表尾部添加新节点 * @param node */ public void add(Node node){ Node cur = head; while(cur.next != null){ cur = cur.next; } cur.next = node; while(node != null){ size ++; node = node.next; } } /** * @description 删除链表中指定位置的元素(0 ~ size-1) * @param index * @return * @throws Exception */ public E remove(int index) throws Exception { if (index > size - 1 || index < 0) { throw new Exception("超出范围..."); } Node cur = head; for (int i = 0; i < index; i++) { cur = cur.next; } Node temp = cur.next; cur.next = temp.next; temp.next = null; size--; return temp.data; } /** * @description 向链表末尾删除元素 * @return * @throws Exception */ public E remove() throws Exception { return remove(size - 1); } /** * @description 删除链表中的重复元素(外循环 + 内循环) * 时间复杂度:O(n^2) */ public void removeDuplicateNodes() { Node cur = head.next; while (cur != null) { // 外循环 Node temp = cur; while (temp != null && temp.next != null) { // 内循环 if (cur.data.equals(temp.next.data)) { Node duplicateNode = temp.next; temp.next = duplicateNode.next; duplicateNode.next = null; size --; } temp = temp.next; } cur = cur.next; } } /** * @description 找出单链表中倒数第 K 个元素(双指针法,相差 K-1 步) * @param k * @return 时间复杂度:O(n) */ public Node getEndK(int k) { Node pre = head.next; Node post = head.next; for (int i = 1; i < k; i++) { // pre 先走 k-1 步 if (pre != null) { pre = pre.next; } } if (pre != null) { // 当 pre 走到链表末端时,post 正好指向倒数第 K 个节点 while (pre != null && pre.next != null) { pre = pre.next; post = post.next; } return post; } return null; } /** * @description 返回链表的长度 * @return */ public int size(){ return size; }} 通过上述代码我们就可以实现对单向链表的一些增删改查的操作了。实际上,在 JDK 中已经为我们封装好了,其实现原理和上面的代码大同小异,有兴趣的同学可以看下 LinkedList 的源码。
2019 阿里秋招面试真题:
这道题是笔者在面试大厂时经常遇到的一个经典算法题,实现方法很多,这里介绍一种性能比较优的解法,大家好好听,好好学:
- 如何判断单链表是否存在环
首先创建两个指针 1 和 2(在 java 里就是两个对象引用),同时指向这个链表的头节点。然后开始一个大循环,在循环体中,让指针 1 每次向下移动一个节点,让指针 2 每次向下移动两个节点,然后比较两个指针指向的节点是否相同。如果相同,则判断出链表有环,如果不同,则继续下一次循环。
public static boolean isLoopList(ListNode head){ ListNode slowPointer, fastPointer; //使用快慢指针,慢指针每次向前一步,快指针每次两步 slowPointer = fastPointer = head; while(fastPointer != null && fastPointer.next != null){ slowPointer = slowPointer.next; fastPointer = fastPointer.next.next; //两指针相遇则有环 if(slowPointer == fastPointer){ return true; } } return false;} - 如何判断两个单链表是否相交,以及相交点
利用有环链表思路.对于两个没有环的链表相交于一节点,则在这个节点之后的所有结点都是两个链表所共有的。如果它们相交,则最后一个结点一定是共有的,则只需要判断最后一个结点是否相同即可。时间复杂度为 O(len1+len2)。对于相交的第一个结点,则可求出两个链表的长度,然后用长的减去短的得到一个差值 K,然后让长的链表先遍历 K 个结点,然后两个链表再开始比较。
2. 双向链表
通过上面一节,我们知道单向链表不能逆向查找,而双向链表结构的出现正是为了解决该缺点。
2.1 双向链表结构原理
双向链表不同于单向链表的地方在于,单向链表只有后继节点的指针域,而双向链表除了有一个后继节点的指针域外,还有有一个前驱指针域。
模型如下图所示:
 顾名思义,前驱指针域存储了当前节点 Node 之前的内存地址,后继节点域存储了后面 Node 的存储地址。
顾名思义,前驱指针域存储了当前节点 Node 之前的内存地址,后继节点域存储了后面 Node 的存储地址。
完整双向链表结构如下图:

2.2 双向链表代码实现
根据上一节单向链表的结构我们稍作改动即可实现双向链表的结构,
代码如下:
class Node{ public T val; public Node next; public Node pre; public Node(T val) { this.val = val; } public void displayCurrentNode() { System.out.print(val + " "); }} 与单向链表代码对比不难发现,双向链表在结构上比单向链表多定义了一个 Node 对象,实现了我们在前面所说的前驱指针域的功能。这里的类型依旧用的范型 T,具有通用性。在实际生产开发环境中,你都应该如此定义。displayCurrentNode 方法用来打印当前节点的值,如果这里存储的是对象,则打印当前对象的内存地址。
相比于单向链表,双向链表灵活之处在于可以用 O(1)的时间复杂度读取前驱节点的值,轻松的对其进行增删改查。
- isEmpty:判断前驱节点是否为空
- addPre:插入前驱节点,通过当前节点获取前驱节点,并赋值
- addNext:插入后继节点
- addBefore:在链表最前面插入新节点
- addAfter:在链表最后面插入新节点
- deleteFre:删除当前节点的前驱节点
- deleteNext:删除当前节点的后继节点
- deleteKey:删除当前节点
- displayForward: 打印当前节点的前驱节点值
- displayBackward:打印当前节点的后继节点值
同时代码中进行了一些备注,方便大家阅读。完整程序见代码块:
import java.io.IOException;/** * @author T-Cool * @date 2020/2/14 下午 12:11 */public class DoublyLinkList{ private Node pre; private Node next; //初始化首尾指针 public DoublyLinkList(){ pre = null; next = null; } public boolean isEmpty(){ return pre == null; } public void addPre(T value){ Node newNode = new Node(value); // 如果链表为空 if(isEmpty()){ //last -> newLink next = newNode; }else { // frist.pre -> newLink pre.pre = newNode; } // newLink -> frist newNode.next = pre; // frist -> newLink pre = newNode; } public void addNext(T value){ Node newNode = new Node(value); // 如果链表为空 if(isEmpty()){ // 表头指针直接指向新节点 pre = newNode; }else { //last 指向的节点指向新节点 next.next = newNode; //新节点的前驱指向 last 指针 newNode.pre = next; } // last 指向新节点 next = newNode; } public boolean addBefore(T key,T value){ Node cur = pre; if(pre.next.val == key){ addPre(value); return true; }else { while (cur.next.val != key) { cur = cur.next; if(cur == null){ return false; } } Node newNode = new Node(value); newNode.next = cur.next; cur.next.pre = newNode; newNode.pre = cur; cur.next = newNode; return true; } } public void addAfter(T key,T value)throws RuntimeException{ Node cur = pre; //经过循环,cur 指针指向指定节点 while(cur.val!=key){ cur = cur.next; // 找不到该节点 if(cur == null){ throw new RuntimeException("Node is not exists"); } } Node newNode = new Node(value); // 如果当前结点是尾节点 if (cur == next){ // 新节点指向 null newNode.next = null; // last 指针指向新节点 next = newNode; }else { //新节点 next 指针,指向当前结点的 next newNode.next = cur.next; //当前结点的前驱指向新节点 cur.next.pre = newNode; } //当前结点的前驱指向当前结点 newNode.pre = cur; //当前结点的后继指向新节点 cur.next = newNode; } public void deleteFre(){ if(pre.next == null){ next = null; }else { pre.next.pre = null; } pre = pre.next; } public void deleteNext(T key){ if(pre.next == null){ pre = null; }else { next.pre.next = null; } next = next.pre; } public void deleteKey(T key)throws RuntimeException{ Node cur = pre; while(cur.val!= key){ cur = cur.next; if(cur == null){ //不存在该节点 throw new RuntimeException("Node is not exists"); } } // 如果 frist 指向的节点 if(cur == pre){ //frist 指针后移 pre = cur.next; }else { //前面节点的后继指向当前节点的后一个节点 cur.pre.next = cur.next; } // 如果当前节点是尾节点 if(cur == next){ // 尾节点的前驱前移 next = cur.pre; }else { //后面节点的前驱指向当前节点的前一个节点 cur.next.pre = cur.pre; } } public T queryPre(T value)throws IOException,RuntimeException{ Node cur = pre; if(pre.val == value){ throw new RuntimeException("Not find "+value+"pre"); } while(cur.next.val!=value){ cur = cur.next; if(cur.next == null){ throw new RuntimeException(value +"pre is not exeist!"); } } return cur.val; } public void displayForward(){ Node cur = pre; while(cur!=null){ cur.displayCurrentNode(); cur = cur.next; } System.out.println(); } public void displayBackward(){ Node cur = next; while(cur!=null){ cur.displayCurrentNode(); cur = cur.pre; } System.out.println(); }} 3.循环链表
3.1 循环链表结构原理
循环链表相对于单向链表是一种特别的链式存储结构。循环链表与单链表很相似,唯一的改变就是将单链表中最后一个结点和头结点相关联,即将最后一个节点的后继指针域指向了头节点,这样整个链表结构就行成了一个环。这样改造的好处是当我们想要获取链表中的某个值时,表中的任何一个结点都能通过循环的方式到达该节点,并获取到该值。让我们看下模型图,如下:
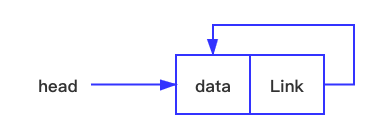 看完图大家应该很容易循环链表,如果是空的循环链表,当前节点的指针域指向自己。如果是非空循环链表,则将 dataN 的指针域指向 data0。如此,循环链表即已实现。
看完图大家应该很容易循环链表,如果是空的循环链表,当前节点的指针域指向自己。如果是非空循环链表,则将 dataN 的指针域指向 data0。如此,循环链表即已实现。
接下来看下用 Java 如何定义一个循环链表。

public Node(Object data){ this.data = data; }}下面的代码块实现了循环列表的增删改查功能,读者可以直接拿来运行哦~```Java/** * @author T-Cool * @date 2020/2/14 下午 3:57 */public class loopLinkedList { public int size; public Node head; /** * 添加元素 * @param obj * @return */ public Node add(Object obj){ Node newNode = new Node(obj); if(size == 0){ head = newNode; head.next = head; }else{ Node target = head; while(target.next!=head){ target = target.next; } target.next = newNode; newNode.next = head; } size++; return newNode; } /** * 在指定位置插入元素 * @return */ public Node insert(int index,Object obj){ if(index >= size){ return null; } Node newNode = new Node(obj); if(index == 0){ newNode.next = head; head = newNode; }else{ Node target = head; Node previous = head; int pos = 0; while(pos != index){ previous = target; target = target.next; pos++; } previous.next = newNode; newNode.next = target; } size++; return newNode; } /** * 删除链表头部元素 * @return */ public Node removeHead(){ if(size > 0){ Node node = head; Node target = head; while(target.next!=head){ target = target.next; } head = head.next; target.next = head; size--; return node; }else{ return null; } } /** * 删除指定位置元素 * @return */ public Node remove(int index){ if(index >= size){ return null; } Node result = head; if(index == 0){ head = head.next; }else{ Node target = head; Node previous = head; int pos = 0; while(pos != index){ previous = target; target = target.next; pos++; } previous.next = target.next; result = target; } size--; return result; } /** * 删除指定元素 * @return */ public Node removeNode(Object obj){ Node target = head; Node previoust = head; if(obj.equals(target.data)){ head = head.next; size--; }else{ while(target.next!=null){ if(obj.equals(target.next.data)){ previoust = target; target = target.next; size--; break; }else{ target = target.next; previoust = previoust.next; } } previoust.next = target.next; } return target; } /** * 返回指定元素 * @return */ public Node findNode(Object obj){ Node target = head; while(target.next!=null){ if(obj.equals(target.data)){ return target; }else{ target = target.next; } } return null; } /** * 输出链表元素 */ public void show(){ if(size > 0){ Node node = head; int length = size; System.out.print("["); while(length > 0){ if(length == 1){ System.out.print(node.data); }else{ System.out.print(node.data+","); } node = node.next; length--; } System.out.println("]"); }else{ System.out.println("[]"); } }}4. 小试牛刀
4.1 2019 爱奇艺秋招面试真题:删除链表的中间节点
题目:
实现一种算法,删除单向链表中间的某个节点(即不是第一个或最后一个节点),假定你只能访问该节点。
示例:输入:单向链表 a->b->c->d->e->f 中的节点 c结果:不返回任何数据,但该链表变为 a->b->d->e->f解题思路:
直接删除下一个结点。表面删除当前节点,实际删除下一个结点。
代码实现:
/** * Definition for singly-linked list. * public class ListNode { * int val; * ListNode next; * ListNode(int x) { val = x; } * } */class Solution { public void deleteNode(ListNode node) { //思路:将下一个结点的值赋给当前节点,当前节点的下一个结点为下下一个结点。 node.val = node.next.val; node.next = node.next.next; }}4.2 2019 阿里巴巴秋招面试真题:如何找出有环链表的入环点?
解题思路:
假设从链表头节点到入环点的距离是 D,链表的环长是 S。那么循环会进行 S 次(为什么是 S 次,有心的同学可以自己揣摩下),可以简单理解为 O(N)。除了两个指针以外,没有使用任何额外存储空间,所以空间复杂度是 O(1)。
代码实现:
public static ListNode findEntranceInLoopList(ListNode head){ ListNode slowPointer, fastPointer; //使用快慢指针,慢指针每次向前一步,快指针每次两步 boolean isLoop = false; slowPointer = fastPointer = head; while(fastPointer != null && fastPointer.next != null){ slowPointer = slowPointer.next; fastPointer = fastPointer.next.next; //两指针相遇则有环 if(slowPointer == fastPointer){ isLoop = true; break; } } //一个指针从链表头开始,一个从相遇点开始,每次一步,再次相遇的点即是入口节点 if(isLoop){ slowPointer = head; while(fastPointer != null && fastPointer.next != null){ //两指针相遇的点即是入口节点 if(slowPointer == fastPointer){ return slowPointer; } slowPointer = slowPointer.next; fastPointer = fastPointer.next; } } return null;} 4.3 美团面试真题 环形单链表约瑟夫问题
题目
输入:一个环形单向链表的头节点 head 和报数 m.
返回:最后生存下来的节点,且这个节点自己组成环形单向链表,其他节点都删除掉。
代码实现:
public static Node josephusKill(Node head, int m) { if(head == null || m < 1) return head; Node last = head; //定位到最后一个节点 while (head.next != last) { head = head.next; } int count = 0; while (head.next != head) { if (++count == m) { head.next = head.next.next; count = 0; } else { head = head.next; } } return head; }4.4 2019 饿了么秋招面试真题:链表相交
题目:
给定两个(单向)链表,判定它们是否相交并返回交点。请注意相交的定义基于节点的引用,而不是基于节点的值。换句话说,如果一个链表的第 k 个节点与另一个链表的第 j 个节点是同一节点(引用完全相同),则这两个链表相交。
示例 1:输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3输出:Reference of the node with value = 8输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。解题思路:
根据题意,两个链表相交的点是指: 两个指针指向的内容相同,则说明该结点记在 A 链表上又在 B 链表上,进而说明 A 和 B 是相交的
而对于相交的情况,两条链表一定是这种结构:

代码实现:
class Solution {public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { ListNode *t1 = headA; ListNode *t2 = headB; while(t1 != t2){ if (t1 == NULL) t1 = headB; else t1 = t1->next; if (t2 == NULL) t2 = headA; else t2 = t2->next; } return t1; }};5.小结
- 单向链表
- 双向链表
- 循环链表
- 小试牛刀
6. 课后思考
本章主要介绍了通过程序来实现不同种类的链表,请运用以上知识判断一个链表是否为回文链表。
示例 1:输入: 1->2输出: false欢迎留言和我分享,我会第一时间给你反馈。
真金不怕火练:如何用双向链表实现LRU淘汰机制算法
明修栈道,暗度陈仓:栈与队列的定义
草船借箭,火烧赤壁:栈与队列的存储结构与实现
万事俱备,只欠东风:栈与队列的应用
尺有所短,寸有所长:算法性能衡量的好坏
柿子先挑软的捏:基础排序算法
进阶硬菜——排序算法进阶
纸上得来终觉浅,绝知此事要躬行——排序算法性能比较与实际应用
千树万树梨花开:二叉树的实现以及存储结构
往来行旅才纷纭:二叉树的四大遍历方法
众里寻他千百度:二叉查找树的优势
轻重在平衡:平衡查找树的强大威力
太极定二仪,清浊始以形:红黑树的实现和性质
芳树千株发:B+,B-树的实现和性质
万家杨柳青烟里:B+,B-树的自平衡和使用场景
一览众山小:专栏总结和我们过往经验分享
阅读全文: http://gitbook.cn/gitchat/column/5f1a9c00dfc48f2858fa9092