Learning with Noisy Label
Learning with Noisy Label
- 学习记录总结
-
- 1.1 阅读背景
- 1.2 理论基础类
-
- 1.2.1 paper: understanding deep learning requires rethinking generalization -- 2017
-
- 论文解读笔记
- 1.2.2 paper: Convexity, Classification, and Risk Bounds
- 1.3 基于概率模型 estimate noisy label
-
- 1.3.1 paper: Training deep neural-networks using a noise adaptation layer -- 2017
-
- 论文算法流程
- 1.3.2 paper: Confident Learning: Estimating Uncertainty in Dataset Labels -- 2019
- 1.4 迭代的学习 (curriculum learning, semi-supervised learning, co-training, self-training)
-
- 1.4.1 paper: MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels -- 2018
-
- 论文解读笔记
学习记录总结
参考:https://zhuanlan.zhihu.com/p/110959020
Learning with Noisy Label
目的:获取解决问题的主要思路,预判未来的主要研究方向。
预期收益:在项目的技术选型、复杂问题的解决时,提供 high level 的可靠输入。
Google Sheets: [PaperReading] Learning with Noisy Labels
pdf 汇总版本:GitHub: Learning with noisy label 论文 pdf 汇总
几篇关于Learning with Noisy Label的论文总结
https://blog.csdn.net/ferriswym/article/details/89452430#t3
1.1 阅读背景
深度学习依赖大量高质量的标注数据 – 时间成本、人力成本都很高。如何用半(弱)监督学习、无监督学习实现与监督学习水平相当的效果,是非常热门研究方向。
这次的 paper reading,聚焦 Learning with noisy label:
- 有一定量的标注数据。-- 通过搜索引擎、公开数据集等,很容易拿到。
- 标注数据的质量不高,存在或高或低的标注错误。
- 不会覆盖无监督类学习。
相比于无监督学习,learning with noisy label 更贴近深度学习在工业界的落地。 典型的状态如下:
- 初始阶段有一定量的标注质量未知的数据。
- 一般会有持续的人工投入,不断提升标注质量。人工投入的形式,可能是付费众包,可能是借助用户反馈。
- 对某些 label、某些错误的关注度,高于其他,需要针对性的优化。
总体观点:不管什么方法,都在回答一个问题:如何区分 clean label 和 noisy label。
- 直接用概率论模型去识别,比如基于 EM 算法的模型、置信学习模型等。
- 根据模型预测的 loss 粗选,反复迭代。
- 隐式的,模型自身对 noise 的容忍度更高。核心思路是改成 weighted sum loss,noisy 的权重低,clean 的权重高。问题转化为如何找 weight。
1.2 理论基础类
1.2.1 paper: understanding deep learning requires rethinking generalization – 2017
- 论文地址:https://arxiv.org/abs/1611.03530
- Chiyuan Zhang, Samy Bengio 2017
Google brain Samy Bengio 提出的观点并用实验证明:Deep neural networks easily fit random labels.这个观点几乎是 2017 年之后 noisy label 相关文章必引观点。这篇文章之前,introduction 都在介绍众包 & 错误不可避免,SOTA 模型表现差。这篇文章之后,理论焦点突出为解决 noisy label 导致的 overfitting。
文章也提出了一个非常有意义的问题:
神经网络的参数量大于训练数据的量,generalization error有的模型好,有的模型差,区别在哪里? Deep neural networks easily fit random labels
泛化误差(Generalization Error)即真实情况下模型的误差。机器学习里的模型一般是针对一个问题设计的,这个问题会有一个数据总体,包括所有可能的情况,比如研究对象是全国人的数据,全国人的数据就是一个总体。模型先经过训练再测试,都需要数据,就分别叫训练数据与测试数据。往往总体数据量很大,甚至是无法穷尽的,所以不可能把所有数据都用到,一般都是从总体里抽取一部分作为代表。模型在测试数据上测试,会得到一个误差,叫测试误差。但其实我们真正想要的是模型在总体上的误差,这就是泛化误差。而测试误差因为采样的关系,与泛化误差是有偏差的。
实验方案:1. 用真实的数据,label 改为随机生成。2. model 使用标准模型,不加任何修改。3. 训练的效果:training error = 0,test error 与随机选的结果相同。
对结果的解释:1. 因为 test label 也是完全随机生成的,无法预测。2. test error 符合预期。
training error = 0,模型参数多,有能力记住所有 dataset 点。3. 随机数据导致模型的 generalization error 明显增加了。
对比试验:1. 基于原始真实数据集,label 不变,image pixel 改成全随机,依旧可以 0 training error 2. 用 random + 原始数据混合测试,random 比例提升,generalization 错误率提升。说明,在 random data 混淆的情况下,依旧有能力学到部分真实特征。3. regularization 能降低 testing error,但对 generalization error 影响不直接。
记住所有 training data 的最小模型 (two-layer ReLU network with p=2n+d parameters can express any labeling of any sample of size n in d dimension.) 2 层的模型,就能记忆全部训练数据。
the role of regularization
三种正则化方式:1. 增加数据,比如图像数据可以通过随机切分图像,给图像的亮度、对比度、色度等增加随机噪声等。2. 权重衰减,比如L2正则化。3. dropout。
regularization is required to ensure small generalization error
论文解读笔记
参考链接:
https://blog.csdn.net/shine19930820/article/details/71158761
https://blog.csdn.net/u014380165/article/details/71188924
1.1 randomization tests
1 . 首先作者做了一个随机测试,训练数据中的真实labels用随机labels代替进行训练,实验结果显示训练误差几乎为0,但是测试误差却不低,因为训练labels和测试labels之间没有关系。这个发现总结为:深度神经网络很容易拟合随机标签,换句话说模型是否有效跟你的标签对错没有太大关系(仅限训练误差)。
论文在CIFAR10和ImageNet分类基准上训练的几种不同的标准体系。简单说明如下观点。
- 神经网络的有效容量足以记住整个数据集。
- 即使对随机标签进行优化仍然很容易。 事实上,与真实标签上的培训相比,培训时间只增加一个小的常数。
- 随机标签只是一个数据转换,使学习问题的所有其他属性不变。
2 . 接下来作者在上一个随机测试的基础上用完全随机的像素点代替原来的真实图像进行训练,发现卷积神经网络依然可以拟合数据且训练误差为0,这说明网络可以拟合随机噪声。进一步,作者在无噪声和有噪声图像之间生成插值图像,加大了图像的随机性,发现随着噪声水平的提升,模型的泛化能力稳定地下降,因为模型虽然可以拟合数据中残留的信息,但同时也在极力拟合噪声。
1.2 the role of explicit regularization
正则化的显式形式,如weight decay, dropout, and data augmentation,没有充分解释神经网络的泛化误差。
文章使用了以下正则化:
- Data augmentation:通过域特定的转换增加训练集。对于图像数据,常用的变换包括随机裁剪,亮度随机扰动,饱和度,色调和对比度。
- Weight decay: equivalent to a L2 regularizer
- Dropout:以给定的dropout概率随机屏蔽各层的每个元素的输出。
不管是显示的还是隐式的正则化方式,如果参数调整合适,那么可以提高网络的泛化能力。但是正则化并不是泛化的必要条件,因为在去掉正则化后网络依然表现良好。 即正则化可能提高了模型的泛化能力,但是没有正则化并不一定意味着泛化误差的提高。
1.3 Finite sample expressivity
有限样本的表达能力:作者通过实验证明即便是只有两层的线性网络也能够很好地表达任何带标签的训练数据。
论文用理论结构补充实验观察结果,表明一般大型神经网络可以表达训练数据的任何标签。展示了一个非常简单的两层ReLU网络,其中p = 2n + d参数可以表示任何尺寸为n的样品的任何标签。也可以使用一个深度k网络,其中每层只有O(n/k)个参数。
1.4 the role of implicit regularization
隐式正则化的作用:在神经网络中,几乎总是选择运行随机梯度下降输出的模型。分析线性模型中,SGD如何作为隐式正则化器。对于线性模型,SGD总是收敛到一个小规模的解决方案。 因此,算法本身将解决方案隐含地规范化。作者认为随机梯度下降(SGD)是一种隐式的正则化。
1.5 related work
这部分作者主要说了两件事,一个是学习算法的uniform stability (一致稳定性)和训练数据的标签是独立的,另一个是泛化能力的界限和网络的大小是独立的。
2.1 fitting random labels and pixels
这是同一个模型在不同设置下的学习曲线:
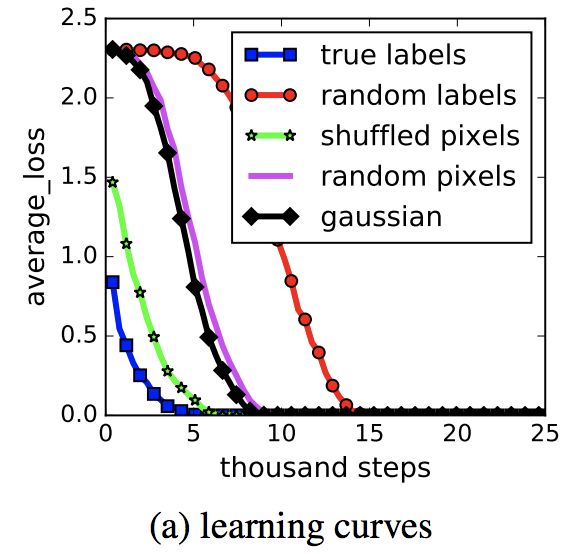
这里注意两种不同的随机pixels方式。shuffled pixels:同一种随机替换方式应用到所有train和test的图像中。random pixels:每张图像都用不同的随机替换方式。random label一开始收敛速度较慢是因为所有的labels都是不正确的,因此一开始的预测误差和更新尺度都较大,但是最终都是可以收敛的。
实验使用一下几种情况:
- 真正的标签:原始数据集没有修改。
- 部分损坏的标签:独立的概率p,每个图像的标签被破坏为一个统一的随机类。
- 随机标签:所有标签都被替换为随机标签。
- 混洗像素:选择像素的随机排列,然后将相同的排列应用于训练和测试集中的所有图像。
- 随机像素:独立地对每个图像应用不同的随机排列。
- 高斯:高斯分布(与原始图像数据集具有匹配均值和方差)用于为每个图像生成随机像素。
这里random labels的top1结果和true labels的差不大多,而且前者的模型参数是直接从后者搬过来的。
这个图显示了不同随机程度的label都不影响模型最后的收敛,差别只在于收敛速度。

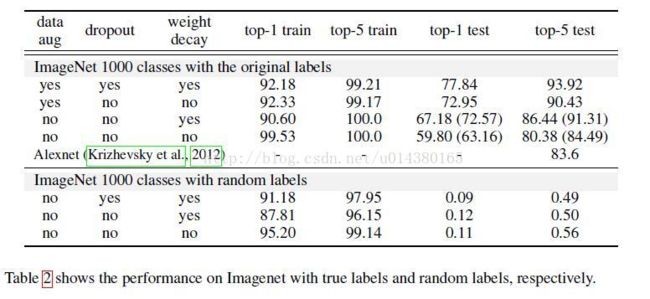
2.2 the role of regularization
这里作者主要讨论三种正则化方式:1. 增加数据,比如图像数据可以通过随机切分图像,给图像的亮度、对比度、色度等增加随机噪声等。2. 权重衰减,比如L2正则化。3. dropout。从这个表可以看出无论是否有正则化,模型的泛化能力变化不大。

另外作者还通过实验比较了early stopping,batch normalization等正则化方式,最后总结如下:不管是显示的还是隐式的正则化方式,如果参数调整合适,那么可以提高网络的泛化能力。但是正则化并不是泛化的必要条件,因为在去掉正则化后网络依然表现良好。
1.2.2 paper: Convexity, Classification, and Risk Bounds
- 论文地址:https://www.stat.berkeley.edu/~jordan/638.pdf
- Bartlett,2006
most loss functions are not completely robust to label noise
1.3 基于概率模型 estimate noisy label
包括 EM-based 模型、置信学习等。
基本的数学模型是:
- noise 与 label 有关,狮子容易被分类成猫,但不容易被分类为轮船。
- 找 noisy label 和 true label 之间联合概率分布矩阵、转移矩阵。
- 用概率矩阵识别 clean label 或 noise label,修正数据集。
1.3.1 paper: Training deep neural-networks using a noise adaptation layer – 2017
- 论文地址:https://openreview.net/references/pdf?id=Sk5qglwSl
- Jacob Goldberger,2017
借鉴通信的信道模型,用 EM 算法。 有点像 NLP 里的 HMM 模型。
建模思路:
- 正确的未知标签可以看作是一个隐藏的随机变量
- 利用未知参数的通信信道对噪声过程进行建模。
用 EM 算法找 network 和 correct label。这个思路 2012,2016 年都有不错的文章发出。
EM算法
- E步(Expectation-step, E-step)
由EM算法的求解目标可知,E步有如下优化问题:
考虑先前的不等关系,这里首先对进行展开:
注意到,推导上式时考虑了:。由贝叶斯定理(Bayes’ theorem),上式可化为:
- M步(Maximization step, M-step)
在E步的基础上,M步求解模型参数使 L(θ,q)取极大值。该极值问题的必要条件是:
式中Eq表示联合似然P(X,Z | θ)对隐分布q(Z)的数学期望。在logP(X,Z | θ)为凸函数时(例如隐变量和观测服从指数族分布),上述推导也是充分的。由此得到M步的计算:
根据以上计算步骤,这里给出一个在Python 3环境使用EM算法求解GMM的编程实现:# 导入模块 import numpy as np import matplotlib.pyplot as plt from scipy.stats import multivariate_normal # 构建测试数据 N = 200; pi1 = np.array([0.6, 0.3, 0.1]) mu1 = np.array([[0,4], [-2,0], [3,-3]]) sigma1 = np.array([[[3,0],[0,0.5]], [[1,0],[0,2]], [[.5,0],[0,.5]]]) gen =[np.random.multivariate_normal(mu, sigma, int(pi*N)) for mu, sigma, pi in zip(mu1, sigma1, pi1)] X = np.concatenate(gen) # 初始化: mu, sigma, pi = 均值, 协方差矩阵, 混合系数 theta = { }; param = { } theta['pi'] = [1/3, 1/3, 1/3] # 均匀初始化 theta['mu'] =np.random.random((3, 2)) # 随机初始化 theta['sigma'] =np.array([np.eye(2)]*3) # 初始化为单位正定矩阵 param['k'] = len(pi1); param['N'] = X.shape[0]; param['dim'] = X.shape[1] # 定义函数 def GMM_component(X, theta, c): ''' 由联合正态分布计算GMM的单个成员 ''' return theta['pi'][c]*multivariate_normal(theta['mu'][c], theta['sigma'][c, ...]).pdf(X) def E_step(theta, param): ''' E步:更新隐变量概率分布q(Z)。 ''' q = np.zeros((param['k'], param['N'])) for i in range(param['k']): q[i, :] = GMM_component(X, theta, i) q /= q.sum(axis=0) return q def M_step(X, q, theta, param): ''' M步:使用q(Z)更新GMM参数。 ''' pi_temp = q.sum(axis=1); pi_temp /= param['N'] # 计算pi mu_temp = q.dot(X); mu_temp /= q.sum(axis=1)[:, None] # 计算mu sigma_temp = np.zeros((param['k'], param['dim'], param['dim'])) for i in range(param['k']): ys = X - mu_temp[i, :] sigma_temp[i] = np.sum(q[i, :, None, None]*np.matmul(ys[..., None], ys[:, None, :]), axis=0) sigma_temp /= np.sum(q, axis=1)[:, None, None] # 计算sigma theta['pi'] = pi_temp; theta['mu'] = mu_temp; theta['sigma'] = sigma_temp return theta def likelihood(X, theta): ''' 计算GMM的对数似然。 ''' ll = 0 for i in range(param['k']): ll += GMM_component(X, theta, i) ll = np.log(ll).sum() return ll def EM_GMM(X, theta, param, eps=1e-5, max_iter=1000): ''' 高斯混合模型的EM算法求解 theta: GMM模型参数; param: 其它系数; eps: 计算精度; max_iter: 最大迭代次数 返回对数似然和参数theta,theta是包含pi、mu、sigma的Python字典 ''' for i in range(max_iter): ll_old = 0 # E-step q = E_step(theta, param) # M-step theta = M_step(X, q, theta, param) ll_new = likelihood(X, theta) if np.abs(ll_new - ll_old) < eps: break; else: ll_old = ll_new return ll_new, theta # EM算法求解GMM,最大迭代次数为1e5 ll, theta2 = EM_GMM(X, theta, param, max_iter=10000) # 由theta计算联合正态分布的概率密度 L = 100; Xlim = [-6, 6]; Ylim = [-6, 6] XGrid, YGrid = np.meshgrid(np.linspace(Xlim[0], Xlim[1], L),np.linspace(Ylim[0], Ylim[1], L)) Xout = np.vstack([XGrid.ravel(),YGrid.ravel()]).T MVN = np.zeros(L*L) for i in range(param['k']): MVN += GMM_component(Xout, theta, i) MVN = MVN.reshape((L, L)) # 绘制结果 plt.plot(X[:, 0], X[:, 1], 'x', c='gray', zorder=1) plt.contour(XGrid, YGrid, MVN, 5, colors=('k',), linewidths=(2,))


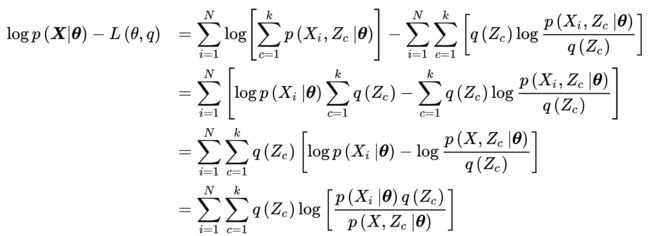




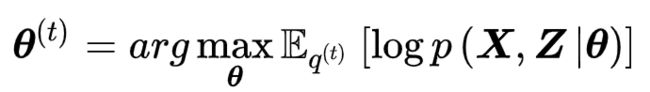
典型的流程如下:
- E-step, estimate the true label
- M-step, retrain the network
缺点是,每次预测完 label 都要重新 train model。 改进的思路是,用 1 个 neural network 端到端的做完 2 步。2014 年 Sukhbaatar & Fergus 提出在最后面加一个 constrained linear layer 连接 correct label and noisy label。在部分有强假设的场景下,可行。
本文的贡献: 把 Sukhbaatar 加的 linear layer 换成 softmax layer,提高了模型的普适性。
作者的观点:
- 改模型可以扩展到 the case where the noise is dependent on both the correct label and the input features.
- 适用于 noisy distribution 未知的数据集。
论文算法流程
参考链接:
https://blog.csdn.net/seamoon201314/article/details/84325027
不准确的标签会严重影响分类器的表现,当观测的标签有噪声时,我们可以把正确的标签认为是一个隐变量,把噪声过程认为是一个未知参数的communication channel。该作者之前使用的方法是EM算法来寻找此未知参数,并且以此来估计正确标签。在这篇文章中作者使用多加的一层神经网络的softmax层来模拟EM算法优化的似然函数。
1 . 在minist数据集上模拟有噪声的标签,选取训练样本的标签,对他们以46%的概率污染,即将其实际的标签翻转为另外一个标签。翻转的矩阵如下:
perm = np.array([7, 9, 0, 4, 2, 1, 3, 5, 6, 8])
意味着原始标签为2的样本有46%的概率被标记为0(矩阵第3列),其他同理。
2 . 在被污染的样本标签作为教师的情况下训练一个神经网络,并且在验证集上测试得到的结果作为baseline,大约是79.45%的准确率。
神经网络是两层简单的全连接层。
nhiddens = [500, 300]
DROPOUT = 0.5
opt = 'adam'
batch_size = 256
patience = 4 # Early stopping patience
epochs = 40 # number of epochs to train on
from keras.models import Sequential
hidden_layers = Sequential(name='hidden')
from keras.layers import Dense, Dropout, Activation
for i, nhidden in enumerate(nhiddens):
hidden_layers.add(Dense(nhidden,
input_shape=(img_size,) if i == 0 else []))
hidden_layers.add(Activation('relu'))
hidden_layers.add(Dropout(DROPOUT))
from keras.layers import Input
train_inputs = Input(shape=(img_size,))
last_hidden = hidden_layers(train_inputs)
baseline_output = Dense(nb_classes, activation='softmax', name='baseline')(
last_hidden)
from keras.models import Model
model = Model(inputs=train_inputs, outputs=baseline_output)
model.compile(loss='sparse_categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
# baseline model performance evaluation before training
def eval(model, y_test=y_test):
return dict(zip(model.metrics_names,
model.evaluate(X_test, y_test, verbose=False)))
print(eval(model))
# ### baseline training
from keras.callbacks import EarlyStopping
train_res = model.fit(X_train_train,
y_train_train,
batch_size=batch_size,
epochs=epochs,
verbose=verbose,
validation_data=(X_train_val,
y_train_val),
callbacks=
[EarlyStopping(patience=patience, mode='min',
verbose=verbose)]
)
# ### baseline performance
print(eval(model))
# build confusion matrix (prediction,noisy_label)
ybaseline_predict = model.predict(X_train, batch_size=batch_size)
ybaseline_predict = np.argmax(ybaseline_predict, axis=-1)
3 . 构造confusion matrix
这是最关键的一步。统计我们的训练教师里比如标签为0的教师的预测的结果是什么样子的分布。对每一个标签做这样的统计。比如标签为0的教师,训练后在预测结果中一大半部分仍为0,但还有不到一半被预测为2。可以在此回头验证我们的标签翻转矩阵,是一致的。

baseline_confusion = np.zeros((nb_classes, nb_classes))
for n, p in zip(y_train_noise, ybaseline_predict):
baseline_confusion[p, n] += 1.
import matplotlib.pyplot as plt
# perm_bias_weights.astype(int)
plt.pcolor(baseline_confusion)
plt.ylabel('true labels')
plt.xlabel('baseline labels')
plt.title('baseline confusion matrix');
4 . 初始化channel层
channel层的目的是用来学习真实标签到有噪声的标签的变化,或者其中的隐藏变量。(我们在模拟噪声时已经知道就是标签翻转矩阵)
channel层是只有100个参数(10*10)的全连接层(10是softmax层输出的变量数)。
第3步创造出混淆矩阵后进行缩小并取对数的调整后作为channel层的初始化参数。
随意的初始化会使该层失去学习的参考,什么都学习不到,自然没有抗噪声的效果。
channel_weights = baseline_confusion.copy()
channel_weights /= channel_weights.sum(axis=1, keepdims=True)
# perm_bias_weights[prediction,noisy_label] = log(P(noisy_label|prediction))
channel_weights = np.log(channel_weights + 1e-8)
5 . 实验结果及总结
这个文章的结果似乎对噪声没啥办法。
本文方法也只能轻微改善一下噪声的抑制结果。
而且噪声模型设置的也难以让人信服。

1.3.2 paper: Confident Learning: Estimating Uncertainty in Dataset Labels – 2019
- 论文地址:https://arxiv.org/abs/1911.00068
- Curtis G. Northcutt,2019
cleanlab 库的算法原理
cleanlab code: https://github.com/cgnorthcutt/cleanlab
假定,noise 只与 true label 有关,与 feature 相互独立。
核心思路:
- 通过 prune, count, rank 3 步可以高效率算出 joint probabilities(true and predicted labels)
- 根据 joint probabilities 识别 label error。
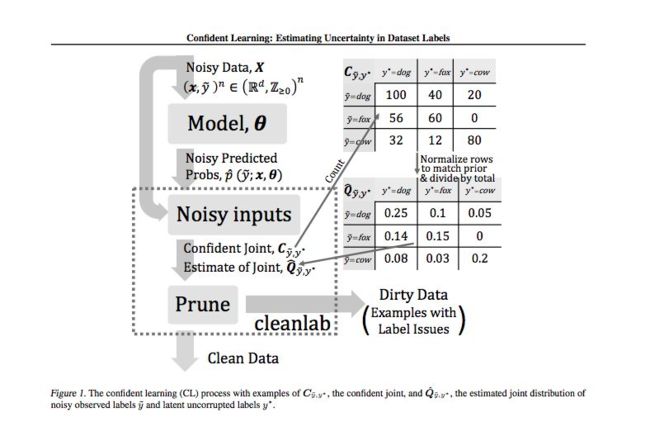
本文的核心贡献: 证明了在现实的充分条件下,通过对标签误差的精确识别,Confident Learning可以准确估计噪声和真实标签的联合分布。
产生Confident Learning的过程是一个模型不可知的理论算法,用于描述、发现和学习错误标签。它利用预测概率和噪声标签对unnormalized confident joint中的实例进行计数,估计联合分布,并对噪声数据进行剪枝,产生clean数据作为输出。
1.4 迭代的学习 (curriculum learning, semi-supervised learning, co-training, self-training)
核心思路:
- 先用大量/全部数据 training 一个 model。
- 根据 loss 等参数,选出大概率为 true 的 label。
- 用 true label 重新或继续 training model。
- 重复 2-3 步。
不同之处在于,curriculum learning 一次把 dataset 分成 N 组,从易到难的训练。其他大方法,大多每次只选出最简单的 1 组。重复 training 的时候,学习的目标能否更复杂(全面)一点,把上一轮学到的参数也纳入新模型的学习目标里。
1.4.1 paper: MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels – 2018
- 论文地址:https://arxiv.org/abs/1712.05055
- Lu Jiang, Li Fei-Fei,2018
- 代码地址: https://github.com/google/mentornet
curriculum learning,课程学习,借鉴人类的学习模式。 按照先容易后复杂的顺序,学习效果更好,学习速度更快。 想象一下,给一个小学生随机丢 100 以内的加法和微积分学习任务。
难点在于,curriculum(课程)怎么选?
最早可以追溯到 Bengio 2009 年提出 curriculum learning。使用 predefined fixed curriculum。
本文的主要贡献:
1 . 自动学习 data-driven 课程。MentorNet 学习 a data-driven curriculum 来监督基础深度网络(StudentNet)。
2 . 根据 StudentNet 的反馈,更新 Curriculum。
论文解读笔记
参考链接:https://blog.csdn.net/qq_25011449/article/details/81560353
1.1 introduction
- 局限性:
对于deep CNNs,我们需要解决现有CL方法的两个局限性。首先,现有的课程通常是预定义的,在培训期间保持固定不变,忽略了学生的反馈。深度网络课程的学习过程是非常复杂的,不能用预先设定的课程来精确建模;其次,交替最小化,通常用于CL和自步学习,需要替换变量更新,这对于通过mini-batch随机梯度下降来训练deep CNNs是很困难的。 - 解决方法:
作者提出了一种通过名为MentorNet的网络从数据中学习课程的方法。MentorNet学习一个数据驱动的课程来监督基础deep CNN,即StudentNet。可以学习MentorNet来近似现有的预定义课程,或者从数据中发现新的数据驱动课程。学习的数据驱动课程可以根据StudentNet的反馈进行几次更新。当MentorNet被学习或更新时,会固定它的参数并与StudentNet一起使用它来最小化学习目标,MentorNet控制学习每个样本的时间和注意力。在测试期间,StudentNet单独进行预测,而不使用MentorNet。 - 改进
该方法从两个方面改进了现有的课程学习。首先,作者定义的课程是从数据中学习的,而不是由人类专家预先定义的。它考虑到学生网的反馈,可以在培训过程中动态调整。直觉上,这类似于一种协作学习模式,课程由老师和学生共同决定。其次,在作者的算法中,使用MentorNet和StudentNet通过小批量随机梯度下降法联合最小化学习目标。因此,该算法可以方便地并行化,在大数据上训练deep CNNs。
1.2 Preliminary on Curriculum Learning
简单总结:目标函数里,有 3 个参数 w, v, lambda。
其中,
- w 就是一般 CNN 要学习的权重。
- lambda 是超参数,表示学习难度。
- v 是 curriculum learning 引入的权重, v_i < lambda, 表示第 i 条数据 “easy”,参与本次训练。
可见,lambda 和 v 共同定义了“课程”。学的过程是:依次固定 v,w,优化另外一个参数。随着学习的进行,逐步调大 lambda,引入越来越多的学习数据。