spring源码系列(四)——beanDefinition(2)
在上一篇文章里面我们讨论了一个beanDefintion对象的重要性,为了讨论spring当中的beanDefinition对象我们不得不牵扯出spring当中的bean工厂后置处理器也就是BeanFactoryPostProcessor这个类;继而讨论了BeanFactoryPostProcessor的大概执行时机(BeanFactoryPostProcessor的执行时机很重要而且spring内部做的稍微有点复杂,本文重点来讨论spring内部怎么保证这些执行时机得以严禁的执行,还有如何来扩展spring的bean工厂后置处理器);首先通过一张图简单的理解一下spring容器启动的时候执行调用BeanFactoryPostProcessor后置处理器的大概的方法执行顺序
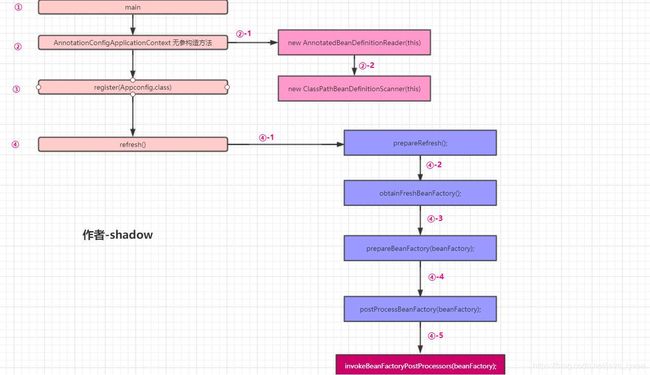
上图大概分为④步(这里只是讨论spring如何调用BeanFactoryPostProcessor,在调用之前到底执行了那些方法,上图并不是spring容器启动的所有步骤)
①启动main方法,在main方法里面调用
②AnnotationConfigApplicationContext的无参构造方法,然后②-1在无参构造方法里面首先实例化AnnotatedBeanDefinitionReader对象,实例化这个对象有两个非常重要的意义。 1、这个对象实例化出来有什么用(问题一) ; 2、实例化这个对象的过程中做了哪些事情(问题二)
所有的
问题X,文章后面再解释,这里先把步骤搞清楚
继而②-2spring又实例化了一个ClassPathBeanDefinitionScanner对象,这个对象顾名思义就是能够用来完成spring的扫描功能,但是这里提一句——spring内部完成扫描功能并不是用的这个对象,而是在扫描的时候又new了一个新的ClassPathBeanDefinitionScanner对象;换言之这里spring new的对象我们假设他为a,但是spring在真正完成扫描的时候又new了一个b,但是是同一个类都是ClassPathBeanDefinitionScanner,但是为什么需要两个? 3、直接用a不就可以了吗?如果spring内部完成扫描时候没用a,那么a被new出来在哪里使用了?(问题三)到此为止第②步完成;
③调用register(Appconfig.class);首先会把Appconfig类解析成为一个beanDefintion对象(如何把一个类解析称为beanDefinition对象的?这里其实涉及到②-1AnnotatedBeanDefinitionReader对象的意义,如果你明白了②-1这里也就明白了),然后给解析出来的beanDefinition对象设置一些默认属性,继而put到beanDefintionMap当中;为什么需要put到beanDefintionMap呢?在上一篇我们已经解释过这个map就是单纯用来存储beanDefinition的,spring后面会遍历这个map根据map当中的beanDefinition来实例化bean,如果Appconfig类的beanDefintion存在在map当中那么他必然会被spring容器实例化称为一个bean?为什么Appconfig会需要实例化呢?因为Appconfig当中有很多加了@Bean的方法,这些方法需要被调用,故而需要实例化,但是Appconfig类的实例化很复杂比一般类实例化过程复杂很多,涉及到代理涉及到cglib等等,这个我们后面文章解释;这里还需要解释一个问题,为什么Appconfig类是通过register(Appconfig.class);手动put到map当中呢?为什么不是扫描出来的呢?(一般类都是通过扫描出来的),其实也很简单,因为他无法扫描自己,一般类是spring通过解析Appconfig上的@ComponentScan注解然后被扫描到,所以无法扫描自己;接下来便是第
④步,④-1到④-4以后分析,④-5便是我们上篇文章说的执行spring当中的bean工厂后置处理器,也是本文重点讨论的;下图是对上述文字的一个说明——spring容器启动的执行顺序
接下来解释上面文字里的所有问题
问题一——AnnotatedBeanDefinitionReader这个对象实例化出来有什么用?
先看一下这个类的javadoc,看看作者怎么来解释这个类的
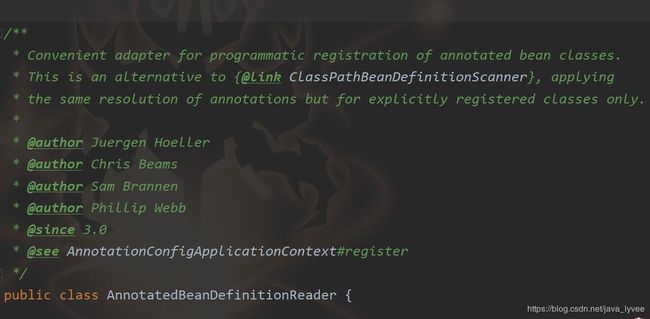
Convenient adapter for programmatic registration of annotated bean
classes. * This is an alternative to {@link
ClassPathBeanDefinitionScanner}, applying * the same resolution of
annotations but for explicitly registered classes only
按照笔者蹩脚的英文水平我的理解是:这个类作用分为以下两个
1、可用于编程式动态注册一个带注解的bean,什么意思呢?比如我们有一个类A存在com.shadow包下面,并且是一个加注解的类。比如加了@Component,正常情况下这个类A一般是被spring扫描出来的,但是有不正常情况,比如spring并没有扫描到com.shadow包,那么类A就无法被容器实例化。有人可能会问为什么没有扫描到com.shadow包?扫描情况下不会扫描到?其实很简单,假设你的这个类是动态生成,在容器实例化的时候不存在那么肯定不存在,再或者这个包下面有N多类但是只有一个类加了注解,那么其实你不需要去扫描,只需要添加这一个加了注解的类即可,再或者一个类是你和第三方系统交互后得到的。那么这个时候我们可以把这个类通过AnnotatedBeanDefinitionReader的register(Class clazz)方法把一个带注解的类注册给spring(这里的注册其实就是上一篇文章中说的把一个类解析成BeanDefintion对象,然后把这个对象put到beanDefinitionMap当中),写个例子来测试一下他的这个注册bean的功能
2、可以代替ClassPathBeanDefinitionScanner这个类,具备相同的注解解析功能, ClassPathBeanDefinitionScanner是spring完成扫描的核心类,这个我后面会分析;简而言之,spring完成扫描主要是依靠ClassPathBeanDefinitionScanner这个类的对象,但是AnnotatedBeanDefinitionReader可以替代他完成相同的注解解析,意思就是通过ClassPathBeanDefinitionScanner扫描出来的类A和通过AnnotatedBeanDefinitionReader显示注册的类A在spring内部会一套相同的解析规则;这点上面那个例子已经证明了。
那么AnnotatedBeanDefinitionReader除了动态显示注册一些spring扫描不到的类之外还有什么功能?在初始化spring容器的过程中他主要干了什么事情呢?或者这么说:假设程序中没有需要动态显示注册的类他就没用了吗?再或者AnnotatedBeanDefinitionReader这个类的对象除了注册一些自己的类还有什么应用场景呢?——注册我们的配置类,对于不理解是什么配置的读者可以理解所谓的配置类就是那个加了@Configuration和@ComponentScan的那个类,也就是Appconfig.java;
那么问题来了,为什么配置类需要手动注册呢?很简单因为配置类无法扫描出来,所以需要我们手动注册。为什么无法扫描呢?比如spring完成扫描是需要解析Appconfig.java当中的@ComponentScan注解的值(一般是一个包名),得到这个值之后去扫描这个值所代表的包下面的所有bean;简单的说就是spring如果想要完成扫描必须先提供Appconfig.java,所以Appconfig.java要在一开始就手动注册给spring,spring得到Appconfig.class之后把他解析成BeanDefintion对象,继而去获取@ComponentScan的值然后才开始扫描其他bean;
总结:AnnotatedBeanDefinitionReader的作用1、主要是可以动态、显示的注册一个bean;2、而且具备解析一个类的功能;和扫描解析一个类的功能相同;AnnotatedBeanDefinitionReader的应用场景1、可以显示、动态注册一个程序员提供的bean;2、在初始化spring容器的过程中他完成了对配置类的注册和解析功能;
针对AnnotatedBeanDefinitionReader应用场景的第2点,我在啰嗦几句,一般程序员在初始化spring容器的时候代码有很多种写法,但都是换汤不换药的,我这里举2个栗子。
第一种写法:
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext();
//动态注册一个配置类
ac.register(Appconfig.class);
//调用refresh方法
//这里很多资料都叫做刷新spring容器
//但是我觉得不合适,这是硬核翻译,比较生硬
//笔者觉得理解为初始化spring容器更加精准
//至于为什么以后慢慢更新再说
ac.refresh();
第二种写法:
AnnotationConfigApplicationContext ac =
new AnnotationConfigApplicationContext(Appconfig.class);
这两种写法都初始化spring容器,代码上的区别无非就是第一种写法是调用AnnotationConfigApplicationContext();的无参构造方法,第二种写法是调用了AnnotationConfigApplicationContext(Class... annotatedClasses)有参构造方法;但是你如果翻阅源码第二种写法的内部也是首先调用无参构造方法的,继而内部继续调用register(Appconfig.class)方法,最后调用refresh();方法,和第一种写法的区别是register和refresh是程序员调用的;笔者更推荐第一种写法,因为第一种写法可以在初始化spring容器之前得到AnnotationConfigApplicationContext的对象也就是代码里面的ac对象;用一张图来说明一下这两种写法的异同
其实第一种方法和第二种方法都可以得到ac对象,那么为什么第一种写法笔者推荐呢?首先第二种方法是在spring容器完成初始化之后的到的ac对象,容器已经初始化了,这个时候得到这个对象能干了事情少了很多;第一种方法在初始化之前得到的,那么能干的事情可多了。①比如我们可以在容器初始化之前动态注册一个自己的bean,就是上文提到的 AnnotatedBeanDefinitionReader的应用场景,②再比如可以利用ac对象来关闭或者开启spring的循环依赖,在笔者的第一篇博客里面也有提到,③还比如程序员可以在容器初始化之前注册自己实例化的BeanDefinition对象。如果你像笔者一样精通spring源码你会发觉提前得到这个ac对象可以做的事情太多了,笔者这里说的三个比如都必须在spring容器初始化之前做才有意义,简而言之就是需要在spring调用refresh方法之间做才有意义;如果你不理解我打个比较污的比方;
假设有机会约到某乔姓网红,无比兴奋之后现在来分析起因和最终结果;起因是她愿意出来和你约会,结果是约会完成最终她还是要回家的。但是过程可以很精彩呀!对比spring的源码起因是你首先成功实例化了一个ac对象(ac成功实例化==你成功约会==new出来的ac对象==约出来的乔姑娘)`,结果是调用ac.refresh()完成初始化spring容器,相当于乔姑娘回家==完成约会;
那么你想一下第一种方式是你成功实例化一个ac对象,在完成初始化之前可以肆意妄为,除了对ac这个对象为所欲为(调用ac的api)之外还可以写任何你自己想写的代码;相当于你成功约到乔姑娘,然后****************你可以拿到她的身份证。但是第二种方式相当于你约到了乔姑娘,但是约会的过程你没办法参与都是姑娘自己安排,她可能和你看完电影之后就告诉你身份证丢了然后各回各家;所以笔者推荐使用第一种方式实例化spring容器。。。。至于原因我已经说的够清楚了。
到此为止已经解释完了问题一——AnnotatedBeanDefinitionReader这个对象实例化出来有什么用?
那么问题二和问题三 下篇文章讨论,为了说清楚spring当中BeanDefintion笔者已经写了两篇博客(根本没有进入BeanDefintion的主题),之前说过会用三篇文章来分析,看来需要食言了,想了一下至少需要五篇才能说清楚