推荐算法-关联规则|R
推荐算法-关联规则
1 概念
关联规则是常见的推荐算法,从发现大量用户行为数据中发现有强关联的规则。
关联规则是一种无监督的机器学习方法,用于知识发现。
优点是能够从大量行为数据中挖掘出无法直接感受到的规则,往往能给出意想不到的规则组合。缺点是难以进行模型评估,一般通过行业经验判断结果是否合理。关联规则最经典的是购物篮分析,啤酒和尿布就是一个经典案例。运用在早期亚马逊、京东、淘宝等购物推荐场景中,往往表现为”买过这本书的人还买了XXX”,”看了这部电影的人还想看XXX”。其推荐结果包含的个性化信息较低,相对简单粗暴。 (别人都买的我就买哦,我不要面子的啊!)
2 常用算法
关联规则中最常用的算法是Apriori,此外还有FP-Growth,Eclat
2.1 基本概念
假设存在规则{A,B}->{C},则称:
{A,B}为前项,记为 LHS(Left Hand Side)
{C}为后项,记为RHS(Right Hand Side)
- 支持度
支持度的计算对象为项集,上例中,{A,B},{C}均为项集。项集支持度,即项集在所有交易中出现的交易数。support(A)=n(A)/N - 置信度(confidence)
置信度的对象是规则,{A}->{B}为一条规则,以该规则为例,其置信度为AB同时出现的次数占B出现的次数比例,即confidence(A->B)=N(AB)/N(B) - 提升度(lift)
规则的提升度在于说明项集{A}和项集{B}之间的独立性,Lift=1说明{A}和{B}相互独立,说明两个条件没有任何关联。如果Lift<1,说明两个事件是互斥的。一般认为Lift>3才是有价值的规则。可以这样理解规则的提升度:将两种物品捆绑销售的结果,比分别销售两种物品的结果提升的倍数。support和confidence都很高的时候,不代表规则很好,通常很可能是Lift很高。计算公式如下:
Lift(A−>B)=support(AB)support(A)support(B) - 频繁项集
支持度大于一定阈值的规则成为频繁项集,这个阈值通常由经验给出,或者通过对数据探索得到。 - 强关联规则
置信度大于一定阈值的频繁项集为强关联规则,阈值通常也是通过经验给出,或通过数据探索得到,可通过不断的尝试和调整确定合适的阈值。
2.2 Apriori算法
Apriori思想的精髓:如果一个项集不是频繁项集,那么它的所有父集都不是频繁项集;一个项集是频繁项集,那么它的子集必然是频繁项集。
2.2.1 算法步骤
Step1:产生频繁项集
1.1找出所有仅包含1个项目的项集,计算支持度
1.2筛选留下满足最小支持度的项集
1.3扩展项集个数,步长为1个,计算项集支持度
1.4 重复1.2
1.5重复以上步骤,至没有可扩展项集,得到频繁项集
Step2:产生关联规则
1.1 获取Step1所有规则的置信度
1.2对比置信度阈值,超过阈值的即为强关联规则
2.2.2 实例解析
原数据如下:
| id | Items |
|---|---|
| 001 | {A,B,C} |
| 002 | {B,C,D} |
| 003 | {C,E} |
| 004 | {D} |
| 005 | {A} |
首先计算最少个数项集的支持度
| Item | Support |
|---|---|
| {A} | 0.4 |
| {B} | 0.4 |
| {C} | 0.6 |
| {D} | 0.4 |
| {E} | 0.2 |
设置Min(Support)=0.3,则项集E被剔除,此后也不再考虑包含{E}的任何组合了。
拓展项集长度,得到如下结果:
| Item | Support |
|---|---|
| {A,B} | 0.2 |
| {A,C} | 0.2 |
| {B,C} | 0.4 |
| {B,D} | 0.2 |
| {C,D} | 0.2 |
MIn(Support)=0.3,则剩下{B,C}组合,由于继续拓展只有{B,C,D},而{B,D}和{C,D}组合已经被舍弃。因此不再拓展。
若其置信度不满足要求,则认为该数据集中没有发现强关联规则。
2.3 FP-Growth算法
补充
2.4 Eclat算法
补充
3 Apriori案例
(1)安装并加载相关的包:
install.packages("arules");library(arules) #规则生成
install.packages("arulesViz");library(arulesViz) #数据可视化
install.packages("RColorBrewer");library(RColorBrewer) #绘图(2)加载数据
arules包可以读取两种格式的数据
A.同一个交易的商品在同一行,以某种分隔符分隔(实际数据文件中不含ID列)
| ID | Itemset |
|---|---|
| 1 | A,B,C |
| 2 | B,C |
读取语句
data=read.transactions("F:/data.txt",format="basket",sep=",")B.以ID标识,一个商品一行
| ID | Item |
|---|---|
| 1 | A |
| 1 | B |
| 1 | C |
| 2 | B |
| 2 | C |
读取语句
data<-read.transactions("F:/data/data.txt",format="single",cols=c("id","item"),sep=",") #cols是必须的本文案例使用的数据是arules包自带的交易数据集Groceries
data(Groceries) #获取数据了解数据情况可以使用以下代码:
summary(Groceries) #数据概况
inspect(Groceries)[1:6,] #打印数据前6行,注意,head()在这里不能打印数据
输出结果可以看到数据集有多少交易记录,涵盖了多少种商品;购买次数最多的是哪些商品;单笔交易购买的商品个数分布;数据标签(这里label是关联规则中的item,level1,level2是商品标签)。
使用arules包可以简单计算出关联规则结果,也可以通过基础变量的计算得到关联规则。
(3)频繁项集生成
A.基于概念计算
itemsize<-size(Groceries)#得到唯一id内购买的item个数
itemF<-itemFrequency(Groceries)#得到每个item的支持度
itemCnt<-(itemF/sum(itemF))/sum(itemsize)#得到item出现次数
itemFrequencyPlot(Groceries,suppory=0.1) #按照支持度直观观测item分布上述计算仅能简单计算和观测单个item的支持度,通过apriori函数能够根据阈值得到关联规则
B.使用apriori函数
rules<-apriori(Groceries,parameter=list(supp=0.006,conf=0.25,minlen=2))
参数解读:
apriori(data,parameter,appearance,control):
*data是经过处理,读取为transactions的数据
*parameter指定为一个list,可设定参数包括,其中,support设定了最小支持度阈值,confidence设定了最小置信度阈值,minlen表示LHS+RHS的最小项目个数,maxlen则是最多个数,target=“rules”为默认值。
注意:minlen=1代表−>A这样的规则成立,因此一般设置minlen=2
详细用法使用help(apriori)可得
rules结果,可以看到满足条件的规则数,supp、conf、lift分布,项集个数分布等信息
> summary(rules)
set of 463 rules
rule length distribution (lhs + rhs):sizes
2 3 4
150 297 16
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.000 2.000 3.000 2.711 3.000 4.000
summary of quality measures:
support confidence lift
Min. :0.006101 Min. :0.2500 Min. :0.9932
1st Qu.:0.007117 1st Qu.:0.2971 1st Qu.:1.6229
Median :0.008744 Median :0.3554 Median :1.9332
Mean :0.011539 Mean :0.3786 Mean :2.0351
3rd Qu.:0.012303 3rd Qu.:0.4495 3rd Qu.:2.3565
Max. :0.074835 Max. :0.6600 Max. :3.9565
mining info:
data ntransactions support confidence
Groceries 9835 0.006 0.25(4)规则结果探索
查看规则、排序
inspect(s_rules[1:6])#查看具体的规则
s_rules<-sort(rules,by="lift") #依据lift排序
s_rules<-sort(rules,by="support") #依据support排序
s_rules<-sort(rules,by="confidence") #依据confidence排序注意,rules是S4类型,不能够实用head()查看
实际运用中,通常是有针对性、直接的的需求,比如想看一些物品有没有存在有关的关联规则,或者某些物品直接是否存在关联,可以通过对rules进行筛选
sample<-subset(rules,item %in% c("fuiit"))
sample<-subset(rules,item %in% c("fuiit") & lift>3)
%in% :精确匹配 item %in% c(“a”,”b”)表示,item=”a” or item =”b”
%pin%: 部分匹配 item %pin% c(“a”,”b”)表示,item like “a” or item like “b”
%ain%:完全匹配:item %ain% c(“a”,”b”)表示,item =”a” and item = “b”
同时可以使用条件运算符(&,|,!)对support、confidence、lift进行过滤
使用subset筛选规则,是同时对LHS和RHS进行检索,如需要针对LHS或RHS筛选,可使用下列语句
> rules_log=subset(rules,lhs %in% "yogurt") #针对LHS筛选,得到的是逻辑变量
> rules_log=subset(rules,rhs %in% "yogurt") #针对RHS筛选
(5)规则可视化
根据支持度、置信度、提升度查看数据分布,可直观感知生成规则的分布,可调整阈值
##需加载扩展包arulesViz
plot(rules) #直接绘制散点图,默认conf、supp为纵轴横轴,lift为颜色深浅
plot(rules,measure=c("support","lift"),shading="conf")#个性化设置
参数解读
*measure 标出了横轴和纵轴基于的变量
*shading代表点的颜色深浅基于的变量
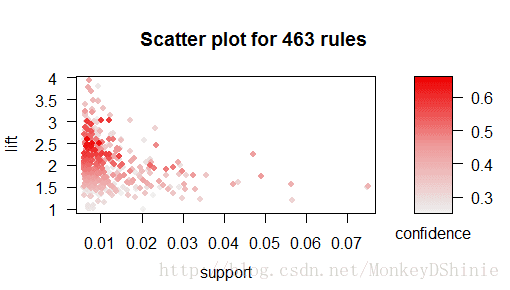
从散点图看,得到的规则聚集在support<0.015,置信度处于(0.45-0.55),lift处于(1.8,2.3)的区域上。受lift极值和support极值的影响,规则的散点分布并不十分明显,可以仅聚集部分规则的散点图
#通过subset筛选规则
plot(subset(rules,support<0.02 & lift<3),measure=c("support","lift"),shading="conf")
筛选了support<0.02其lift<3的规则,并使用散点图展示
plot(rules, shading = "order") #颜色使用项集个数区分
其他可视化形式还有:
#基于分组矩阵,对规则进行聚类
plot(rules, method = "grouped")
个人认为,可理解性较差,不便解读,修改method参数(arulesViz.plot),可以得到更多展现方式。
4 FP-Growth案例
待补充
5 Eclat案例
待补充
By Shinie