COCO数据集格式
一、COCO数据集JSON文件格式
json文件主要包含以下几个字段:
{
"info": info, # dict
"licenses": [license], # list ,内部是dict
"images": [image], # list ,内部是dict
"annotations": [annotation], # list ,内部是dict
"categories": # list ,内部是dict
}
其中info是dict,其中的内容为:
{'description': 'COCO 2017 Dataset', 'url': 'http://cocodataset.org', 'version': '1.0', 'year': 2017, 'contributor': 'COCO Consortium', 'date_created': '2017/09/01'}
可以为空。
其中licenses是list,其中内容为:
[{'url': 'http://creativecommons.org/licenses/by-nc-sa/2.0/', 'id': 1, 'name': 'Attribution-NonCommercial-ShareAlike License'}, {'url': 'http://creativecommons.org/licenses/by-nc/2.0/', 'id': 2, 'name': 'Attribution-NonCommercial License'}, {'url': 'http://creativecommons.org/licenses/by-nc-nd/2.0/', 'id': 3, 'name': 'Attribution-NonCommercial-NoDerivs License'}, {'url': 'http://creativecommons.org/licenses/by/2.0/', 'id': 4, 'name': 'Attribution License'}, {'url': 'http://creativecommons.org/licenses/by-sa/2.0/', 'id': 5, 'name': 'Attribution-ShareAlike License'}, {'url': 'http://creativecommons.org/licenses/by-nd/2.0/', 'id': 6, 'name': 'Attribution-NoDerivs License'}, {'url': 'http://flickr.com/commons/usage/', 'id': 7, 'name': 'No known copyright restrictions'}, {'url': 'http://www.usa.gov/copyright.shtml', 'id': 8, 'name': 'United States Government Work'}]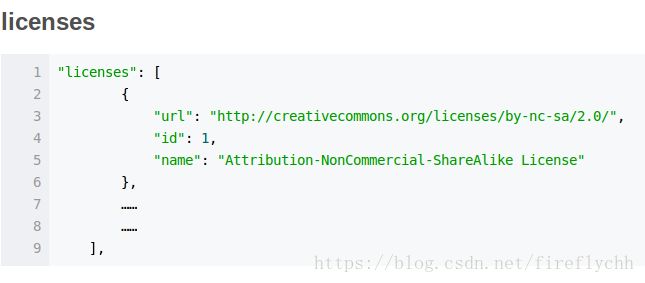
可以为空。
其中images为list,每个list项是一个dict,其中一个图片的内容是:
{'license': 4, 'file_name': '000000397133.jpg', 'coco_url': 'http://images.cocodataset.org/val2017/000000397133.jpg', 'height': 427, 'width': 640, 'date_captured': '2013-11-14 17:02:52', 'flickr_url': 'http://farm7.staticflickr.com/6116/6255196340_da26cf2c9e_z.jpg', 'id': 397133}其中有用的字段包括:id, file_name, height, width,其中id是图片的唯一标识

其中annotations为list,每个list项是一个dict,其中一个图片的内容是:
{'segmentation': [[125.12, 539.69, 140.94, 522.43, 100.67, 496.54, 84.85, 469.21, 73.35, 450.52, 104.99, 342.65, 168.27, 290.88, 179.78, 288, 189.84, 286.56, 191.28, 260.67, 202.79, 240.54, 221.48, 237.66, 248.81, 243.42, 257.44, 256.36, 253.12, 262.11, 253.12, 275.06, 299.15, 233.35, 329.35, 207.46, 355.24, 206.02, 363.87, 206.02, 365.3, 210.34, 373.93, 221.84, 363.87, 226.16, 363.87, 237.66, 350.92, 237.66, 332.22, 234.79, 314.97, 249.17, 271.82, 313.89, 253.12, 326.83, 227.24, 352.72, 214.29, 357.03, 212.85, 372.85, 208.54, 395.87, 228.67, 414.56, 245.93, 421.75, 266.07, 424.63, 276.13, 437.57, 266.07, 450.52, 284.76, 464.9, 286.2, 479.28, 291.96, 489.35, 310.65, 512.36, 284.76, 549.75, 244.49, 522.43, 215.73, 546.88, 199.91, 558.38, 204.22, 565.57, 189.84, 568.45, 184.09, 575.64, 172.58, 578.52, 145.26, 567.01, 117.93, 551.19, 133.75, 532.49]], 'num_keypoints': 10, 'area': 47803.27955, 'iscrowd': 0, 'keypoints': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 142, 309, 1, 177, 320, 2, 191, 398, 2, 237, 317, 2, 233, 426, 2, 306, 233, 2, 92, 452, 2, 123, 468, 2, 0, 0, 0, 251, 469, 2, 0, 0, 0, 162, 551, 2], 'image_id': 425226, 'bbox': [73.35, 206.02, 300.58, 372.5], 'category_id': 1, 'id': 183126}其中有用的字段包括id, image_id, category_id, segmentation, num_keypoints, area, iscrowd, keypoints,bbox。其中id是annotation的id,是annotation的唯一标识,image_id是对应的images的id,一个image可能会有多个annotation,因为每个annotation只是表示一个目标的label。category_id是类别的标识。segmentation是语义分割的label,num_keypoints表示有几个关键点,area表示语义分割的区域大小,iscrowd表示是否是人群,keypoints是表示的关键点,bbox是目标框。不同的数据集包含的label字段不同,比如人体关键点检测就多包含了num_keypoints和keypoints。

其中categories中的内容如下:
[{'supercategory': 'person', 'id': 1, 'name': 'person', 'keypoints': ['nose', 'left_eye', 'right_eye', 'left_ear', 'right_ear', 'left_shoulder', 'right_shoulder', 'left_elbow', 'right_elbow', 'left_wrist', 'right_wrist', 'left_hip', 'right_hip', 'left_knee', 'right_knee', 'left_ankle', 'right_ankle'], 'skeleton': [[16, 14], [14, 12], [17, 15], [15, 13], [12, 13], [6, 12], [7, 13], [6, 7], [6, 8], [7, 9], [8, 10], [9, 11], [2, 3], [1, 2], [1, 3], [2, 4], [3, 5], [4, 6], [5, 7]]}]主要包含内容supercategory, id, name, keypoints, skeleton.

将一个大的json文件生成只有一张图片的json:
from __future__ import print_function
from pycocotools.coco import COCO
import os, sys, zipfile
import urllib.request
import shutil
import numpy as np
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
import json
json_file='/media/fire/d/share_data/datasets/coco/annotations/person_keypoints_val2017.json' #
# Object Instance 类型的标注
# person_keypoints_val2017.json
# Object Keypoint 类型的标注格式
# captions_val2017.json
# Image Caption的标注格式
data=json.load(open(json_file,'r'))
data_2={}
data_2['info']=data['info']
data_2['licenses']=data['licenses']
data_2['images']=[data['images'][0]] # 只提取第一张图片
data_2['categories']=data['categories']
annotation=[] # 通过imgID 找到其所有对象
imgID=data_2['images'][0]['id']
for ann in data['annotations']:
if ann['image_id']==imgID:
annotation.append(ann)
data_2['annotations']=annotation # 保存到新的JSON文件,便于查看数据特点
json.dump(data_2,open('/media/fire/d/share_data/datasets/coco/annotations/test_person_keypoints_val2017.json','w'),indent=4) # indent=4 更加美观显示
二、COCO数据集可视化
from __future__ import print_function
from pycocotools.coco import COCO
import os, sys, zipfile
import urllib.request
import shutil
import numpy as np
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
annFile='/media/fire/d/share_data/datasets/coco/annotations/person_keypoints_val2017.json'
coco=COCO(annFile) # display COCO categories and supercategories
cats = coco.loadCats(coco.getCatIds())
nms=[cat['name'] for cat in cats]
print('COCO categories: \n{}\n'.format(' '.join(nms)))
nms = set([cat['supercategory'] for cat in cats])
print('COCO supercategories: \n{}'.format(' '.join(nms)))
# imgIds = coco.getImgIds(imgIds = [324158])
imgIds = coco.getImgIds()
img = coco.loadImgs(imgIds[0])[0]
dataDir = '/media/fire/d/share_data/datasets/coco'
dataType = 'val2017'
I = io.imread('%s/%s/%s'%(dataDir,dataType,img['file_name']))
#plt.axis('off')
plt.imshow(I)
plt.show()
显示图片:

加载肢体关键点:
catIds=[]
for ann in coco.dataset['annotations']:
if ann['image_id']==imgIds[0]:
catIds.append(ann['category_id'])
plt.imshow(I);
plt.axis('off')
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
print(anns)
coco.showAnns(anns)
plt.imshow(I); plt.axis('off'); plt.show()
加载instances mask:
coco = COCO("/media/fire/d/share_data/datasets/coco/annotations/instances_val2017.json")
img_ids = coco.getImgIds()
print(len(img_ids))
cat_ids = []
for ann in coco.dataset["annotations"]:
if ann["image_id"] == img_ids[0]:
cat_ids.append(ann["category_id"])
ann_ids = coco.getAnnIds(imgIds=img_ids[0], catIds = cat_ids)
ann_ids2 = coco.getAnnIds(imgIds=img_ids[0], catIds = cat_ids)
plt.imshow(I)
print(ann_ids)
print(ann_ids2)
anns = coco.loadAnns(ann_ids)
coco.showAnns(anns)
plt.imshow(I)
plt.show()

三、不同标注数据转换到COCO格式
下面为labelme json格式转到COCO格式。
def image(self,data,num):
image={}
img = utils.img_b64_to_array(data['imageData']) # 解析原图片数据
# img=io.imread(data['imagePath'])
# 通过图片路径打开图片 # img = cv2.imread(data['imagePath'], 0)
height, width = img.shape[:2]
img = None
image['height']=height
image['width'] = width
image['id']=num+1
image['file_name'] = data['imagePath'].split('/')[-1]
self.height=height
self.width=width
return image
def categorie(self,label):
categorie={}
categorie['supercategory'] = label[0]
categorie['id']=len(self.label)+1 # 0 默认为背景
categorie['name'] = label[1]
return categorie
def annotation(self,points,label,num):
annotation={}
annotation['segmentation']=[list(np.asarray(points).flatten())]
annotation['iscrowd'] = 0
annotation['image_id'] = num+1
# annotation['bbox'] = str(self.getbbox(points))
# 使用list保存json文件时报错(不知道为什么)
# list(map(int,a[1:-1].split(','))) a=annotation['bbox'] 使用该方式转成list
annotation['bbox'] = list(map(float,self.getbbox(points)))
annotation['category_id'] = self.getcatid(label)
annotation['id'] = self.annID
return annotation
四、key points数据集的格式
运行脚本one_image_json.py 得到单张图片的JSON信息。
基本上内容与Object Instance的标注格式一样,不同的地方在于categories、annotations字段内容不一样。
{
"info": {
"description": "COCO 2017 Dataset",
"url": "http://cocodataset.org",
"version": "1.0",
"year": 2017,
"contributor": "COCO Consortium",
"date_created": "2017/09/01"
},
"licenses": [
{
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/",
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License"
},
{
"url": "http://creativecommons.org/licenses/by-nc/2.0/",
"id": 2,
"name": "Attribution-NonCommercial License"
},
{
"url": "http://creativecommons.org/licenses/by-nc-nd/2.0/",
"id": 3,
"name": "Attribution-NonCommercial-NoDerivs License"
},
{
"url": "http://creativecommons.org/licenses/by/2.0/",
"id": 4,
"name": "Attribution License"
},
{
"url": "http://creativecommons.org/licenses/by-sa/2.0/",
"id": 5,
"name": "Attribution-ShareAlike License"
},
{
"url": "http://creativecommons.org/licenses/by-nd/2.0/",
"id": 6,
"name": "Attribution-NoDerivs License"
},
{
"url": "http://flickr.com/commons/usage/",
"id": 7,
"name": "No known copyright restrictions"
},
{
"url": "http://www.usa.gov/copyright.shtml",
"id": 8,
"name": "United States Government Work"
}
],
"images": [
{
"license": 4,
"file_name": "000000397133.jpg",
"coco_url": "http://images.cocodataset.org/val2017/000000397133.jpg",
"height": 427,
"width": 640,
"date_captured": "2013-11-14 17:02:52",
"flickr_url": "http://farm7.staticflickr.com/6116/6255196340_da26cf2c9e_z.jpg",
"id": 397133
}
],
"categories": [
{
"supercategory": "person",
"id": 1,
"name": "person",
"keypoints": [
"nose",
"left_eye",
"right_eye",
"left_ear",
"right_ear",
"left_shoulder",
"right_shoulder",
"left_elbow",
"right_elbow",
"left_wrist",
"right_wrist",
"left_hip",
"right_hip",
"left_knee",
"right_knee",
"left_ankle",
"right_ankle"
],
"skeleton": [
[
16,
14
],
[
14,
12
],
[
17,
15
],
[
15,
13
],
[
12,
13
],
[
6,
12
],
[
7,
13
],
[
6,
7
],
[
6,
8
],
[
7,
9
],
[
8,
10
],
[
9,
11
],
[
2,
3
],
[
1,
2
],
[
1,
3
],
[
2,
4
],
[
3,
5
],
[
4,
6
],
[
5,
7
]
]
}
],
"annotations": [
{
"segmentation": [
[
446.71,
70.66,
466.07,
72.89,
471.28,
78.85,
473.51,
88.52,
473.51,
98.2,
462.34,
111.6,
475.74,
126.48,
484.67,
136.16,
494.35,
157.74,
496.58,
174.12,
498.07,
182.31,
485.42,
189.75,
474.25,
189.01,
470.53,
202.4,
475.74,
337.12,
469.04,
347.54,
455.65,
343.08,
450.44,
323.72,
441.5,
255.99,
433.32,
250.04,
406.52,
340.1,
397.59,
344.56,
388.66,
330.42,
408.01,
182.31,
396.85,
186.77,
392.38,
177.84,
389.4,
166.68,
390.89,
147.32,
418.43,
119.04,
434.06,
111.6,
429.6,
98.94,
428.85,
81.08,
441.5,
72.89,
443.74,
69.92
]
],
"num_keypoints": 13,
"area": 17376.91885,
"iscrowd": 0,
"keypoints": [
433,
94,
2,
434,
90,
2,
0,
0,
0,
443,
98,
2,
0,
0,
0,
420,
128,
2,
474,
133,
2,
396,
162,
2,
489,
173,
2,
0,
0,
0,
0,
0,
0,
419,
214,
2,
458,
215,
2,
411,
274,
2,
458,
273,
2,
402,
333,
2,
465,
334,
2
],
"image_id": 397133,
"bbox": [
388.66,
69.92,
109.41,
277.62
],
"category_id": 1,
"id": 200887
},
{
"segmentation": [
[
0.43,
299.58,
2.25,
299.58,
9.05,
287.78,
32.66,
299.13,
39.01,
296.4,
48.09,
290.96,
43.55,
286.87,
62.16,
291.86,
61.25,
286.87,
37.65,
279.15,
18.13,
272.8,
0,
262.81
]
],
"num_keypoints": 1,
"area": 1037.7819,
"iscrowd": 0,
"keypoints": [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
9,
277,
2,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"image_id": 397133,
"bbox": [
0,
262.81,
62.16,
36.77
],
"category_id": 1,
"id": 1218137
}
]
}