这篇随笔的核心是介绍一下YACEP所用到的一些技术,工具,服务和技巧,鉴于篇幅原因,不可能面面俱到,只能点到为止,目录如下:
目录:
1. YACEP简介(上)
2. 技术篇(上)
2.1 利用优先爬山算法解决运算符优先级的问题
2.2 利用ReadOnlySpan加速字符串解析
2.3 利用表达式树和Emit生成表达式执行代理
3. 工具篇(上)
3.1 测试覆盖率工具 - Coverlet
3.2 覆盖率报表转换工具 - ReportGenerator
3.3 基准测试工具 - BenchmarkDotNet
4. 服务篇(下)
4.1 测试覆盖率服务 - Codecov
4.2 代码质量分析服务 - SonarCloud
4.3 持续集成服务1 - Travis CI
4.4 持续集成服务2 - AppVeyor
4.5 持续集成服务3 - Azure DevOps
5. 技巧篇(下)
5.1 利用props文件抽离csproj的公共配置
5.2 利用WSL跨平台测试代码
5.3 利用持续集成服务检查PR
5.4 更易写的文档格式 - AsciiDoc
5.5 如何给你的项目添加更多的徽章
5.6 利用git message自动发布NuGet包
1. YACEP 简介
YACEP : yet another csharp expression parser,是一款基于netstandard2.0构建的轻量级高性能表达式解析器。能够将一段有效的字符串并转换成一棵抽象语法树,同时可以把抽象语法树转换成一段可以执行的代码。
项目使用MIT开源协议,代码托管在GitHub上,更多更详细的信息可以去看官方文档,随便给个star什么的就再好不过了:)
YACEP 的核心是一个轻量级的表达式解析器,其解析代码不到500行,算上辅助的一些操作,整个解析器代码不到600行。解析器内部使用了 ReadOnlySpan 来处理字符串,所以在做长串处理时,内存消耗可以做到很低,处理起来也非常快。
YACEP 还附加实现了一个简单编译器,可以将抽象语法树转换成可执行代码。编译器的接口申明了两个方法,一个不带泛型参数,一个带了泛型参数。所以在 YACEP 的内部编译器的实现有两个,第一个是不做运行时类型绑定的实现,一个是限定运行时类型绑定的实现。前者有更好的灵活性,有类似Python这种语言的动态能力,所以无法在编译完成时生成更优化的IL指令,性能一般。而后者是在编译时就已经限定了具体的类型,所以能够生成更短的IL指令,性能相对于第一种有非常大的提升。
1 public interface ICompiler 2 { 3 ///不做运行时类型绑定 4 IEvaluator Compile(EvaluableExpression expression); 5 ///做运行时类型绑定 6 IEvaluatorCompile (EvaluableExpression expression); 7 }
YACEP 具体的其它特性可以去 GitHub 上查看,这里就直接从官方复制过来,如下:
- 开箱即用,内置了的字面值, 一元及二元操作符以及统计类与时间类函数可满足大部分使用场景
- 跨平台,基于netstandard2.0标准构建
- 轻量级,只有500多行代码实现的轻量级词法分析器
- 低消耗,词法分析器使用 ReadOnlySpan 解析字符串
- 高性能,使用EMIT技术生成IL来构建可执行对象(查看基准测试报告)
- 支持条件表达式
- 支持索引器
- 支持 in 表达式
- 支持自定义字面量
- 支持自定义一元操作符
- 支持自定义二元操作符
- 支持自定义函数
2.技术篇
2.1 利用优先爬山算法解决运算符优先级的问题
优先爬山算法是一种深度优先的算法,它采用启发式的方式进行局部择优。现在的很多人工智能技术也有用到此算法。(后简称爬山算法)
更详细的介绍请点击此链接:https://en.wikibooks.org/wiki/Algorithms/Hill_Climbing
当前有很多种算法可以解决运算符优先级的问题,比如调度场算法,递归下降算法,移进归约算法等。
那为什么YACEP 会选用优先爬山算法呢?
因为爬山算法是我看过众多的算法中,理解起来是最快的。下面讲解一下这个算法的大致思路。
在开始之前我需要先回忆一下小学学到的数学知识,四则运算法则和结合律。
四则运算法则告诉我们当一个式子有加减乘除的时候,先算乘除后算加减,这个是一个原则,很好理解,照着做就成。
结合律就稍复杂一点了,结合律是说在一个包含有二个以上的可结合运算子的表示式,只要算子的位置没有改变,其运算的顺序就不会对运算出来的值有影响。看不懂是吧,换一种说法就是:
( a + b ) + c = a + ( b + c )
a, b的和 再与c求和的值 一定 等于 a与 b, c的和 求和的值。请务必按照这个断句读,否则有点拗口。
如果读完还不知道啥意思,可以回小学去捶一顿你们的体育老师了。
好了,有了上面的知识储备,我们开始研究如下数学表达式:
a + b * c * d + e
按照四则运算法则: 先乘除后加减,对于上述表达式,我们标记一下运算的优先级
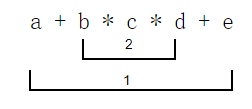 再按照结合律,对于更高优先级的乘法,在求 a*b*c 的值的时候,我们无所谓先算 a*b 再用这个结果去乘c,还是先算b*c再去乘a。按照当前主流的文字阅读规则,我们选择从左往右,即先算b*c,然后拿到这个结果再乘d。我们将b*c的结果存储为m,于是上述表达式可以简化为:
再按照结合律,对于更高优先级的乘法,在求 a*b*c 的值的时候,我们无所谓先算 a*b 再用这个结果去乘c,还是先算b*c再去乘a。按照当前主流的文字阅读规则,我们选择从左往右,即先算b*c,然后拿到这个结果再乘d。我们将b*c的结果存储为m,于是上述表达式可以简化为:
// m = b * c a + m * d + e
再继续,我们将m*d的结果存储为n,于是上述表达式再次简化为:
// m = b * c // n = m * d a + n + e
再次按照结合律,我们将a+n的结果存储为x, 于是上述表达式还可简化为:
// m = b * c // n = m * d // x = a + n x + e
到这一步只要求x+e的结果就好了,把前面的步骤合并在一起。
a + b * c * d + e ----- m --------- n --------------- x ----------------------
去掉字符,我们把下面的虚线连接起来,大概是这样:
山顶 / ----- \ / \ / --------- \ / \ / ------------- \ / \ / ----------------- \
这就是传说中的爬山算法!!!
是不是超好懂!!!
10秒钟读懂了爬山算法!!!

其实怎么说呢,理解到这一步基本就离理解完整的爬山算法差的没几百步了。总共也就几百步,你再走几百步就完全理解了,加油,我们继续。
按照上述的步骤,我们现在开始理解算法的流程。我们将表达式中的元素分为两类,一类我们叫原子值,比如上面表达式中的a、b、c、d、e,另一类我们叫他们为运算符,比如+和*。对于带括号的表达式,我们可以称其为子表达式,也是一种表达式,所以我们总是可以将任何一个表达式拆解为只包含原子值或运算符的表达式(对于一个不包含运算符的表达式,直接拿值就完了)。
基于上述的分类,我们开始描述一下爬山算法的运算步骤:
1. 读取当前一个原子值和它最邻近的运算符
2. 读取下一个原子值和它最邻近的运算符
3. 如果步骤1中的运算符的优先级大于步骤2中的优先级,则算法返回当前原子值,当前原子值最邻近运算符与下一个原子值的子表达式
4. 否则,从步骤2开始构建新的子表达式继续按照上述步骤处理
回到表达式:
a + b * c * d + e
现在按照爬山算法开始处理这个表达式:
- 读到原子值a以及优先级为1的运算符+, a +
- 读取下一个原子值b以及优先级为2的运算符*, b *
- 优先级2大于1,所以我们开始从b开始构建子表达式
- 读取下一个原子值c以及优先级为2的运算符*, c *
- 当前的子表达式的 b * 优先级是2(,新读到 c * 的优先级也是2,得到新表达式 b * c * , 优先级是2。上面的步骤的值 m *
- 读取下一个表达式 d + , +的优先级是1,所以整个子表达式返回值为 m * d ,这两步需要理解结合律。上面的值 n +
- 子表达式已经处理完成,退出子表达式的处理流程,当前的表达式为的优先级为步骤1中, a +
- 下一个表达式为 n + ,两者的优先级都是1,返回子串 a + n 上面的值 x +
- 下一个表达式为 e ,直接返回
- 得到最终表达式 x + e
回到之前我们得到的那座山,再看看这个步骤,你会发现这个流程还真的就是在爬这座山 。
山顶 / ----- \ / \ / --------- \ / \ / ------------- \ / \ / ----------------- \
2.2 利用ReadOnlySpan加速字符串解析
C#中String对象是一个只读对象,一旦创建将不可更改。所以C#中对String对象做更改的方法底层都会创建一个新的String对象。比如在如下代码中:
1 unsafe 2 { 3 var random = new Random(); 4 var str = ""; 5 for (int i = 0; i <= 5; i++) 6 { 7 str += Convert.ToChar(random.Next('A', 'Z')); 8 fixed (char* p = str) 9 Console.WriteLine((int)p); 10 } 11 Console.WriteLine(str); 12 }
上述的代码是在做字符串修改,你可能会觉得这种修改返回一个新值没问题。
但是下面的这种情况对于解析器来说就是一种致命伤了。在截取字符串时,你会发现每一次值都是不一样的,纵使你截取的位置是相同的,Substring始终如一的返回一个新对象给你。
1 unsafe 2 { 3 var str = "123456"; 4 fixed (char* p = str) 5 Console.WriteLine((int)p); 6 fixed (char* p = str.Substring(1, 2)) 7 Console.WriteLine((int)p); 8 fixed (char* p = str.Substring(1, 2)) 9 Console.WriteLine((int)p); 10 Console.WriteLine(str); 11 }
对解析过程而言,可能会有频繁截串的场景,比如随时都可能要将表达式中的一段数字转换为一个数值。这种情况,每次都返回一个新的字符串对象,无论性能还是内存都是难以接受的。
你可能有想到C#中的StringBuilder对象,它确实是维护一个缓冲区,可以在做字符串修改的时候保证始终如一的使用同一块地址,但是这玩意是用来构建字符串的,读取字符串这货不行的,所以你看官方连个Substring都不给你。
难道必须使用非托管代码了么?为了保证更快的内存读取以及更低的内存消耗,难道我要去PInvoke???

这种问题,微软的码农肯定已经意识到了,不然这部分的随笔。。。我怎么写下去。
微软提供了System.Memory程序集用来帮助我们更方便也更安全的操作内存。
我们可以使用ReadOnlySpan来解决上述问题。
ReadOnlySpan在程序集System.Memory中,是Span的只读表示。将字符串转换为一个ReadOnlySpan对象,接着使用ReadOnlySpan来处理字符串,那么上述的问题都可以被解决。
然后大致说一下Span,Span可以用于表达任何一段连续内存空间,无论是数组,非托管指针,可获取到指针值的托管内存等等等等(是不是回忆起当初被指针支配的恐惧感),其实在它内部的实现就是一个指针。相对于C/C++里面的指针需要各种小心翼翼,不敢有一丝怠慢忘记释放,或访问到离奇的地址,或因为各种原因变成野指针。Span会在内部维护这个指针的地址,在做指针运算时,会做边界检查,在更新引用时,垃圾回收器也能判断出该如何回收内存。
对于Span的解读,推荐阅读下面这个系列,作者的解读非常赞。现在愿意写博文讲清 What、How 和 Why的博主不多了,且读且珍惜。
https://www.cnblogs.com/justmine/p/10006621.html
2.3 利用表达式树和Emit生成表达式执行代理
动态生成代理是一个古老的话题。最开始是因为大家都觉得.NET自带的那个反射操作太慢,怎么说呢,其实对于大部分场景是够用的,某知名大佬说:
每每看人在谈论代码时,都说那反射操作是极慢的,万万不可取。
在我自己,却认为反射之慢不过毫秒。
用不正当的思路写出的代码才会引起真正的慢。
-- 树人Groot

之所以会成为一个古老的话题,是因为动态生成代理会出现在太多的业务场景中。
最常见的就是快速获取一个对象指定名称的成员值,你会看到各色爱写库爱造轮子的大佬非常热衷去搞的个快速对象访问器什么的。
多年前博客园大佬赵姐夫还参与过此事写过一个库,地址如下:
http://blog.zhaojie.me/2009/02/fast-reflection-library.html
注:虽然老赵已经很久没有更新博客了,但是他的博客还是非常推荐去阅读一下,内容很丰富,干货特别多。
博客地址:http://blog.zhaojie.me
好了,回过头来。现在对使用动态生成代理的场景做一个汇总,常出现的场景如下:
- 对象序列化反序列化,这种场景多出现于RPC中,代理要把stream转换为object
- 实现ORM,代理要把reader转换为object(这种其实也是rpc)
- 实现AOP,代理要为具体类生成一个包含一系列切面函数的类
- 绑定求值,比如模板渲染或YACEP这种对编译结果调用执行获取结果的过程
动态生成代理实现方式有如下四种:
- 利用Expression构造代理方法
- DynamicMethod生成动态函数构造代理方法
- DynamicAssembly构建代理类
- 利用CodeDom动态生成程序集,生成代理
下面大致对上面的四种方式做一个比较
| Expression | DynamicMethod | DynamicAssembly | CodeDom | |
| 优点 | 实现的代码简单易读 |
原生支持绕过CLR访问修饰符检查 | 支持生成类型 | 支持生成类型 |
| 缺点 | 不支持生成类型 | 需要对IL指令有一定了解 | 需要对IL指令有一定了解 | 代码臃肿 |
| 适用场景 | 逻辑稍简单的代理 | 逻辑稍简单的代理 | 功能更完备的代理 | 处理模板化的代码 |
YACEP在定义可执行对象时, 没有使用.NET内置的委托,而是定义了两个接口。
public interface IEvaluator { object Evaluate(object state); } public interface IEvaluator<in TState> { object Evaluate(TState state); }
那为什么使用接口而不是用委托来定义可执行对象,委托才更符合对可执行对象表述的直觉啊 ?
这是因为YACEP需要支持自定义字面量,自定义函数。
如果生成的是委托,最佳的做法是生成闭包函数,在闭包中保存这些自定义字面量和函数,用EMIT生成一个返回闭包函数的函数。
这种做法确实可以做到,问题是写出来的EMIT代码会更多,更难调试和定位错误,如何知道是函数的闭包问题还是函数自身问题呢。
那如果不用EMIT的方式生成委托,还可以使用表达式树。是的,表达式树在这个方面处理起来比EMIT更有优势,代码可读性更好。而且使用表达式树还有个巨大的优势,YACEP编译的本质其实是将YACEP自定义的抽象语法树转换为C#抽象语法树,表达式树所定义的抽象语法树几乎和YACEP自定义的抽象语法树是一比一的,这种转换要比生成IL更简单。
那为什么YACEP不使用表达式树呢?
在实现YACEP的编译过程时,我会先脑补出抽象语法树转换出的IL代码,然后是最终的C#代码。如何检验YACEP生成的结果与我脑补的结果是一致呢?
如果使用表达式树,我需要debug看表达式树的树结构。如果时间允许,我倒是十分愿意去做这样的事情,可惜YACEP只是我换工作间隙拿来练手的小玩意。EMIT支持生成动态程序集,然后再用ILSpy去检查生成IL代码是否符合我预期,读生成的DLL代码可是比去看表达式树的树结构来的简单。
所以最终在YACEP的代码里,你可以看到即有表达式树的代码也有EMIT的代码。按照上表的适用场景,表达式树用于在处理按照给你名称获取或设置对象成员值,EMIT为表达式生成最终的执行代理。
3. 工具篇
3.1 测试覆盖率工具 - Coverlet
测试覆盖率是啥就不解释了。YACEP使用xUnit.net做单元测试,在当前以及未来可能的版本中,YACEP始终要求100%的行覆盖率,99%以上的分支覆盖率。
如何做测试覆盖率统计?
目前 Visual Studio是支持查看测试覆盖率的,如果安装了JetBrains的dotCover插件,可以获得更好的体验(要钱的)。
这些是用来看测试覆盖率的,如何搞到测试覆盖率报表呢?
dotnet在跑测试时,可以通过配置数据收集器来生成测试覆盖率报告(更详细配置文档),示例命令如下:
dotnet test --collect:"Code Coverage"
在项目中运行此命令,就会生成一个*.coverage的文件在TestResults文件夹里面。
哒哒哒哒!我来打开这个文件,看看我的覆盖率是不是已经100%了呢!
二进制的,还是专属文件格式???
没事,兴许在命令的执行结果里面能找到覆盖率的值!
Microsoft (R) Test Execution Command Line Tool Version 16.0.1
Copyright (c) Microsoft Corporation. All rights reserved.
Starting test execution, please wait...
Total tests: 80. Passed: 80. Failed: 0. Skipped: 0.
Test Run Successful.
Test execution time: 4.4614 Seconds
嗯!
报告很简洁嘛!
我想要的覆盖率呢,到底是个啥数啊!!!
二进制文件非得软件开,我特么VSCode用户啊!!!
命令行执行过程就说跑了多少测试 ,我特么写了多少测试我自己不清楚么!!!

那有没有啥工具可以生成不需要特定软件才能打开的覆盖率报告,还能在我跑test命令的时候直白的告诉我到底覆盖了多少代码呢?
要是还能支持一下VSCode就更好了!!!
没有的,别想了,乖乖回去写代码,不要有非分之想!
非分之想是个好东西!
你都不非分一下,咋知道是不是真的没有!
Coverlet - https://github.com/tonerdo/coverlet
官方介绍是这么写的!
Coverlet is a cross platform code coverage library for .NET Core, with support for line, branch and method coverage.
好像可以尝试一下的样子啊!
安装.net core global tool
dotnet tool install --global coverlet.console
添加依赖到测试项目中
dotnet add package coverlet.msbuild
带着漠视整个世界的感情开始执行测试
dotnet test ./tests/TupacAmaru.Yacep.Test/TupacAmaru.Yacep.Test.csproj ^
/p:CollectCoverage=true ^
/p:Exclude=\"[xunit.*]*,[TupacAmaru.Yacep.Test*]*\"^
/p:CoverletOutputFormat=\"lcov,opencover\" ^
/p:CoverletOutput=./../../results/coverage/
看输出,好像比之前的输出多出了一些不得了的东西啊
Calculating coverage result... Generating report '.\..\..\results\coverage\coverage.info' Generating report '.\..\..\results\coverage\coverage.opencover.xml' +------------------+------+--------+--------+ | Module | Line | Branch | Method | +------------------+------+--------+--------+ | TupacAmaru.Yacep | 100% | 98.9% | 100% | +------------------+------+--------+--------+ +---------+------+--------+--------+ | | Line | Branch | Method | +---------+------+--------+--------+ | Total | 100% | 98.9% | 100% | +---------+------+--------+--------+ | Average | 100% | 98.9% | 100% | +---------+------+--------+--------+
行覆盖率,分支覆盖率,方法覆盖率一目了然,使用还简单,无需做任何代码修改,只需要引用一下,再跑一下.net core global tool就好了!

那你以为这个工具的能力就到此为止了吗?
没有的!
VSCode有个扩展:Coverage Gutters,https://marketplace.visualstudio.com/items?itemName=ryanluker.vscode-coverage-gutters
它支持显示全部的语言的代码覆盖情况,只要你能给它一个 lcov格式的文件。
Coverlet 是支持生成lcov格式的文件的,这样你就可以在跑完测试去看你的代码到底哪些地方没有被覆盖了。
简直是我等屌丝程序员的福音有没有,感谢耶稣大佬,感谢释迦摩尼先生。
3.2 覆盖率报表转换工具 - ReportGenerator
上面的Coverlet配合Coverage Gutters基本可以解决开发过程中98%的代码覆盖问题。
那还有2%呢?
是很多时候我们需要能够更直观看覆盖率的情况,我们需要对的人类更易读的报表。
我们不太可能任何时候都打开VSCode找到Icov文件,再找到源码逐个去看具体代码到底有没有被覆盖。
我们需要一种能够脱离开发环境,脱离源码去查看覆盖率的报表。
最佳的文件格式是什么呢?
当然是HTML!
发送HTML的报告给其他人,告诉他,二货!快,打开你的浏览器,看,我的覆盖率,已经100%!
是100%哦!

但是一想到还不知道有没有工具能够支撑我们装逼的内心,就会对着这个世界,怅然若失,淡淡的开始感叹,人间不值得。
所幸,人间是值得的!!!
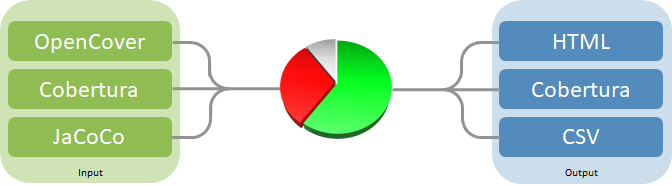
ReportGenerator - https://github.com/danielpalme/ReportGenerator
官方介绍是这么写的!
ReportGenerator converts coverage reports generated by OpenCover, dotCover, Visual Studio, NCover, Cobertura, JaCoCo or Clover into human readable reports in various formats.
The reports do not only show the coverage quota, but also include the source code and visualize which lines have been covered.
ReportGenerator supports merging several reports into one.
恩!给力!
再往下看!!!
竟然提供了.net core global tool。
安装.net core global tool,搞起!!!
dotnet tool install -g dotnet-reportgenerator-globaltool
生成HTML格式的报表!
reportgenerator "-reports:results/coverage/coverage.opencover.xml" "-targetdir:./results/coverage/reports"
浏览器打开生成的index.html文件


现在做工具的都好良心!
操作简单,功能强大,最关键的还不要钱。
感谢耶稣大佬,感谢释迦摩尼先生。
3.3 基准测试工具 - BenchmarkDotNet
但凡喜欢造轮子(我已经潜意识的把我排除在外了:))的都喜欢一个词 - 高性能,为了能够证明自己的轮子性能很赞,出现了各色各样的性能测试工具。
个人推荐 BenchmarkDotNet - https://benchmarkdotnet.org/
这次就不贴官方介绍了,太长了,有兴趣的可以自己去看,英文的!
这里我把官方的说法做一个简单的翻译,大致是这么个意思。
老郭:搞基准测试不简单啊!
老于:咋?您老是搞出啥问题了?
老郭:您看啊,这要考虑咋设计执行迭代次数?
老于:对,是这理儿!
老郭:还要考虑咋做执行预热?
老于:对,是这理儿!
老郭:还要考虑咋样支持不同平台?
老于:对,是这理儿!
老郭:人间不值得啊!
老于:啊? 刚刚人家和尚还说人间是值得的,还感谢耶稣大佬,感谢释迦摩尼先生呢!
老郭:那您?是有好招?
老于:对的,推荐一个小玩意给您得了!
老郭:甭管啥东西?得!放着好用就成,您给我掰哧掰哧!
老于:知道金坷垃么?
老郭:金坷垃?
老于:哦,不?是BenchmarkDotNet!
老郭:那是嘛玩意?
老于:您啊,刚说的那些问题BenchmarkDotNet都能解决!比如说这设计迭代执行次数的问题,人家这库自动帮您选,都不带要您动手的!
老郭:这劲儿劲儿的!
老于:库那边,引用一下,给您的类或方法打几个特性标记一下,代码就搞完了!
老郭:这劲儿劲儿的!
老于:想测试不一样的平台?什么.netfx,.netcore,corert和mono啊,统统支持!
老郭:这劲儿劲儿的!
老于:想测试不一样的处理器架构?x86支持!x64支持!
老郭:这劲儿劲儿的,劲儿劲儿的!
老于:想测试不一样的JIT版本?LegacyJIT支持!RyuJIT支持!
老郭:这倍儿劲儿啊!
老于:GC标记不一样也想测?服务器,工作站都支持!除此以外,还支持各种参数搞出不一样的结果!
老郭:我算是听明白了,是个够劲儿的玩意,那它支持生成啥样的报告呢?
老于:GitHub的文档格式,StackOverflow的文档格式,RPlot,CSV,JSON,XML还有HTML!哎,还有特性我还没说完呢,您这是要干啥去啊!
老郭:我回家开电脑去啊!
老于:这火急火燎的回去下种子?啥片子啊,给我也发一份啊!
老郭:我回家开电脑开VS下BenchmarkDotNet去啊!
在GitHub上,tupac-amaru 组织下有个开源的项目benchmarks: https://github.com/tupac-amaru/benchmarks
这个项目是一个基于BenchmarkDotNet 的一个基准测试项目模板。
包含了一个基准测试项目的脚手架工程。还有准备了可以直接运行的脚本。
面向windows用户的上可用的bat脚本和Docker脚本。
面向Mac/Linux上可用的sh脚本和Docker脚本。
有兴趣的可用去看一下。因为编写基准测试的代码已经有具体的示例项目,网上也有大量的相关博文,这里就不再做详细介绍。
不过网上对很少有解读生成的报告的,在这里我尝试解读一下。
在YACEP的基准测试报告中:https://github.com/tupac-amaru/yacep/tree/_benchmark#atomicvaluestring

上面的报告来自代码:https://github.com/tupac-amaru/yacep/blob/master/tests/TupacAmaru.Yacep.Benchmark/AtomicValue/String.cs
这个代码是用来测试YACEP将表达式中的字符串转换为C#字符串的能力。
字符串和数值是表达式的几大基本数据类型之一,所以YACEP必须要对字符串负责,不能面对字符串表达式硬气不起来,要硬,要有一定的性能。
上面的报告有两部分信息。
第一部分显示的是这个基准测试运行的宿主机配置以及为基准测试配置的参数。
宿主机配置信息:
BenchmarkDotNet=v0.11.5, OS=ubuntu 16.04 Intel Xeon CPU E5-2673 v3 2.40GHz, 1 CPU, 2 logical and 2 physical cores .NET Core SDK=2.2.204 [Host] : .NET Core 2.2.5 (CoreCLR 4.6.27617.05, CoreFX 4.6.27618.01), 64bit RyuJIT
- 所用BenchmarkDotNet的版本是0.11.5
- 操作系统是Ubuntu 16.04
- CPU型号E5-2673 v3 2.40GHz, 1 CPU, 2 logical and 2 physical cores
- 后面一部分是.NET Core的信息
为基准测试配置的参数(官方文档):
Toolchain=InProcessEmitToolchain InvocationCount=8 IterationCount=200 LaunchCount=1 RunStrategy=Throughput UnrollFactor=4 WarmupCount=1
- Toolchain参数,用来配置用于生成,构建和执行具体基准测试工具链的类型。InProcessEmitToolchain参数的意思是用在进程内用emit的方式生成用于做基准测试的对象,而不生成新的可执行文件去独立运行。
- InvocationCount,是指在单次迭代中一个方法的调用次数。该值必须是后面值UnrollFactor的倍数。
- IterationCount,是指在测试过程中迭代的总数。
- LaunchCount,是指需要使用的进程总数。
- RunStrategy,这个参数在这个基准测试中配置其实无意义的,不指定的话,默认值就是Throughput。
- UnrollFactor,是指基准测试的过程中方法在循环中循环执行的次数。
- WarmupCount,是指预热的次数
第二部分是一张表,有六列,各列的意思大致如下:
- Method,代表测试的方法。如果一个基准测试中包含多个测试方法,就可以用来横向比较各个方法的测试结果
- StringLength,这是一个自定义参数(代码)。表示YACEP处理的随机字符串长度。
- Mean,是指方法执行时间的平均值,和后面的中值不一样,{1, 2, 5, 8}的均值是(1+2+5+8)/4=4, {1, 2, 5, 8, 10}的均值是(1+2+5+8+10)/5=5.2
- Error,置信区间。
- StdDev,执行时间的偏差,值越大,偏差越大
- Median,是指方法执行时间的中值,和前面的均值不一样,{1, 2, 5, 8}的中值是中间两个数的均值(2+5)/2=3.5, {1, 2, 5, 8, 10}的中值是中间那个值5
好了,现在来解读一下这个报告的最后一行。
从表达式中将长度为1000的字符串转换C#字符串,YACEP平均处理时间是194.1ns.
注:1秒=1000000000 纳秒,以后谁说C#性能不好,去,锤他!
4. 服务篇
借助于上面的工具,我们已经可以在本地做单元测试,计算覆盖率,拿到更易读的覆盖率报告以及基准测试报告。
但是!这还不够好,我们的代码不可能总是要人去跑测试,要人去执行命令行代码获取覆盖率,要人去跑基准测试再拿具体的报告。
很早很早之前一位来自中国的和尚曾有言:
道求道,佛家求善,儒学求中庸。如是搞IT的,当求懒!
-- 沃·兹基硕德
说的对,搞IT的就是应该求懒!!!

懒???难道意味着啥都不做?
嘿,老板!我,告诉你,作为搞IT的,大佬说要追求懒!
所以,从明天开始,我~决定啥都不做!
面对我~这样一个有追求的程序员,请记得!要多发一倍工资给我!
老板看了看你,径直走到门前,关上门,再慢悠悠的走到窗前,缓缓的拉下百叶窗。
偌大的办公室暗了下来。
整个办公室,除了你,就剩他。
只见他点燃一根烟,靠着沙发坐了下来,若有所思。
沉默着抽完一整支烟。
正欲张口,忽听前台小妹一声尖叫。
心中暗道:莫不是妇产科医院的结果出来了?
欲知后事如何,请看下篇!