Python爬虫-CSDN博客排行榜数据爬取
文章目录
- 前言
- 网络爬虫
-
- 搜索引擎
- 爬虫应用
- 谨防违法
- 爬虫实战
-
- 网页分析
- 编写代码
- 运行效果
- 反爬技术
前言
开始接触 CTF 网络安全比赛发现不会写 Python 脚本的话简直寸步难行……故丢弃 Java 学习下 Python 语言,但单纯学习语法又觉得枯燥……所以从 Python 爬虫应用实战入手进行学习 Python。本文将简述爬虫定义、爬虫基础、反爬技术 和 CSDN博客排行榜数据爬取实战。
网络爬虫
网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,可以代替人们自动地在互联网中进行数据信息的采集与整理。在大数据时代,信息的采集是一项重要的工作,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。

网络爬虫自动化浏览网络中的信息的时候需要按照我们制定的规则进行,这些规则我们称之为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
搜索引擎
搜索引擎离不开爬虫,比如百度搜索引擎的爬虫叫作百度蜘蛛(Baiduspider)。百度蜘蛛每天会在海量的互联网信息中进行爬取,爬取优质信息并收录,当用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序并将结果展现给用户。(除了百度搜索引擎离不开爬虫以外,其他搜索引擎也离不开爬虫,它们也拥有自己的爬虫。比如360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。)
在这个过程中,百度蜘蛛起到了至关重要的作用。那么,如何覆盖互联网中更多的优质网页?又如何筛选这些重复的页面?这些都是由百度蜘蛛爬虫的算法决定的。采用不同的算法,爬虫的运行效率会不同,爬取结果也会有所差异。所以,我们在研究爬虫的时候,不仅要了解爬虫如何实现,还需要知道一些常见爬虫的算法,如果有必要,我们还需要自己去制定相应的算法,在此,我们仅需要对爬虫的概念有一个基本的了解。
爬虫应用

在上面的图中可以看到,网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等。
由于互联网中的用户数据信息,相对来说是比较敏感的数据信息,所以,用户爬虫的利用价值也相对较高。利用用户爬虫可以做大量的事情,比如在2015年,有网友爬取了3000万QQ空间的用户信息,并同样从中获得了大量潜在数据:
- QQ空间用户发说说的时间规律:晚上22点左右,平均发说说的数量是一天中最多的时候;
- QQ空间用户的年龄阶段分布:出生于1990年到1995年的用户相对来说较多;
- QQ空间用户的性别分布:男生占比多于50%,女生占比多于30%,未填性别的占10%左右。
用户爬虫还可以做很多事情,比如爬取淘宝的用户信息,可以分析淘宝用户喜欢什么商品,从而更有利于我们对商品的定位等。由此可见,利用用户爬虫可以获得很多有趣的潜在信息。
谨防违法
网络爬虫在大多数情况中都不违法,我们生活中几乎每天都在爬虫应用(如百度),从目前的情况来看,如果抓取的数据属于个人使用或科研范畴,基本不存在问题;而如果数据属于商业盈利范畴,就有可能属于违法行为。
Robots协议
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。该协议是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应该遵守这项协议。
淘宝网对用户代理为百度爬虫引擎进行了规定,我们可以查看淘宝网的 robots.txt:
- User-agent:
*表示允许所有搜索引擎蜘蛛来爬行抓取,也可以把*去掉,改为特定某一个或者某些搜索引擎蜘蛛来爬行抓取,如百度是Baiduspider,谷歌是Googlebot; - 以 Allow 项的值开头的URL是允许robot访问的。例如,Allow:/article允许百度爬虫引擎访问 /article.htm、/article/12345.com等。
- 以 Disallow 项为开头的链接是不允许百度爬虫引擎访问的。例如,Disallow:/product/ 不允许百度爬虫引擎访问 /product/12345.com 等。
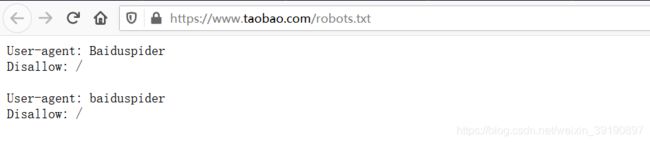 最后一行,
最后一行,Disallow:/ 表示禁止百度爬虫访问除了Allow规定页面外的其他所有页面。百度作为一个搜索引擎,良好地遵守了淘宝网的 robot.txt 协议。
网络爬虫的约束
除了上述Robots协议之外,我们使用网络爬虫的时候还要对自己进行约束:过于快速或者频密的网络爬虫都会对服务器产生巨大的压力,网站可能封锁你的IP,甚至采取进一步的法律行动。因此,你需要约束自己的网络爬虫行为,将请求的速度限定在一个合理的范围之内。简而言之,如果你因为爬取数据导致人家服务器宕机,你就惹祸上身了……
爬虫实战
进入正题之前通过一张图来简要了解下爬虫的工作过程:
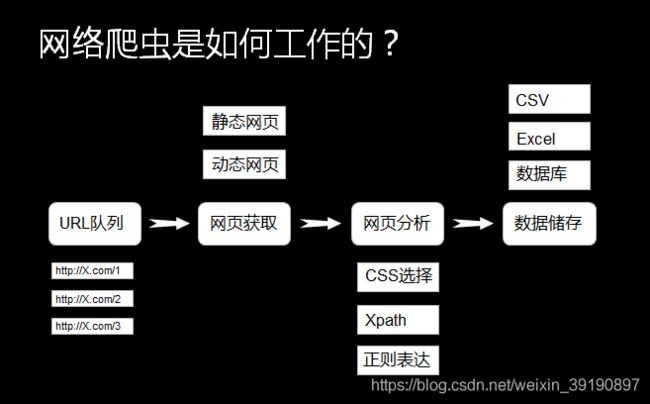
下面将演示如何借助 Python 爬虫爬取CSDN排行榜Top 100的大佬们的数据信息,保存到本地 Excel 文件进行膜拜。
网页分析
访问本次爬取目标——CSDN博客排行榜:https://blog.csdn.net/rank/writing_rank:
抓包分析:
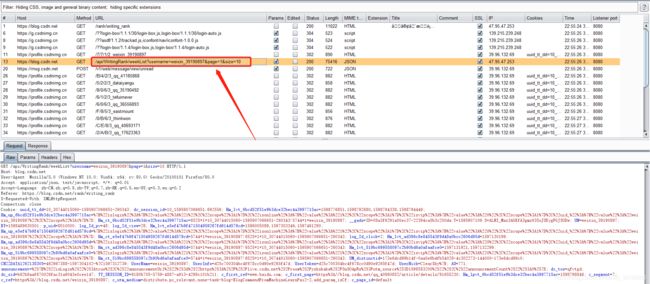
发现返回排行榜用户信息(每次返回一页10位)的API:
/api/WritingRank/weekList?username=weixin_39190897&page=1&size=10
具体数据包如下:
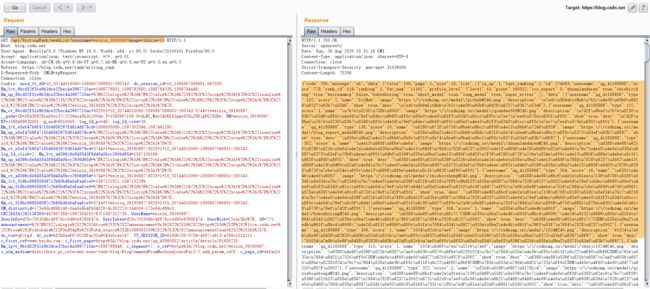
分析一下参数:
url: 从返回的json数据看,显然该请求便是需要爬取的url,而不是最开始给的网址
username: 这个表示你自己的用户id,不带的话就表示没登入 (不带也可以)
page: 表示当前页数,测试发现这个只能显示Top100,也就最大10页
size: 表示每次每页显示的数据量,每次json包里面只包括 10 个大佬的数据
这里面只有page会发生变化,所以我们只要一个循环,不断的去构造这个网址就行了。
编写代码
1、初始化参数:
def __init__(self):
self.ua = UserAgent().chrome
self.url = 'https://blog.csdn.net/api/WritingRank/weekList?' # ajax 请求网址
self.header = {
'Referer': 'https://blog.csdn.net/weixin_39190897',
"Upgrade-Insecure-Requests": "1",
'User-Agent': self.ua
}
# 配置保存表格的基本
self.workbook = Workbook()
self.sheet = self.workbook.active
self.sheet.title = 'CSDNTop100信息'
self.sheet['A1'] = '排名'
self.sheet['B1'] = '用户名'
self.sheet['C1'] = '用户头像'
self.sheet['D1'] = '用户博客网址'
self.sheet['E1'] = '粉丝数'
self.sheet['F1'] = '点赞数'
self.sheet['G1'] = '上周排名'
self.sheet['H1'] = '博客等级'
self.sheet['I1'] = '排名时间'
def __params(self, offset):
self.offset = offset
"""构造请求参数"""
self.params = {
"username": "weixin_39190897",
"page": str(self.offset),
"size": "10"
}
2、爬取网址:
def spider(self):
"""
构造 多页 爬取
"""
for i in range(1, 11):
self.__params(i)
url = self.url + urlencode(self.params)
r = requests.get(url, headers=self.header)
if r.status_code == 200:
r.encoding = r.apparent_encoding
yield r.json()
else:
print('[info] request error ! the status_code is ' + r.status_code)
time.sleep(0.5)
3、分析json包:
def parse_json(self, r_json):
"""
根据网站请求返回的json包 进行进一步分析
"""
# 第一层
first_data = r_json.get('data')
if first_data:
# 第二层
list_data = first_data.get('list')
if list_data: # 判空
for i in list_data:
rank = i.get("ranking")
head_image = i.get('avatar')
user_nickname = i.get('user_nickname') # 用户名
username = i.get('username') # 用户id
fans_num = i.get('fans_num') # 粉丝
fav_num = i.get('fav_num') # 获赞
last_rank = i.get('last_ranking') # 上周排名
leave = i.get('profile_level').get('level') # 博客等级
if rank and head_image and user_nickname and user_nickname and username and fans_num \
and fav_num and last_rank and leave:
# 这里保存数据 只是为了方便转换其他保存格式 仅仅是保存excel中用到列表
yield {
'rank': rank,
'user_nickname': user_nickname,
'head_image': head_image,
'username': 'https://blog.csdn.net/' + username,
'fans_num': fans_num,
'fav_num': fav_num,
'last_rank': last_rank,
'leave': leave
}
4、下载保存excel表格
def down(self, item):
"""保存至excel表格"""
now_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) # 时间
leave_list = []
for value in item.values():
leave_list.append(value)
leave_list.append(now_time)
self.sheet.append(leave_list)
5、完整脚本:
# -*- coding : utf-8 -*-
import requests
from urllib.parse import urlencode
from fake_useragent import UserAgent
import time
from openpyxl import Workbook
class CSDNSpider(object):
"""
爬取csdn top 100 的各种信息
url = 'https://blog.csdn.net/rank/writing_rank'
ajax方式
"""
def __init__(self):
self.ua = UserAgent().chrome
self.url = 'https://blog.csdn.net/api/WritingRank/weekList?' # ajax 请求网址
self.header = {
'Referer': 'https://blog.csdn.net/weixin_39190897',
"Upgrade-Insecure-Requests": "1",
'User-Agent': self.ua
}
# 配置保存表格的基本
self.workbook = Workbook()
self.sheet = self.workbook.active
self.sheet.title = 'CSDNTop100信息'
self.sheet['A1'] = '排名'
self.sheet['B1'] = '用户名'
self.sheet['C1'] = '用户头像'
self.sheet['D1'] = '用户博客网址'
self.sheet['E1'] = '粉丝数'
self.sheet['F1'] = '点赞数'
self.sheet['G1'] = '上周排名'
self.sheet['H1'] = '博客等级'
self.sheet['I1'] = '排名时间'
def __params(self, offset):
self.offset = offset
"""构造请求参数"""
self.params = {
"username": "weixin_39190897",
"page": str(self.offset),
"size": "10"
}
def spider(self):
"""
构造 多页 爬取
"""
for i in range(1, 11):
self.__params(i)
url = self.url + urlencode(self.params)
r = requests.get(url, headers=self.header)
if r.status_code == 200:
r.encoding = r.apparent_encoding
yield r.json()
else:
print('[info] request error ! the status_code is ' + r.status_code)
time.sleep(0.5)
def parse_json(self, r_json):
"""
根据网站请求返回的json包 进行进一步分析
"""
# 第一层
first_data = r_json.get('data')
if first_data:
# 第二层
list_data = first_data.get('list')
if list_data: # 判空
for i in list_data:
rank = i.get("ranking")
head_image = i.get('avatar')
user_nickname = i.get('user_nickname') # 用户名
username = i.get('username') # 用户id
fans_num = i.get('fans_num') # 粉丝
fav_num = i.get('fav_num') # 获赞
last_rank = i.get('last_ranking') # 上周排名
leave = i.get('profile_level').get('level') # 博客等级
if rank and head_image and user_nickname and user_nickname and username and fans_num \
and fav_num and last_rank and leave:
# 这里保存数据 只是为了方便转换其他保存格式 仅仅是保存excel中用到列表
yield {
'rank': rank,
'user_nickname': user_nickname,
'head_image': head_image,
'username': 'https://blog.csdn.net/' + username,
'fans_num': fans_num,
'fav_num': fav_num,
'last_rank': last_rank,
'leave': leave
}
def down(self, item):
"""保存至excel表格"""
now_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
leave_list = []
for value in item.values():
leave_list.append(value)
leave_list.append(now_time)
self.sheet.append(leave_list)
def main(self):
"""调用函数"""
print('The spider is start!')
for content in self.spider():
for item in self.parse_json(content):
self.down(item)
self.workbook.save(filename='CSDNTop100.xlsx')
self.workbook.close()
print('The CSDNTop100 spider is over!')
a = CSDNSpider()
a.main()
此处代码中出现使用了 yield 的函数,属于Python生成器(generator),跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。调用一个生成器函数,返回的是一个迭代器对象。
更多 yield 关键词的理解可参考:python中yield的用法详解——最简单,最清晰的解释。
运行效果
在Pycharm中运行脚本:

脚本运行成功后在项目工程目录下自动生成 CSDNTop100.xlsx 文件:

最后就是见证奇迹的时刻,打开瞅瞅:

反爬技术
1、通过user-agent来控制访问
user-agent 能够使服务器识别出用户的操作系统及版本、cpu类型、浏览器类型和版本。很多网站会设置 user-agent 白名单,只有在白名单范围内的请求才能正常访问。所以在我们的爬虫代码中需要设置 user-agent 伪装成一个浏览器请求。有时候服务器还可能会校验 Referer,所以还可能需要设置 Referer (用来表示此时的请求是从哪个页面链接过来的)。
# 设置请求头信息
headers = {
'Host': 'https://blog.csdn.net',
'Referer': 'https://blog.csdn.net/weixin_43499626/article/details/85875090',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get("http://www.baidu.com", headers=headers)
2、通过IP来限制
当我们用同一个ip多次频繁访问服务器时,服务器会检测到该请求可能是爬虫操作。因此就不能正常的响应页面的信息了。解决办法常用的是使用IP代理池。网上就有很多提供代理的网站。
proxies = {
"http": "http://119.101.125.56",
"https": "http://119.101.125.1",
}
response = requests.get("http://www.baidu.com", proxies=random.choices(proxies))
3、通过前端参数加密
某些网站可能会将参数进行某些加密,或者对参数进行拼接发送给服务器,以此来达到反爬虫的目的。这个时候我们可以试图通过js代码,查看破解的办法。这里就要请出一个大杀器:”PhantomJS“。PhantomJS是一个Python包,他可以在没有图形界面的情况下,完全模拟一个”浏览器“,js脚本验证什么的再也不是问题了。
4、通过robots.txt来限制爬虫
robots.txt是一个限制爬虫的规范,该文件是用来声明哪些东西不能被爬取。如果根目录存在该文件,爬虫就会按照文件的内容来爬取指定的范围。但是这实际上只是一个”君子协议“,遵守与否,都在于爬虫的编写者。