Canal的安装配置及使用
一、Deployer
1.1、配置文件
1.1.1、canal.properties(系统根配置文件)
canal配置主要分为两部分定义:
1.1.1.1、 instance列表定义 (列出当前server上有多少个instance,每个instance的加载方式是spring/manager等)

1.1.1.2、common参数定义,比如可以将instance.properties的公用参数,抽取放置到这里,这样每个instance启动的时候就可以共享. 【instance.properties配置定义优先级高于canal.properties】

1.1.2、conf/spring目录
1.1.2.1、instance.xml配置文件
目前默认支持的instance.xml有以下几种:
spring/memory-instance.xml
spring/file-instance.xml
spring/default-instance.xml
spring/group-instance.xml
memory-instance.xml介绍:
所有的组件(parser , sink , store)都选择了内存版模式,记录位点的都选择了memory模式,重启后又会回到初始位点进行解析
特点:速度最快,依赖最少(不需要zookeeper)
场景:一般应用在quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境
file-instance.xml介绍:
所有的组件(parser , sink , store)都选择了基于file持久化模式,注意,不支持HA机制.
特点:支持单机持久化
场景:生产环境,无HA需求,简单可用.
default-instance.xml介绍:
所有的组件(parser , sink , store)都选择了持久化模式,目前持久化的方式主要是写入zookeeper,保证数据集群共享.
特点:支持HA
场景:生产环境,集群化部署.
group-instance.xml介绍:
主要针对需要进行多库合并时,可以将多个物理instance合并为一个逻辑instance,提供客户端访问。
场景:分库业务。 比如产品数据拆分了4个库,每个库会有一个instance,如果不用group,业务上要消费数据时,需要启动4个客户端,分别链接4个instance实例。使用group后,可以在canal server上合并为一个逻辑instance,只需要启动1个客户端,链接这个逻辑instance即可.
1.1.3、example目录下的配置
1.1.3.1、instance.properties
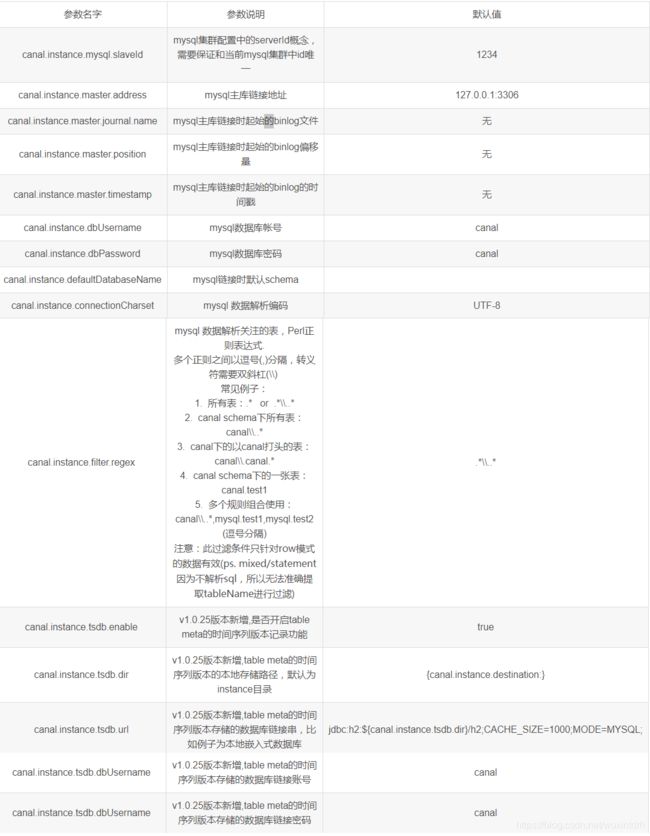
canal.instance.filter.regex
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.* -- 监控test下的t1,t2,t3 test.t.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
mysql链接时的起始位置
-
canal.instance.master.journal.name + canal.instance.master.position : 精确指定一个binlog位点,进行启动
-
canal.instance.master.timestamp : 指定一个时间戳,canal会自动遍历mysql binlog,找到对应时间戳的binlog位点后,进行启动
不指定任何信息:默认从当前数据库的位点,进行启动。(show master status)
mysql解析关注表定义
- 标准的Perl正则,注意转义时需要双斜杠:
\\
mysql链接的编码
- 目前canal版本仅支持一个数据库只有一种编码,如果一个库存在多个编码,需要通过filter.regex配置,将其拆分为多个canal instance,为每个instance指定不同的编码
1.1.3.2、meta.dat
clientId 可以参考:canal/logs/example/meta.log
address:主库ip
port:主库端口
journalName : binlog名称。
position:开始同步的位置
timestamp : 延迟的时间(写0会从journalName开头开始同步)。
destination : 实例名(默认应该和当前目录名一致)
1.1.3.2、h2.mv.db(解析的byte流存储的位置)
二、Adater
2.1、配置文件
2.1.1、 application.yml
canal.conf:
canalServerHost: 127.0.0.1:11111
batchSize: 500
syncBatchSize: 1000
retries: 0
timeout:
mode: tcp # kafka rocketMQ
srcDataSources:
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/mytest?useUnicode=true
username: root
password: 121212
canalAdapters:
- instance: example # canal instance Name or mq topic name, 对应server中配置的canal.destinations = example,即server中的 conf/example目录
groups:
- groupId: g1
outerAdapters:
- name: rdb # 指定为rdb类型同步
key: oracle1 # 指定adapter的唯一key, 与表映射配置中outerAdapterKey对应
properties:
jdbc.driverClassName: oracle.jdbc.OracleDriver # jdbc驱动名, 部分jdbc的jar包需要自行放致lib目录下
jdbc.url: jdbc:oracle:thin:@localhost:49161:XE # jdbc url
jdbc.username: mytest # jdbc username
jdbc.password: m121212 # jdbc password
threads: 5 # 并行执行的线程数, 默认为1
注意点:
- 其中 outAdapter 的配置: name统一为rdb, key为对应的数据源的唯一标识需和下面的表映射文件中的outerAdapterKey对应, properties为目标库jdb的相关参数
- adapter将会自动加载 conf/rdb 下的所有.yml结尾的表映射配置文件
2.1.2、rdb/mytest_user.yml
2.1.2.1、RDB表映射文件
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
destination: example # cannal的instance或者MQ的topic
groupId: # 对应MQ模式下的groupId, 只会同步对应groupId的数据
outerAdapterKey: oracle1 # adapter key, 对应上面配置outAdapters中的key
concurrent: true # 是否按主键hash并行同步, 并行同步的表必须保证主键不会更改及主键不能为其他同步表的外键!!
dbMapping:
database: mytest # 源数据源的database/shcema
table: user # 源数据源表名
targetTable: mytest.tb_user # 目标数据源的库名.表名
targetPk: # 主键映射
id: id # 如果是复合主键可以换行映射多个
# mapAll: true # 是否整表映射, 要求源表和目标表字段名一模一样 (如果targetColumns也配置了映射,则以targetColumns配置为准)
targetColumns: # 字段映射, 格式: 目标表字段: 源表字段, 如果字段名一样源表字段名可不填
id:
name:
role_id:
c_time:
test1:
导入的类型以目标表的元类型为准, 将自动进行类型转换
2.1.2.2、Mysql 库间镜像schema DDL DML同步
修改 application.yml:
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: rdb
key: mysql1
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://192.168.0.36/mytest?useUnicode=true
jdbc.username: root
jdbc.password: 121212
修改 conf/rdb/mytest_user.yml文件:
dataSourceKey: defaultDS
destination: example
outerAdapterKey: mysql1
concurrent: true
dbMapping:
mirrorDb: true
database: mytest
参考:
https://www.updateweb.cn/zwfec/item-303.html
canal的配置详解