Python3 网络爬虫. 4
这一次我们继续来讲一下BeautifulSoup的相关知识,说一下BeautifulSoup导航树的相关内容。
在上一次的博客中我们了解到findAll函数通过标签的名称和属性来查找标签,但有的时候在进网页中的内容爬取时,我们会发现有些我们想要获取的元素并不是都可以通过名称来获得的,因为我们要考虑到有些网站在编写的时候,只有一些需要特殊效果的标签会进行属性值的设置,而有些普通的标签是不会进行属性值的设置的,所以我们会遇到这种情况:当我们想要抓取一些标签中的内容时,我们在对源码进行分析时发现它的标签并没有设置class、type这些容易我们使用findAll函数的值,那我们这个时候如果强行使用findAll,很可能会抓取到很多无用的标签,这会增大我们后期的分析难度,是不可取的,这个时候我们便需要通过其它特性进行标签 的抓取了。我们其实可以通过抓取其它带有特定属性的标签,然后通过这个标签和我们目标标签之间的关系进行转化,然后得到我们想要的标签。这个可以理解为两种解决问题的方法啊,在我们解答数学题的时候经常会用到的,这就是有的问题我们可以通过直接求解进行解答,但有的问题需要通过间接求解然后进行相应的转化才能得到最终的结果,下面我们就来看看导航树给我们带来的一些功能。
顾名思义啊,导航树是一棵树。从我们现实世界中出发,树就是树干和树枝组成,当然作为一个抽象化成一种方法的树,导航树比现实世界中的树的枝和干要多很多,是一棵非常丰满的树,有很多的枝干。导航树就是将HTML页面映射成一棵树,这棵树分别在横向和纵向进行延伸,横向延伸的都是同级的标签,比如说一个ul标签中包含很多的li标签,这些li标签就是同级的;纵向延伸的是不同级的标签,其关系就是父与子的关系,包含与被包含的关系。
下面是豆瓣首页中源码的一个简洁的截图:
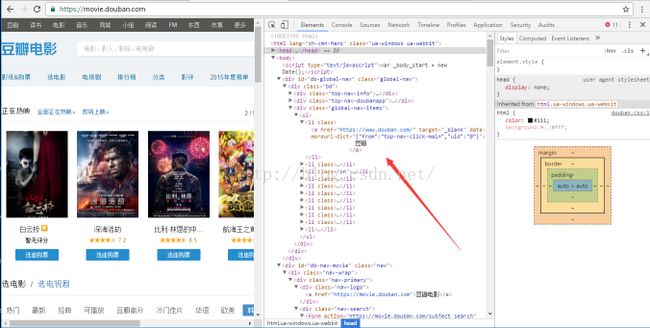
在上图中我们可以看到,body下有子节点div,div下还有div标签组,div下还包含div标签组,之后div包含li标签组。
下面我们就以这个HTML标签结构为例进行解说:
1、处理子标签和其它后代标签
在BeautifulSoup中,孩子标签和后代标签与我们现实社会的人类的家谱是一样的,子标签是一个父标签的下一级,而后代标签是指一个父标签下面所有级别的标签。例如,在我们刚刚选择的源码中,ul是div的子标签,而ul、li和a则都是div标签的后代标签。所有的子标签都是后代标签,但不是所有的后代标签都是子标签。
在BeautifulSoup中,它的函数总是处理当前标签的后代标签,并不会处理其它的标签,正如我们前面的博客中说过的,bsObj.body.div这段代码是会选择body部分的div进行查找,并不会跑到body外面(如head)的区域进行查找的,就像你在学校选定了计科院进行查找一个人的时候,是绝对不会查找别的院的。
比如说我们只想拿到豆瓣中每部电影的那个源码(可以用来后期解析使用),如下图所示,我们想要得到奇异博士这部影片在网页中这个框的区域所有的源码,在右边的源码汇总我们可以看出,这是存放在一个ul中的,可是我们会发现这个ul没有带什么属性,那么我们尝试使用以前的代码试一试。
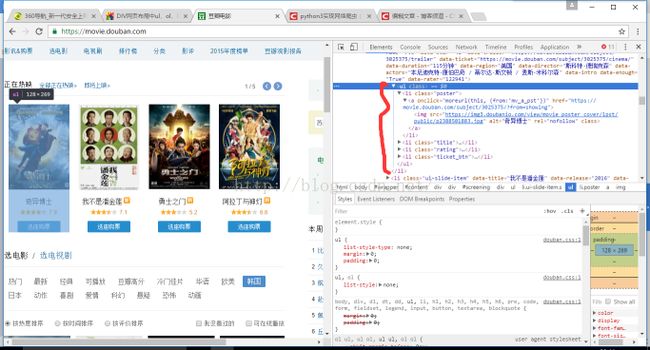
程序如下:
- #coding:utf - 8
- from urllib.request import urlopen
- from bs4 import BeautifulSoup
- html = urlopen(”https://movie.douban.com/”)
- bsObj=BeautifulSoup(html,”lxml”) #将html对象转化为BeautifulSoup对象
- ulList=bsObj.findAll(”ul”) #找到所有ul
- for ul in ulList:
- print(ul)
#coding:utf - 8
from urllib.request import urlopen
from bs4 import BeautifulSouphtml = urlopen(“https://movie.douban.com/“)
bsObj=BeautifulSoup(html,”lxml”) #将html对象转化为BeautifulSoup对象
ulList=bsObj.findAll(“ul”) #找到所有ul
for ul in ulList:
print(ul)程序运行结果如下:
。。。。。。
从上面的结果我们可以发现,不对啊,怎么会有一个ul显示的内容不是我们想要的关于电影的一些信息,这时候我们回到网页的源码中进行查看,会看到如下的ul,是不符合我们的需求的,如下图所示: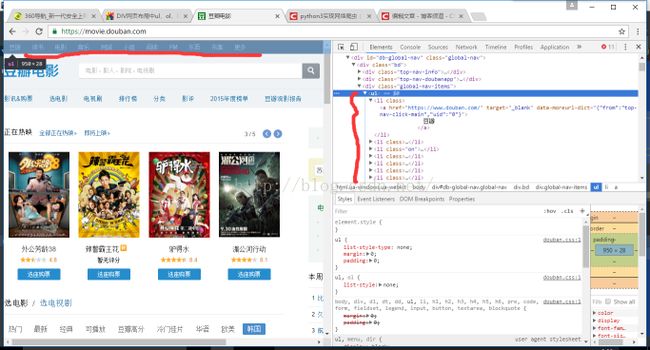
这时我们会发现,有个多余的ul是我们不想要的,其实这种情况在我们以后的爬取过程中会经常发生的,这就需要我们解决了,最好的方法就是在爬取的时候就把这些无用的信息扔掉,而不是在拿到手后进行处理,要做到防范于未然嘛,预防总比治疗来得轻松嘛。
那我们到网页中去看看,有什么可以解决的方法呢,然后我们可以看到ul的父亲节点是有属性的,这就是我们的突破点了,如下图:
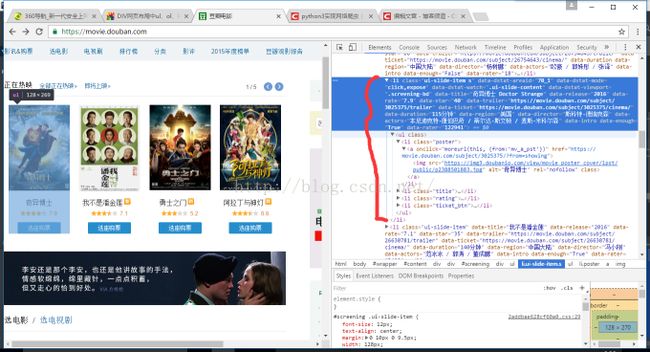
修改后的程序如下
- #coding:utf - 8
- from urllib.request import urlopen
- from bs4 import BeautifulSoup
- html = urlopen(”https://movie.douban.com/”)
- bsObj=BeautifulSoup(html,”lxml”) #将html对象转化为BeautifulSoup对象
- liList=bsObj.findAll(”li”,{“class”:“ui-slide-item”}) #找到所有li
- for li in liList:
- ul=li.children #由于children是个孩子集合,所以下面要迭代进行查看
- for child in ul:
- print(child)
#coding:utf - 8
from urllib.request import urlopen
from bs4 import BeautifulSouphtml = urlopen(“https://movie.douban.com/“)
bsObj=BeautifulSoup(html,”lxml”) #将html对象转化为BeautifulSoup对象
liList=bsObj.findAll(“li”,{“class”:”ui-slide-item”}) #找到所有li
for li in liList:
ul=li.children #由于children是个孩子集合,所以下面要迭代进行查看
for child in ul:
print(child)程序运行如下:

。。。。。。。
这次是不是就不会有多余的了,比较细心的同学有可能会发现在这个网页中这些ul的class并不都是ui-slide-item,有的是”ui-slide-item s”,这个问题可能是网站的显示问题啊,因为在我们抓取到 的网页源码上就不是这样了,当然有兴趣的可以去研究下为什么。
这样我们就拿到了这些电影的整体信息了,那我们要想对它们做分析是不是就很简单了
2、处理兄弟标签
BeautifulSoup可以使用next_siblings()函数处理一些处理相同等级的相同标签,就像我们刚刚拿到的ul中的li标签,满足这一个性质,我们可以通过next_siblings()函数进行处理。
这次我们就处理夺路而逃这个电影中的li,以便于理解:
- #coding:utf - 8
- from urllib.request import urlopen
- from bs4 import BeautifulSoup
- html = urlopen(”https://movie.douban.com/”)
- bsObj=BeautifulSoup(html,”lxml”) #将html对象转化为BeautifulSoup对象
- li=bsObj.find(”li”,{“data-title”:“夺路而逃”}) #找到符合条件的li
- for li1 in li.li.next_siblings:
- print(li1)
#coding:utf - 8
from urllib.request import urlopen
from bs4 import BeautifulSouphtml = urlopen(“https://movie.douban.com/“)
bsObj=BeautifulSoup(html,”lxml”) #将html对象转化为BeautifulSoup对象
li=bsObj.find(“li”,{“data-title”:”夺路而逃”}) #找到符合条件的li
for li1 in li.li.next_siblings:
print(li1)程序运行如下:
夺路而逃
暂无评分
这里我们会发现,咦,一共有四个li标签,为什么少了一个,那是因为一个li标签 不能将自己作为自己的兄弟标签,所以第一条li被跳过了,这里我们只是为了 演示这个next_siblings的用法,当然这个方法对于表格处理是很有效果的,因为 表格的第一行是提示的文字信息,我们在处理 表格数据时是不需要的,那么这个next_siblings就起到作用了。
和next_siblings一样,如果你很容易找到一组兄弟标签的最后一个标签,那么previous_siblings函数也会很有用。与此对应的还有next_sibling和previous_sibling,它们与next_siblings和previous_siblings作用类似,只是它们返回的是单个标签,而不是一组标签。
3、父标签处理
在抓取网页的时候,我们一般想要得到的都是一些子标签,因为父标签一般是为了模块更好的展示进行合并的一种表示方法,只是一个框架,对于我们的用处是不大的,但是有些 时候我们也是可能会用到的,比如说上面在找ul时,我们可以通过带class属性的子标签来得到这个父标签ul,父标签可以为parent和parents。
程序如下图:
- #coding:utf - 8
- from urllib.request import urlopen
- from bs4 import BeautifulSoup
- html = urlopen(”https://movie.douban.com/”)
- bsObj=BeautifulSoup(html,”lxml”) #将html对象转化为BeautifulSoup对象
- liList=bsObj.findAll(”li”,{“class”:“poster”}) #找到所有li
- for li in liList:
- ul=li.parent
- print(ul)
#coding:utf - 8
from urllib.request import urlopen
from bs4 import BeautifulSouphtml = urlopen(“https://movie.douban.com/“)
bsObj=BeautifulSoup(html,”lxml”) #将html对象转化为BeautifulSoup对象
liList=bsObj.findAll(“li”,{“class”:”poster”}) #找到所有li
for li in liList:
ul=li.parent
print(ul)运行结果就不贴了 ,还是一样的。