手动学习深度学习_08
手动学习深度学习_08
- 1.文本分类
-
- 1.1 文本情感分类
- 1.2 文本情感分类数据集
-
- 1.2.1读取数据以及预处理
- 1.3使用循环神经网络进行情感分类
-
- 1.3.1双向循环神经网络
- 1.3.2 加载预训练的词向量
- 1.3.3 评估训练
- 1.4 使用卷积神经网络进行情感分类
-
- 1.4.1 使用卷积神经网络
- 1.4.2 时序最大池化层
- 1.4.3 TextCNN 模型
- 2.数据增强
-
- 2.1图像增广
- 2.2 常用的图像增广方法
-
- 2.2.1 翻转和裁剪
- 2.2.2变化颜色
- 2.2.3 叠加多个图像增广方法
- 3. 模型微调
-
- 3.1 微调
1.文本分类
1.1 文本情感分类
文本分类是自然语言处理的一个常见任务,它把一段不定长的文本序列变换为文本的类别。本节关注它的一个子问题:使用文本情感分类来分析文本作者的情绪。这个问题也叫情感分析,并有着广泛的应用。
同搜索近义词和类比词一样,文本分类也属于词嵌入的下游应用。在本节中,我们将应用预训练的词向量和含多个隐藏层的双向循环神经网络与卷积神经网络,来判断一段不定长的文本序列中包含的是正面还是负面的情绪。后续内容将从以下几个方面展开:
1.文本情感分类数据集
2. 使用循环神经网络进行情感分类
3. 使用卷积神经网络进行情感分类
1.2 文本情感分类数据集
我们使用斯坦福的IMDb数据集(Stanford’s Large Movie Review Dataset)作为文本情感分类的数据集。
1.2.1读取数据以及预处理
数据集文件夹结构:
| aclImdb_v1
| train
| | pos
| | | 0_9.txt
| | | 1_7.txt
| | | ...
| | neg
| | | 0_3.txt
| | | 1_1.txt
| | ...
| test
| | pos
| | neg
| | ...
| ...

预处理数据



1.3使用循环神经网络进行情感分类
1.3.1双向循环神经网络
在“双向循环神经网络”一节中,我们介绍了其模型与前向计算的公式,这里简单回顾一下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8atW5KCG-1582625641743)(attachment:image.png)]
给定输入序列 { X 1 , X 2 , … , X T } \{\boldsymbol{X}_1,\boldsymbol{X}_2,\dots,\boldsymbol{X}_T\} { X1,X2,…,XT},其中 X t ∈ R n × d \boldsymbol{X}_t\in\mathbb{R}^{n\times d} Xt∈Rn×d 为时间步(批量大小为 n n n,输入维度为 d d d)。在双向循环神经网络的架构中,设时间步 t t t 上的正向隐藏状态为 H → t ∈ R n × h \overrightarrow{\boldsymbol{H}}_{t} \in \mathbb{R}^{n \times h} Ht∈Rn×h (正向隐藏状态维度为 h h h),反向隐藏状态为 H ← t ∈ R n × h \overleftarrow{\boldsymbol{H}}_{t} \in \mathbb{R}^{n \times h} Ht∈Rn×h (反向隐藏状态维度为 h h h)。我们可以分别计算正向隐藏状态和反向隐藏状态:
H → t = ϕ ( X t W x h ( f ) + H → t − 1 W h h ( f ) + b h ( f ) ) H ← t = ϕ ( X t W x h ( b ) + H ← t + 1 W h h ( b ) + b h ( b ) ) \begin{aligned} &\overrightarrow{\boldsymbol{H}}_{t}=\phi\left(\boldsymbol{X}_{t} \boldsymbol{W}_{x h}^{(f)}+\overrightarrow{\boldsymbol{H}}_{t-1} \boldsymbol{W}_{h h}^{(f)}+\boldsymbol{b}_{h}^{(f)}\right)\\ &\overleftarrow{\boldsymbol{H}}_{t}=\phi\left(\boldsymbol{X}_{t} \boldsymbol{W}_{x h}^{(b)}+\overleftarrow{\boldsymbol{H}}_{t+1} \boldsymbol{W}_{h h}^{(b)}+\boldsymbol{b}_{h}^{(b)}\right) \end{aligned} Ht=ϕ(XtWxh(f)+Ht−1Whh(f)+bh(f))Ht=ϕ(XtWxh(b)+Ht+1Whh(b)+bh(b))
其中权重 W x h ( f ) ∈ R d × h , W h h ( f ) ∈ R h × h , W x h ( b ) ∈ R d × h , W h h ( b ) ∈ R h × h \boldsymbol{W}_{x h}^{(f)} \in \mathbb{R}^{d \times h}, \boldsymbol{W}_{h h}^{(f)} \in \mathbb{R}^{h \times h}, \boldsymbol{W}_{x h}^{(b)} \in \mathbb{R}^{d \times h}, \boldsymbol{W}_{h h}^{(b)} \in \mathbb{R}^{h \times h} Wxh(f)∈Rd×h,Whh(f)∈Rh×h,Wxh(b)∈Rd×h,Whh(b)∈Rh×h 和偏差 b h ( f ) ∈ R 1 × h , b h ( b ) ∈ R 1 × h \boldsymbol{b}_{h}^{(f)} \in \mathbb{R}^{1 \times h}, \boldsymbol{b}_{h}^{(b)} \in \mathbb{R}^{1 \times h} bh(f)∈R1×h,bh(b)∈R1×h 均为模型参数, ϕ \phi ϕ 为隐藏层激活函数。
然后我们连结两个方向的隐藏状态 H → t \overrightarrow{\boldsymbol{H}}_{t} Ht 和 H ← t \overleftarrow{\boldsymbol{H}}_{t} Ht 来得到隐藏状态 H t ∈ R n × 2 h \boldsymbol{H}_{t} \in \mathbb{R}^{n \times 2 h} Ht∈Rn×2h,并将其输入到输出层。输出层计算输出 O t ∈ R n × q \boldsymbol{O}_{t} \in \mathbb{R}^{n \times q} Ot∈Rn×q(输出维度为 q q q):
O t = H t W h q + b q \boldsymbol{O}_{t}=\boldsymbol{H}_{t} \boldsymbol{W}_{h q}+\boldsymbol{b}_{q} Ot=HtWhq+bq
其中权重 W h q ∈ R 2 h × q \boldsymbol{W}_{h q} \in \mathbb{R}^{2 h \times q} Whq∈R2h×q 和偏差 b q ∈ R 1 × q \boldsymbol{b}_{q} \in \mathbb{R}^{1 \times q} bq∈R1×q 为输出层的模型参数。不同方向上的隐藏单元维度也可以不同。
利用 torch.nn.RNN 或 torch.nn.LSTM 模组,我们可以很方便地实现双向循环神经网络,下面是以 LSTM 为例的代码。

1.3.2 加载预训练的词向量
由于预训练词向量的词典及词语索引与我们使用的数据集并不相同,所以需要根据目前的词典及索引的顺序来加载预训练词向量。

1.3.3 评估训练


1.4 使用卷积神经网络进行情感分类
1.4.1 使用卷积神经网络
一维卷积层
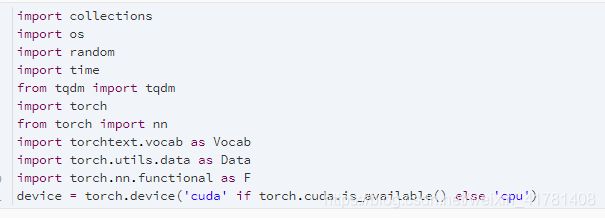
在介绍模型前我们先来解释一维卷积层的工作原理。与二维卷积层一样,一维卷积层使用一维的互相关运算。在一维互相关运算中,卷积窗口从输入数组的最左方开始,按从左往右的顺序,依次在输入数组上滑动。当卷积窗口滑动到某一位置时,窗口中的输入子数组与核数组按元素相乘并求和,得到输出数组中相应位置的元素。如图所示,输入是一个宽为 7 的一维数组,核数组的宽为 2。可以看到输出的宽度为 7−2+1=6,且第一个元素是由输入的最左边的宽为 2 的子数组与核数组按元素相乘后再相加得到的:0×1+1×2=2。

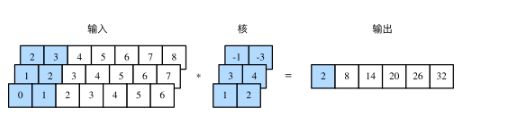
多输入通道的一维互相关运算也与多输入通道的二维互相关运算类似:在每个通道上,将核与相应的输入做一维互相关运算,并将通道之间的结果相加得到输出结果。下图展示了含 3 个输入通道的一维互相关运算,其中阴影部分为第一个输出元素及其计算所使用的输入和核数组元素:0×1+1×2+1×3+2×4+2×(−1)+3×(−3)=2。

多输入通道的一维互相关运算也与多输入通道的二维互相关运算类似:在每个通道上,将核与相应的输入做一维互相关运算,并将通道之间的结果相加得到输出结果。下图展示了含 3 个输入通道的一维互相关运算,其中阴影部分为第一个输出元素及其计算所使用的输入和核数组元素:0×1+1×2+1×3+2×4+2×(−1)+3×(−3)=2。

1.4.2 时序最大池化层
类似地,我们有一维池化层。TextCNN 中使用的时序最大池化(max-over-time pooling)层实际上对应一维全局最大池化层:假设输入包含多个通道,各通道由不同时间步上的数值组成,各通道的输出即该通道所有时间步中最大的数值。因此,时序最大池化层的输入在各个通道上的时间步数可以不同。

注:自然语言中还有一些其他的池化操作,可参考这篇博文。
为提升计算性能,我们常常将不同长度的时序样本组成一个小批量,并通过在较短序列后附加特殊字符(如0)令批量中各时序样本长度相同。这些人为添加的特殊字符当然是无意义的。由于时序最大池化的主要目的是抓取时序中最重要的特征,它通常能使模型不受人为添加字符的影响。

1.4.3 TextCNN 模型
TextCNN 模型主要使用了一维卷积层和时序最大池化层。假设输入的文本序列由 n n n 个词组成,每个词用 d d d 维的词向量表示。那么输入样本的宽为 n n n,输入通道数为 d d d。TextCNN 的计算主要分为以下几步。
- 定义多个一维卷积核,并使用这些卷积核对输入分别做卷积计算。宽度不同的卷积核可能会捕捉到不同个数的相邻词的相关性。
- 对输出的所有通道分别做时序最大池化,再将这些通道的池化输出值连结为向量。
- 通过全连接层将连结后的向量变换为有关各类别的输出。这一步可以使用丢弃层应对过拟合。
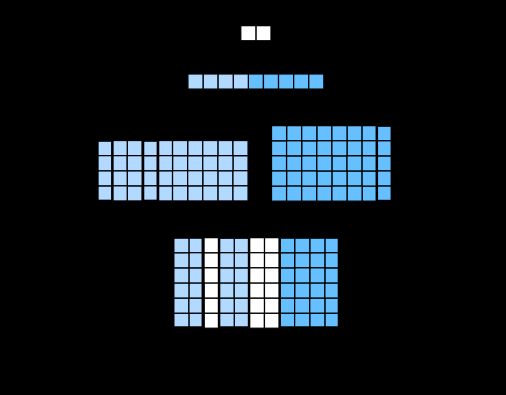
下图用一个例子解释了 TextCNN 的设计。这里的输入是一个有 11 个词的句子,每个词用 6 维词向量表示。因此输入序列的宽为 11,输入通道数为 6。给定 2 个一维卷积核,核宽分别为 2 和 4,输出通道数分别设为 4 和 5。因此,一维卷积计算后,4 个输出通道的宽为 11−2+1=10,而其他 5 个通道的宽为 11−4+1=8。尽管每个通道的宽不同,我们依然可以对各个通道做时序最大池化,并将 9 个通道的池化输出连结成一个 9 维向量。最终,使用全连接将 9 维向量变换为 2 维输出,即正面情感和负面情感的预测。
下面我们来实现 TextCNN 模型。与上一节相比,除了用一维卷积层替换循环神经网络外,这里我们还使用了两个嵌入层,一个的权重固定,另一个则参与训练。
class TextCNN(nn.Module):
def __init__(self, vocab, embed_size, kernel_sizes, num_channels):
'''
@params:
vocab: 在数据集上创建的词典,用于获取词典大小
embed_size: 嵌入维度大小
kernel_sizes: 卷积核大小列表
num_channels: 卷积通道数列表
'''
super(TextCNN, self).__init__()
self.embedding = nn.Embedding(len(vocab), embed_size) # 参与训练的嵌入层
self.constant_embedding = nn.Embedding(len(vocab), embed_size) # 不参与训练的嵌入层
self.pool = GlobalMaxPool1d() # 时序最大池化层没有权重,所以可以共用一个实例
self.convs = nn.ModuleList() # 创建多个一维卷积层
for c, k in zip(num_channels, kernel_sizes):
self.convs.append(nn.Conv1d(in_channels = 2*embed_size,
out_channels = c,
kernel_size = k))
self.decoder = nn.Linear(sum(num_channels), 2)
self.dropout = nn.Dropout(0.5) # 丢弃层用于防止过拟合
def forward(self, inputs):
'''
@params:
inputs: 词语下标序列,形状为 (batch_size, seq_len) 的整数张量
@return:
outputs: 对文本情感的预测,形状为 (batch_size, 2) 的张量
'''
embeddings = torch.cat((
self.embedding(inputs),
self.constant_embedding(inputs)), dim=2) # (batch_size, seq_len, 2*embed_size)
# 根据一维卷积层要求的输入格式,需要将张量进行转置
embeddings = embeddings.permute(0, 2, 1) # (batch_size, 2*embed_size, seq_len)
encoding = torch.cat([
self.pool(F.relu(conv(embeddings))).squeeze(-1) for conv in self.convs], dim=1)
# encoding = []
# for conv in self.convs:
# out = conv(embeddings) # (batch_size, out_channels, seq_len-kernel_size+1)
# out = self.pool(F.relu(out)) # (batch_size, out_channels, 1)
# encoding.append(out.squeeze(-1)) # (batch_size, out_channels)
# encoding = torch.cat(encoding) # (batch_size, out_channels_sum)
# 应用丢弃法后使用全连接层得到输出
outputs = self.decoder(self.dropout(encoding))
return outputs
embed_size, kernel_sizes, nums_channels = 100, [3, 4, 5], [100, 100, 100]
net = TextCNN(vocab, embed_size, kernel_sizes, nums_channels)

2.数据增强
2.1图像增广
(深度卷积神经网络)里提到过,大规模数据集是成功应用深度神经网络的前提。图像增广(image augmentation)技术通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。图像增广的另一种解释是,随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。例如,我们可以对图像进行不同方式的裁剪,使感兴趣的物体出现在不同位置,从而减轻模型对物体出现位置的依赖性。我们也可以调整亮度、色彩等因素来降低模型对色彩的敏感度。可以说,在当年AlexNet的成功中,图像增广技术功不可没。本节我们将讨论这个在计算机视觉里被广泛使用的技术。
2.2 常用的图像增广方法

2.2.1 翻转和裁剪
左右翻转图像通常不改变物体的类别。它是最早也是最广泛使用的一种图像增广方法。通过torchvision.transforms模块创建RandomHorizontalFlip实例来实现一半概率的图像水平(左右)翻转。
2.2.2变化颜色
另一类增广方法是变化颜色。我们可以从4个方面改变图像的颜色:亮度(brightness)、对比度(contrast)、饱和度(saturation)和色调(hue)。我们将图像的亮度随机变化为原图亮度的 50 % 50\% 50%( 1 − 0.5 1-0.5 1−0.5) ∼ 150 % \sim 150\% ∼150%( 1 + 0.5 1+0.5 1+0.5)。
torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0)
2.2.3 叠加多个图像增广方法
torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), color_aug, shape_aug])
3. 模型微调
3.1 微调
在前面的一些章节中,我们介绍了如何在只有6万张图像的Fashion-MNIST训练数据集上训练模型。我们还描述了学术界当下使用最广泛的大规模图像数据集ImageNet,它有超过1,000万的图像和1,000类的物体。然而,我们平常接触到数据集的规模通常在这两者之间。
假设我们想从图像中识别出不同种类的椅子,然后将购买链接推荐给用户。一种可能的方法是先找出100种常见的椅子,为每种椅子拍摄1,000张不同角度的图像,然后在收集到的图像数据集上训练一个分类模型。这个椅子数据集虽然可能比Fashion-MNIST数据集要庞大,但样本数仍然不及ImageNet数据集中样本数的十分之一。这可能会导致适用于ImageNet数据集的复杂模型在这个椅子数据集上过拟合。同时,因为数据量有限,最终训练得到的模型的精度也可能达不到实用的要求。
为了应对上述问题,一个显而易见的解决办法是收集更多的数据。然而,收集和标注数据会花费大量的时间和资金。例如,为了收集ImageNet数据集,研究人员花费了数百万美元的研究经费。虽然目前的数据采集成本已降低了不少,但其成本仍然不可忽略。
另外一种解决办法是应用迁移学习(transfer learning),将从源数据集学到的知识迁移到目标数据集上。例如,虽然ImageNet数据集的图像大多跟椅子无关,但在该数据集上训练的模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等。这些类似的特征对于识别椅子也可能同样有效。
本节我们介绍迁移学习中的一种常用技术:微调(fine tuning)。如图9.1所示,微调由以下4步构成。
- 在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
- 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
- 在目标数据集(如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。

当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
参考:https://www.boyuai.com/elites/course/cZu18YmweLv10OeV/video/M-SX8DlhttiRtwzbYZ87-