noip 2009 提高组初赛订正
文章目录
- 单项选择题
- 多项选择题
- 数学题
- 看程序写结果
- 总结
单项选择题
7、最优前缀编码,也称Huffman编码。这种编码组合的特点是对于较频繁使用的元素给与较短的唯一编码,以提高通讯的效率。下面编码组合哪一组不是合法的前缀编码。
A)(00,01,10,11)
B)(0,1,00,11)
C)(0,10,110,111)
D)(1,01,000,001)
前缀编码分为定长和不定长,定长的只要两两不同即可,而不定长需要任意一个编码不是另一个的前缀,所以B错,0是00的前缀。
p.s.具体实现最优不定长编码的算法就是合并果子,找出哈夫曼树,然后每个叶子就是字符,树边是编码中的字符,所以所有叶子到根的带权路径长的和即编码长度
多项选择题
1、关于CPU下面哪些说法是正确的:
A)CPU全称为中央处理器(或中央处理单元)。
B)CPU能直接运行机器语言。
C)CPU最早是由Intel公司发明的。
D)同样主频下,32位的CPU比16位的CPU运行速度快一倍。
C. intel发明第一款微处理器,按理说就是4位CPU,但答案没有选
D. 同一时间处理二进制数位数叫字长, 2 32 2^{32} 232比 2 16 2^{16} 216快 2 16 2^{16} 216倍。
ans = AB
2、关于计算机内存下面的说法哪些是正确的:
A)随机存储器(RAM)的意思是当程序运行时,每次具体分配给程序的内存位置是随机而不确定的。
B)一般的个人计算机在同一时刻只能存/取一个特定的内存单元。
C)计算机内存严格说来包括主存(memory)、高速缓存(cache)和寄存器(register)三个部分。
D)1MB内存通常是指1024*1024字节大小的内存。
A. RAM是与CPU直接交换数据的内部存储器,也叫主存(内存),它可以随时读写,而且速度很快,通常作为操作系统或其他正在运行中的程序的临时数据存储媒介。所谓“随机存取”,指的是当存储器中的数据被读取或写入时,所需要的时间与这段信息所在的位置或所写入的位置无关。
B. 查不到,就是对。。。
∴ \therefore ∴ ans = BD
3、关于操作系统下面说法哪些是正确的:
A.多任务操作系统专用于多核心或多个CPU架构的计算机系统的管理。
B.在操作系统的管理下,一个完整的程序在运行过程中可以被部分存放在内存中。
C.分时系统让多个用户可以共享一台主机的运算能力,为保证每个用户都得到及时的响应通常会采用时间片轮转调度的策略。
D.为了方便上层应用程序的开发,操作系统都是免费开源的。
A. 普通PC都是多任务
B. 记结论
ans = BC
4、关于计算机网络,下面的说法哪些是正确的:
A)网络协议之所以有很多层主要是由于新技术需要兼容过去老的实现方案。
B)新一代互联网使用的IPv6标准是IPv5标准的升级与补充。
C)TCP/IP是互联网的基础协议簇,包含有TCP和IP等网络与传输层的通讯协议。
D)互联网上每一台入网主机通常都需要使用一个唯一的IP地址,否则就必须注册一个固定的域名来标明其地址。
A. 网络有分层模型,结构还未改变
C. TCP->传输层,IP->网络层,反一反更准确
ans = C
5、关于HTML下面哪些说法是正确的:
A)HTML全称超文本标记语言,实现了文本、图形、声音乃至视频信息的统一编码。
B)HTML不单包含有网页内容信息的描述,同时也包含对网页格式信息的定义。
C)网页上的超链接只能指向外部的网络资源,本网站网页间的联系通过设置标签来实现。
D)点击网页上的超链接从本质上就是按照该链接所隐含的统一资源定位符(URL)请求网络资源或网络服务。
A. HTML分为head和body,head规定显示,body是正文。因为没有统一编码,所以有强大的可拓展性
C. 超链接可以链接自身网站或网页
ans = BD
6、若3个顶点的无权图G的邻接矩阵用数组存储为{{0,1,1},{1,0,1},{0,1,0}},假定在具体存储中顶点依次为: v1,v2,v3。关于该图,下面的说法哪些是正确的:
A)该图是有向图。
B)该图是强连通的。
C)该图所有顶点的入度之和减所有顶点的出度之和等于1。
D)从v1开始的深度优先遍历所经过的顶点序列与广度优先的顶点序列是相同的。
邻接矩阵为:
| 0 | 1 | 1 |
|---|---|---|
| 1 | 0 | 1 |
| 0 | 1 | 0 |
不对称所以肯定是有向图(少数可以确定答案的多选题。。。)
ans = ABD
7、在带尾指针(链表指针clist指向尾结点)的非空循环单链表中每个结点都以next字段的指针指向下一个节点。假定其中已经有2个以上的结点。下面哪些说法是正确的:
A)如果p指向一个待插入的新结点,在头部插入一个元素的语句序列为:
p->next = clist->next; clist->next = p;
B)如果p指向一个待插入的新结点,在尾部插入一个元素的语句序列为:
p->next = clist;clist->next = p;
C)在头部删除一个结点的语句序列为:
p = clist->next; clist->next = clist->next->next; delete p;
D)在尾部删除一个结点的语句序列为。
p = clist; clist = clist ->next; delete p;
BD. 对于单链表貌似做不到(考试的时候觉得烦就跳过了,没想到最后没时间补)
ans = AC
8、散列表的地址区间为0-10,散列函数为H(K)=K mod 11。采用开地址法的线性探查法处理冲突,并将关键字序列26,25,72,38,8,18,59存储到散列表中,这些元素存入散列表的顺序并不确定。假定之前散列表为空,则元素59存放在散列表中的可能地址有:
A) 5 B) 7 C) 9 D) 10
| 26 | 25 | 72 | 38 | 8 | 18 | 59 |
|---|---|---|---|---|---|---|
| 4 | 3 | 6 | 5 | 8 | 7 | 4 |
因为可以冲突,59可以存的地址有4,5,6,7,8,9。思博了明明算出来了,A没有选。
ans = ABC
9、排序算法是稳定的意思是关键码相同的记录排序前后相对位置不发生改变,下列哪些排序算法是稳定的:
A) 插入排序 B) 基数排序 C) 归并排序 D) 冒泡排序
ans = ABCD 水
10、在参加NOI系列竞赛过程中,下面哪些行为是被严格禁止的:
A)携带书写工具,手表和不具有通讯功能的电子词典进入赛场。
B)在联机测试中通过手工计算出可能的答案并在程序里直接输出答案来获取分数。
C)通过互联网搜索取得解题思路。
D)在提交的程序中启动多个进程以提高程序的执行效率。
A. 只允许书带写工具,其他的只有衣服和手表了
ans = ACD
数学题
1.拓扑排序是指将有向无环图G中的所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若
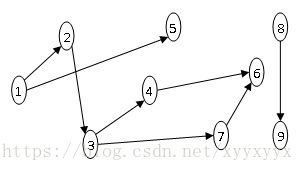
眼瞎,总共有9个点。。。
右边的DAG只有一个拓扑序。
左边的DAG可以拆成一个“根”1,和5,和(2,3,4,7,6),后者长得很好看,只有两个拓扑序,再把5插进去,拓扑序2*6=12。
最后 C 9 7 ∗ 12 C 2 2 ∗ 1 = 432 C_{9}^{7}*12C_2^2*1=432 C97∗12C22∗1=432
2.某个国家的钱币面值有1, 7, 7 2 7^2 72, 7 3 7^3 73共计四种,如果要用现金付清10015元的货物,假设买卖双方各种钱币的数量无限且允许找零,那么交易过程中至少需要流通( )张钱币。
这题因为钱的币值比较特殊,所以可以贪心,大的可以尽量选。如果不是的话就会比较难算了。答案35
看程序写结果
#include solution
一道纯模拟,来啊,互相伤害啊
读入:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| a | 0 | 0 | 0 | 0 |
| b | 2 | 3 | 5 | 7 |
i = 0, j = 0:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| a | 2 | 0 | 0 | 0 |
| b | 2 | 3 | 7 | 7 |
i =1, j = 0:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| a | 2 | 2 | 0 | 0 |
| b | 2 | 3 | 9 | 7 |
从这一步就开始错,悲剧。。。
i = 1, j = 1:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| a | 2 | 5 | 0 | 0 |
| b | 2 | 8 | 9 | 7 |
i = 2,j = 0:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| a | 2 | 5 | 2 | 0 |
| b | 2 | 8 | 11 | 7 |
i = 2, j = 1:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| a | 2 | 5 | 10 | 0 |
| b | 2 | 8 | 16 | 7 |
第二次爆炸错在这里。。。
i = 2, j = 2:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| a | 2 | 5 | 26 | 0 |
| b | 2 | 8 | 42 | 7 |
快要结束了。。。
i = 3, j = 0:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| a | 2 | 5 | 26 | 2 |
| b | 2 | 8 | 44 | 7 |
i = 3, j = 1:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| a | 2 | 5 | 26 | 10 |
| b | 2 | 8 | 49 | 7 |
i = 3, j = 2:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| a | 2 | 5 | 26 | 59 |
| b | 2 | 8 | 49 | 33 |
i = 3, j = 3:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| a | 2 | 5 | 26 | 92 |
| b | 94 | 8 | 49 | 33 |
a n s = ( 2 + 4 ) ∗ ( 5 + 8 ) ∗ ( 6 + 9 ) ∗ ( 2 + 3 ) = 5850 ans=(2+4)*(5+8)*(6+9)*(2+3)=5850 ans=(2+4)∗(5+8)∗(6+9)∗(2+3)=5850
知道答案的情况下重复算了三遍才算对,还是借助markdown打了这么多表格的,考试的时候一遍算对的几率几乎为0。
所以考试的时候要是遇到这种没有目的的思博纯模拟,一定不能珍惜草稿纸,打完一页表格再打一页!再带一个修正带,一把尺子,像上面的表格一样一个一个列,一个一个检查,8分丢不起哇!
总结
All in all,这次比赛做的不是很好,只有70左右。
原因嘛,主要是:
- 时间不够,检查和模拟都没有充裕的时间
- 数学题不够仔细,全错是不应该的
至于好的方面:
- 选择题还可以,这年的选择记忆的东西太多了,但是该拿的分都拿了。
- 程序填空全对,一定要保持每一场都这样。
之后的目标,做好数学题!加快速度!